 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLMs Reading the Rhythms of Daily Life: Aligned Understanding for Behavior Prediction and Generation
Apr 26, 2026Human daily behavior unfolds as complex sequences shaped by intentions, preferences, and context. Effectively modeling these behaviors is crucial for intelligent systems such as personal assistants and recommendation engines. While recent advances in deep learning and behavior pre-training have improved behavior prediction, key challenges remain--particularly in handling long-tail behaviors, enhancing interpretability, and supporting multiple tasks within a unified framework. Large language models (LLMs) offer a promising direction due to their semantic richness, strong interpretability, and generative capabilities. However, the structural and modal differences between behavioral data and natural language limit the direct applicability of LLMs. To address this gap, we propose Behavior Understanding Alignment (BUA), a novel framework that integrates LLMs into human behavior modeling through a structured curriculum learning process. BUA employs sequence embeddings from pretrained behavior models as alignment anchors and guides the LLM through a three-stage curriculum, while a multi-round dialogue setting introduces prediction and generation capabilities. Experiments on two real-world datasets demonstrate that BUA significantly outperforms existing methods in both tasks, highlighting its effectiveness and flexibility in applying LLMs to complex human behavior modeling.
AgentSociety: Large-Scale Simulation of LLM-Driven Generative Agents Advances Understanding of Human Behaviors and Society
Feb 12, 2025



Understanding human behavior and society is a central focus in social sciences, with the rise of generative social science marking a significant paradigmatic shift. By leveraging bottom-up simulations, it replaces costly and logistically challenging traditional experiments with scalable, replicable, and systematic computational approaches for studying complex social dynamics. Recent advances in large language models (LLMs) have further transformed this research paradigm, enabling the creation of human-like generative social agents and realistic simulacra of society. In this paper, we propose AgentSociety, a large-scale social simulator that integrates LLM-driven agents, a realistic societal environment, and a powerful large-scale simulation engine. Based on the proposed simulator, we generate social lives for over 10k agents, simulating their 5 million interactions both among agents and between agents and their environment. Furthermore, we explore the potential of AgentSociety as a testbed for computational social experiments, focusing on four key social issues: polarization, the spread of inflammatory messages, the effects of universal basic income policies, and the impact of external shocks such as hurricanes. These four issues serve as valuable cases for assessing AgentSociety's support for typical research methods -- such as surveys, interviews, and interventions -- as well as for investigating the patterns, causes, and underlying mechanisms of social issues. The alignment between AgentSociety's outcomes and real-world experimental results not only demonstrates its ability to capture human behaviors and their underlying mechanisms, but also underscores its potential as an important platform for social scientists and policymakers.
Understanding World or Predicting Future? A Comprehensive Survey of World Models
Nov 21, 2024



The concept of world models has garnered significant attention due to advancements in multimodal large language models such as GPT-4 and video generation models such as Sora, which are central to the pursuit of artificial general intelligence. This survey offers a comprehensive review of the literature on world models. Generally, world models are regarded as tools for either understanding the present state of the world or predicting its future dynamics. This review presents a systematic categorization of world models, emphasizing two primary functions: (1) constructing internal representations to understand the mechanisms of the world, and (2) predicting future states to simulate and guide decision-making. Initially, we examine the current progress in these two categories. We then explore the application of world models in key domains, including autonomous driving, robotics, and social simulacra, with a focus on how each domain utilizes these aspects. Finally, we outline key challenges and provide insights into potential future research directions.
Modeling User Fatigue for Sequential Recommendation
May 22, 2024



