 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGPT-IMAGE-EDIT-1.5M: A Million-Scale, GPT-Generated Image Dataset
Jul 28, 2025
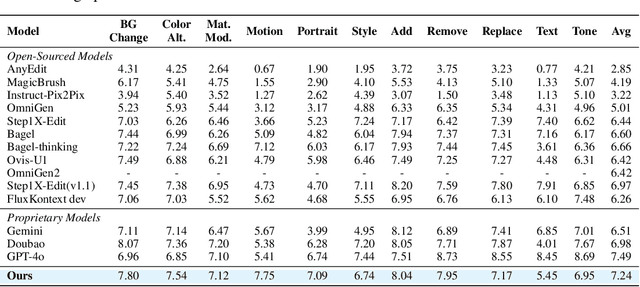

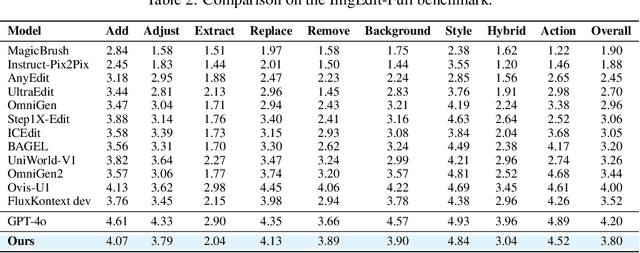
Recent advancements in large multimodal models like GPT-4o have set a new standard for high-fidelity, instruction-guided image editing. However, the proprietary nature of these models and their training data creates a significant barrier for open-source research. To bridge this gap, we introduce GPT-IMAGE-EDIT-1.5M, a publicly available, large-scale image-editing corpus containing more than 1.5 million high-quality triplets (instruction, source image, edited image). We systematically construct this dataset by leveraging the versatile capabilities of GPT-4o to unify and refine three popular image-editing datasets: OmniEdit, HQ-Edit, and UltraEdit. Specifically, our methodology involves 1) regenerating output images to enhance visual quality and instruction alignment, and 2) selectively rewriting prompts to improve semantic clarity. To validate the efficacy of our dataset, we fine-tune advanced open-source models on GPT-IMAGE-EDIT-1.5M. The empirical results are exciting, e.g., the fine-tuned FluxKontext achieves highly competitive performance across a comprehensive suite of benchmarks, including 7.24 on GEdit-EN, 3.80 on ImgEdit-Full, and 8.78 on Complex-Edit, showing stronger instruction following and higher perceptual quality while maintaining identity. These scores markedly exceed all previously published open-source methods and substantially narrow the gap to leading proprietary models. We hope the full release of GPT-IMAGE-EDIT-1.5M can help to catalyze further open research in instruction-guided image editing.
LLM-based HSE Compliance Assessment: Benchmark, Performance, and Advancements
May 29, 2025Health, Safety, and Environment (HSE) compliance assessment demands dynamic real-time decision-making under complicated regulations and complex human-machine-environment interactions. While large language models (LLMs) hold significant potential for decision intelligence and contextual dialogue, their capacity for domain-specific knowledge in HSE and structured legal reasoning remains underexplored. We introduce HSE-Bench, the first benchmark dataset designed to evaluate the HSE compliance assessment capabilities of LLM. HSE-Bench comprises over 1,000 manually curated questions drawn from regulations, court cases, safety exams, and fieldwork videos, and integrates a reasoning flow based on Issue spotting, rule Recall, rule Application, and rule Conclusion (IRAC) to assess the holistic reasoning pipeline. We conduct extensive evaluations on different prompting strategies and more than 10 LLMs, including foundation models, reasoning models and multimodal vision models. The results show that, although current LLMs achieve good performance, their capabilities largely rely on semantic matching rather than principled reasoning grounded in the underlying HSE compliance context. Moreover, their native reasoning trace lacks the systematic legal reasoning required for rigorous HSE compliance assessment. To alleviate these, we propose a new prompting technique, Reasoning of Expert (RoE), which guides LLMs to simulate the reasoning process of different experts for compliance assessment and reach a more accurate unified decision. We hope our study highlights reasoning gaps in LLMs for HSE compliance and inspires further research on related tasks.
Hydra: Structured Cross-Source Enhanced Large Language Model Reasoning
May 23, 2025Retrieval-augmented generation (RAG) enhances large language models (LLMs) by incorporating external knowledge. Current hybrid RAG system retrieves evidence from both knowledge graphs (KGs) and text documents to support LLM reasoning. However, it faces challenges like handling multi-hop reasoning, multi-entity questions, multi-source verification, and effective graph utilization. To address these limitations, we present Hydra, a training-free framework that unifies graph topology, document semantics, and source reliability to support deep, faithful reasoning in LLMs. Hydra handles multi-hop and multi-entity problems through agent-driven exploration that combines structured and unstructured retrieval, increasing both diversity and precision of evidence. To tackle multi-source verification, Hydra uses a tri-factor cross-source verification (source trustworthiness assessment, cross-source corroboration, and entity-path alignment), to balance topic relevance with cross-modal agreement. By leveraging graph structure, Hydra fuses heterogeneous sources, guides efficient exploration, and prunes noise early. Comprehensive experiments on seven benchmark datasets show that Hydra achieves overall state-of-the-art results on all benchmarks with GPT-3.5, outperforming the strong hybrid baseline ToG-2 by an average of 20.3% and up to 30.1%. Furthermore, Hydra enables smaller models (e.g., Llama-3.1-8B) to achieve reasoning performance comparable to that of GPT-4-Turbo.
M-learner:A Flexible And Powerful Framework To Study Heterogeneous Treatment Effect In Mediation Model
May 23, 2025We propose a novel method, termed the M-learner, for estimating heterogeneous indirect and total treatment effects and identifying relevant subgroups within a mediation framework. The procedure comprises four key steps. First, we compute individual-level conditional average indirect/total treatment effect Second, we construct a distance matrix based on pairwise differences. Third, we apply tSNE to project this matrix into a low-dimensional Euclidean space, followed by K-means clustering to identify subgroup structures. Finally, we calibrate and refine the clusters using a threshold-based procedure to determine the optimal configuration. To the best of our knowledge, this is the first approach specifically designed to capture treatment effect heterogeneity in the presence of mediation. Experimental results validate the robustness and effectiveness of the proposed framework. Application to the real-world Jobs II dataset highlights the broad adaptability and potential applicability of our method.Code is available at https: //anonymous.4open.science/r/M-learner-C4BB.
TelePlanNet: An AI-Driven Framework for Efficient Telecom Network Planning
May 20, 2025The selection of base station sites is a critical challenge in 5G network planning, which requires efficient optimization of coverage, cost, user satisfaction, and practical constraints. Traditional manual methods, reliant on human expertise, suffer from inefficiencies and are limited to an unsatisfied planning-construction consistency. Existing AI tools, despite improving efficiency in certain aspects, still struggle to meet the dynamic network conditions and multi-objective needs of telecom operators' networks. To address these challenges, we propose TelePlanNet, an AI-driven framework tailored for the selection of base station sites, integrating a three-layer architecture for efficient planning and large-scale automation. By leveraging large language models (LLMs) for real-time user input processing and intent alignment with base station planning, combined with training the planning model using the improved group relative policy optimization (GRPO) reinforcement learning, the proposed TelePlanNet can effectively address multi-objective optimization, evaluates candidate sites, and delivers practical solutions. Experiments results show that the proposed TelePlanNet can improve the consistency to 78%, which is superior to the manual methods, providing telecom operators with an efficient and scalable tool that significantly advances cellular network planning.
CompleteMe: Reference-based Human Image Completion
Apr 28, 2025Recent methods for human image completion can reconstruct plausible body shapes but often fail to preserve unique details, such as specific clothing patterns or distinctive accessories, without explicit reference images. Even state-of-the-art reference-based inpainting approaches struggle to accurately capture and integrate fine-grained details from reference images. To address this limitation, we propose CompleteMe, a novel reference-based human image completion framework. CompleteMe employs a dual U-Net architecture combined with a Region-focused Attention (RFA) Block, which explicitly guides the model's attention toward relevant regions in reference images. This approach effectively captures fine details and ensures accurate semantic correspondence, significantly improving the fidelity and consistency of completed images. Additionally, we introduce a challenging benchmark specifically designed for evaluating reference-based human image completion tasks. Extensive experiments demonstrate that our proposed method achieves superior visual quality and semantic consistency compared to existing techniques. Project page: https://liagm.github.io/CompleteMe/
Enhancing Facial Privacy Protection via Weakening Diffusion Purification
Mar 13, 2025The rapid growth of social media has led to the widespread sharing of individual portrait images, which pose serious privacy risks due to the capabilities of automatic face recognition (AFR) systems for mass surveillance. Hence, protecting facial privacy against unauthorized AFR systems is essential. Inspired by the generation capability of the emerging diffusion models, recent methods employ diffusion models to generate adversarial face images for privacy protection. However, they suffer from the diffusion purification effect, leading to a low protection success rate (PSR). In this paper, we first propose learning unconditional embeddings to increase the learning capacity for adversarial modifications and then use them to guide the modification of the adversarial latent code to weaken the diffusion purification effect. Moreover, we integrate an identity-preserving structure to maintain structural consistency between the original and generated images, allowing human observers to recognize the generated image as having the same identity as the original. Extensive experiments conducted on two public datasets, i.e., CelebA-HQ and LADN, demonstrate the superiority of our approach. The protected faces generated by our method outperform those produced by existing facial privacy protection approaches in terms of transferability and natural appearance.