Recommender systems filter out information that meets user interests. However, users may be tired of the recommendations that are too similar to the content they have been exposed to in a short historical period, which is the so-called user fatigue. Despite the significance for a better user experience, user fatigue is seldom explored by existing recommenders. In fact, there are three main challenges to be addressed for modeling user fatigue, including what features support it, how it influences user interests, and how its explicit signals are obtained. In this paper, we propose to model user Fatigue in interest learning for sequential Recommendations (FRec). To address the first challenge, based on a multi-interest framework, we connect the target item with historical items and construct an interest-aware similarity matrix as features to support fatigue modeling. Regarding the second challenge, built upon feature cross, we propose a fatigue-enhanced multi-interest fusion to capture long-term interest. In addition, we develop a fatigue-gated recurrent unit for short-term interest learning, with temporal fatigue representations as important inputs for constructing update and reset gates. For the last challenge, we propose a novel sequence augmentation to obtain explicit fatigue signals for contrastive learning. We conduct extensive experiments on real-world datasets, including two public datasets and one large-scale industrial dataset. Experimental results show that FRec can improve AUC and GAUC up to 0.026 and 0.019 compared with state-of-the-art models, respectively. Moreover, large-scale online experiments demonstrate the effectiveness of FRec for fatigue reduction. Our codes are released at https://github.com/tsinghua-fib-lab/SIGIR24-FRec.
Neighborhood Attention Transformer with Progressive Channel Fusion for Speaker Verification
May 20, 2024Transformer-based architectures for speaker verification typically require more training data than ECAPA-TDNN. Therefore, recent work has generally been trained on VoxCeleb1&2. We propose a backbone network based on self-attention, which can achieve competitive results when trained on VoxCeleb2 alone. The network alternates between neighborhood attention and global attention to capture local and global features, then aggregates features of different hierarchical levels, and finally performs attentive statistical pooling. Additionally, we employ a progressive channel fusion strategy to expand the receptive field in the channel dimension as the network deepens. We trained the proposed PCF-NAT model on VoxCeleb2 and evaluated it on VoxCeleb1 and the validation sets of VoxSRC. The EER and minDCF of the shallow PCF-NAT are on average more than 20% lower than those of similarly sized ECAPA-TDNN. Deep PCF-NAT achieves an EER lower than 0.5% on VoxCeleb1-O.
Uncovering the Deep Filter Bubble: Narrow Exposure in Short-Video Recommendation
Mar 07, 2024



Filter bubbles have been studied extensively within the context of online content platforms due to their potential to cause undesirable outcomes such as user dissatisfaction or polarization. With the rise of short-video platforms, the filter bubble has been given extra attention because these platforms rely on an unprecedented use of the recommender system to provide relevant content. In our work, we investigate the deep filter bubble, which refers to the user being exposed to narrow content within their broad interests. We accomplish this using one-year interaction data from a top short-video platform in China, which includes hierarchical data with three levels of categories for each video. We formalize our definition of a "deep" filter bubble within this context, and then explore various correlations within the data: first understanding the evolution of the deep filter bubble over time, and later revealing some of the factors that give rise to this phenomenon, such as specific categories, user demographics, and feedback type. We observe that while the overall proportion of users in a filter bubble remains largely constant over time, the depth composition of their filter bubble changes. In addition, we find that some demographic groups that have a higher likelihood of seeing narrower content and implicit feedback signals can lead to less bubble formation. Finally, we propose some ways in which recommender systems can be designed to reduce the risk of a user getting caught in a bubble.
Large Language Model-driven Meta-structure Discovery in Heterogeneous Information Network
Feb 18, 2024



Heterogeneous information networks (HIN) have gained increasing popularity for being able to capture complex relations between nodes of diverse types. Meta-structure was proposed to identify important patterns of relations on HIN, which has been proven effective for extracting rich semantic information and facilitating graph neural networks to learn expressive representations. However, hand-crafted meta-structures pose challenges for scaling up, which draws wide research attention for developing automatic meta-structure search algorithms. Previous efforts concentrate on searching for meta-structures with good empirical prediction performance, overlooking explainability. Thus, they often produce meta-structures prone to overfitting and incomprehensible to humans. To address this, we draw inspiration from the emergent reasoning abilities of large language models (LLMs). We propose a novel REasoning meta-STRUCTure search (ReStruct) framework that integrates LLM reasoning into the evolutionary procedure. ReStruct uses a grammar translator to encode meta-structures into natural language sentences, and leverages the reasoning power of LLMs to evaluate semantically feasible meta-structures. ReStruct also employs performance-oriented evolutionary operations. These two competing forces jointly optimize for semantic explainability and empirical performance of meta-structures. We also design a differential LLM explainer that can produce natural language explanations for the discovered meta-structures, and refine the explanation by reasoning through the search history. Experiments on five datasets demonstrate ReStruct achieve SOTA performance in node classification and link recommendation tasks. Additionally, a survey study involving 73 graduate students shows that the meta-structures and natural language explanations generated by ReStruct are substantially more comprehensible.
Large Language Models Empowered Agent-based Modeling and Simulation: A Survey and Perspectives
Dec 19, 2023



Agent-based modeling and simulation has evolved as a powerful tool for modeling complex systems, offering insights into emergent behaviors and interactions among diverse agents. Integrating large language models into agent-based modeling and simulation presents a promising avenue for enhancing simulation capabilities. This paper surveys the landscape of utilizing large language models in agent-based modeling and simulation, examining their challenges and promising future directions. In this survey, since this is an interdisciplinary field, we first introduce the background of agent-based modeling and simulation and large language model-empowered agents. We then discuss the motivation for applying large language models to agent-based simulation and systematically analyze the challenges in environment perception, human alignment, action generation, and evaluation. Most importantly, we provide a comprehensive overview of the recent works of large language model-empowered agent-based modeling and simulation in multiple scenarios, which can be divided into four domains: cyber, physical, social, and hybrid, covering simulation of both real-world and virtual environments. Finally, since this area is new and quickly evolving, we discuss the open problems and promising future directions.
Large Language Model-Empowered Agents for Simulating Macroeconomic Activities
Oct 16, 2023
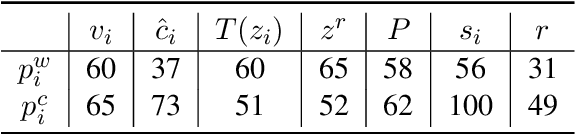

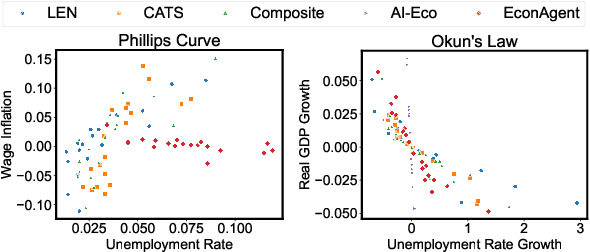
The advent of the Web has brought about a paradigm shift in traditional economics, particularly in the digital economy era, enabling the precise recording and analysis of individual economic behavior. This has led to a growing emphasis on data-driven modeling in macroeconomics. In macroeconomic research, Agent-based modeling (ABM) emerged as an alternative, evolving through rule-based agents, machine learning-enhanced decision-making, and, more recently, advanced AI agents. However, the existing works are suffering from three main challenges when endowing agents with human-like decision-making, including agent heterogeneity, the influence of macroeconomic trends, and multifaceted economic factors. Large language models (LLMs) have recently gained prominence in offering autonomous human-like characteristics. Therefore, leveraging LLMs in macroeconomic simulation presents an opportunity to overcome traditional limitations. In this work, we take an early step in introducing a novel approach that leverages LLMs in macroeconomic simulation. We design prompt-engineering-driven LLM agents to exhibit human-like decision-making and adaptability in the economic environment, with the abilities of perception, reflection, and decision-making to address the abovementioned challenges. Simulation experiments on macroeconomic activities show that LLM-empowered agents can make realistic work and consumption decisions and emerge more reasonable macroeconomic phenomena than existing rule-based or AI agents. Our work demonstrates the promising potential to simulate macroeconomics based on LLM and its human-like characteristics.
Alleviating Video-Length Effect for Micro-video Recommendation
Aug 31, 2023



Micro-videos platforms such as TikTok are extremely popular nowadays. One important feature is that users no longer select interested videos from a set, instead they either watch the recommended video or skip to the next one. As a result, the time length of users' watching behavior becomes the most important signal for identifying preferences. However, our empirical data analysis has shown a video-length effect that long videos are easier to receive a higher value of average view time, thus adopting such view-time labels for measuring user preferences can easily induce a biased model that favors the longer videos. In this paper, we propose a Video Length Debiasing Recommendation (VLDRec) method to alleviate such an effect for micro-video recommendation. VLDRec designs the data labeling approach and the sample generation module that better capture user preferences in a view-time oriented manner. It further leverages the multi-task learning technique to jointly optimize the above samples with original biased ones. Extensive experiments show that VLDRec can improve the users' view time by 1.81% and 11.32% on two real-world datasets, given a recommendation list of a fixed overall video length, compared with the best baseline method. Moreover, VLDRec is also more effective in matching users' interests in terms of the video content.