ObjectMover: Generative Object Movement with Video Prior
Mar 11, 2025Simple as it seems, moving an object to another location within an image is, in fact, a challenging image-editing task that requires re-harmonizing the lighting, adjusting the pose based on perspective, accurately filling occluded regions, and ensuring coherent synchronization of shadows and reflections while maintaining the object identity. In this paper, we present ObjectMover, a generative model that can perform object movement in highly challenging scenes. Our key insight is that we model this task as a sequence-to-sequence problem and fine-tune a video generation model to leverage its knowledge of consistent object generation across video frames. We show that with this approach, our model is able to adjust to complex real-world scenarios, handling extreme lighting harmonization and object effect movement. As large-scale data for object movement are unavailable, we construct a data generation pipeline using a modern game engine to synthesize high-quality data pairs. We further propose a multi-task learning strategy that enables training on real-world video data to improve the model generalization. Through extensive experiments, we demonstrate that ObjectMover achieves outstanding results and adapts well to real-world scenarios.
Fusion of Various Optimization Based Feature Smoothing Methods for Wearable and Non-invasive Blood Glucose Estimation
Mar 06, 2025



Recently, the wearable and non-invasive blood glucose estimation approach has been proposed. However, due to the unreliability of the acquisition device, the presence of the noise and the variations of the acquisition environments, the obtained features and the reference blood glucose values are highly unreliable. To address this issue, this paper proposes a polynomial fitting approach to smooth the obtained features or the reference blood glucose values. First, the blood glucose values are estimated based on the individual optimization approaches. Second, the absolute difference values between the estimated blood glucose values and the actual blood glucose values based on each optimization approach are computed. Third, these absolute difference values for each optimization approach are sorted in the ascending order. Fourth, for each sorted blood glucose value, the optimization method corresponding to the minimum absolute difference value is selected. Fifth, the accumulate probability of each selected optimization method is computed. If the accumulate probability of any selected optimization method at a point is greater than a threshold value, then the accumulate probabilities of these three selected optimization methods at that point are reset to zero. A range of the sorted blood glucose values are defined as that with the corresponding boundaries points being the previous reset point and this reset point. Hence, after performing the above procedures for all the sorted reference blood glucose values in the validation set, the regions of the sorted reference blood glucose values and the corresponding optimization methods in these regions are determined. The computer numerical simulation results show that our proposed method yields the mean absolute relative deviation (MARD) at 0.0930 and the percentage of the test data falling in the zone A of the Clarke error grid at 94.1176%.
* This version corrects several typos
Benchmarking Multimodal RAG through a Chart-based Document Question-Answering Generation Framework
Feb 20, 2025Multimodal Retrieval-Augmented Generation (MRAG) enhances reasoning capabilities by integrating external knowledge. However, existing benchmarks primarily focus on simple image-text interactions, overlooking complex visual formats like charts that are prevalent in real-world applications. In this work, we introduce a novel task, Chart-based MRAG, to address this limitation. To semi-automatically generate high-quality evaluation samples, we propose CHARt-based document question-answering GEneration (CHARGE), a framework that produces evaluation data through structured keypoint extraction, crossmodal verification, and keypoint-based generation. By combining CHARGE with expert validation, we construct Chart-MRAG Bench, a comprehensive benchmark for chart-based MRAG evaluation, featuring 4,738 question-answering pairs across 8 domains from real-world documents. Our evaluation reveals three critical limitations in current approaches: (1) unified multimodal embedding retrieval methods struggles in chart-based scenarios, (2) even with ground-truth retrieval, state-of-the-art MLLMs achieve only 58.19% Correctness and 73.87% Coverage scores, and (3) MLLMs demonstrate consistent text-over-visual modality bias during Chart-based MRAG reasoning. The CHARGE and Chart-MRAG Bench are released at https://github.com/Nomothings/CHARGE.git.