 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Makes for Text to 360-degree Panorama Generation with Stable Diffusion?
May 28, 2025Recent prosperity of text-to-image diffusion models, e.g. Stable Diffusion, has stimulated research to adapt them to 360-degree panorama generation. Prior work has demonstrated the feasibility of using conventional low-rank adaptation techniques on pre-trained diffusion models to generate panoramic images. However, the substantial domain gap between perspective and panoramic images raises questions about the underlying mechanisms enabling this empirical success. We hypothesize and examine that the trainable counterparts exhibit distinct behaviors when fine-tuned on panoramic data, and such an adaptation conceals some intrinsic mechanism to leverage the prior knowledge within the pre-trained diffusion models. Our analysis reveals the following: 1) the query and key matrices in the attention modules are responsible for common information that can be shared between the panoramic and perspective domains, thus are less relevant to panorama generation; and 2) the value and output weight matrices specialize in adapting pre-trained knowledge to the panoramic domain, playing a more critical role during fine-tuning for panorama generation. We empirically verify these insights by introducing a simple framework called UniPano, with the objective of establishing an elegant baseline for future research. UniPano not only outperforms existing methods but also significantly reduces memory usage and training time compared to prior dual-branch approaches, making it scalable for end-to-end panorama generation with higher resolution. The code will be released.
Omni-Perception: Omnidirectional Collision Avoidance for Legged Locomotion in Dynamic Environments
May 25, 2025Agile locomotion in complex 3D environments requires robust spatial awareness to safely avoid diverse obstacles such as aerial clutter, uneven terrain, and dynamic agents. Depth-based perception approaches often struggle with sensor noise, lighting variability, computational overhead from intermediate representations (e.g., elevation maps), and difficulties with non-planar obstacles, limiting performance in unstructured environments. In contrast, direct integration of LiDAR sensing into end-to-end learning for legged locomotion remains underexplored. We propose Omni-Perception, an end-to-end locomotion policy that achieves 3D spatial awareness and omnidirectional collision avoidance by directly processing raw LiDAR point clouds. At its core is PD-RiskNet (Proximal-Distal Risk-Aware Hierarchical Network), a novel perception module that interprets spatio-temporal LiDAR data for environmental risk assessment. To facilitate efficient policy learning, we develop a high-fidelity LiDAR simulation toolkit with realistic noise modeling and fast raycasting, compatible with platforms such as Isaac Gym, Genesis, and MuJoCo, enabling scalable training and effective sim-to-real transfer. Learning reactive control policies directly from raw LiDAR data enables the robot to navigate complex environments with static and dynamic obstacles more robustly than approaches relying on intermediate maps or limited sensing. We validate Omni-Perception through real-world experiments and extensive simulation, demonstrating strong omnidirectional avoidance capabilities and superior locomotion performance in highly dynamic environments. We will open-source our code and models.
TextFlux: An OCR-Free DiT Model for High-Fidelity Multilingual Scene Text Synthesis
May 23, 2025



Diffusion-based scene text synthesis has progressed rapidly, yet existing methods commonly rely on additional visual conditioning modules and require large-scale annotated data to support multilingual generation. In this work, we revisit the necessity of complex auxiliary modules and further explore an approach that simultaneously ensures glyph accuracy and achieves high-fidelity scene integration, by leveraging diffusion models' inherent capabilities for contextual reasoning. To this end, we introduce TextFlux, a DiT-based framework that enables multilingual scene text synthesis. The advantages of TextFlux can be summarized as follows: (1) OCR-free model architecture. TextFlux eliminates the need for OCR encoders (additional visual conditioning modules) that are specifically used to extract visual text-related features. (2) Strong multilingual scalability. TextFlux is effective in low-resource multilingual settings, and achieves strong performance in newly added languages with fewer than 1,000 samples. (3) Streamlined training setup. TextFlux is trained with only 1% of the training data required by competing methods. (4) Controllable multi-line text generation. TextFlux offers flexible multi-line synthesis with precise line-level control, outperforming methods restricted to single-line or rigid layouts. Extensive experiments and visualizations demonstrate that TextFlux outperforms previous methods in both qualitative and quantitative evaluations.
Fact-R1: Towards Explainable Video Misinformation Detection with Deep Reasoning
May 22, 2025The rapid spread of multimodal misinformation on social media has raised growing concerns, while research on video misinformation detection remains limited due to the lack of large-scale, diverse datasets. Existing methods often overfit to rigid templates and lack deep reasoning over deceptive content. To address these challenges, we introduce FakeVV, a large-scale benchmark comprising over 100,000 video-text pairs with fine-grained, interpretable annotations. In addition, we further propose Fact-R1, a novel framework that integrates deep reasoning with collaborative rule-based reinforcement learning. Fact-R1 is trained through a three-stage process: (1) misinformation long-Chain-of-Thought (CoT) instruction tuning, (2) preference alignment via Direct Preference Optimization (DPO), and (3) Group Relative Policy Optimization (GRPO) using a novel verifiable reward function. This enables Fact-R1 to exhibit emergent reasoning behaviors comparable to those observed in advanced text-based reinforcement learning systems, but in the more complex multimodal misinformation setting. Our work establishes a new paradigm for misinformation detection, bridging large-scale video understanding, reasoning-guided alignment, and interpretable verification.
SciCUEval: A Comprehensive Dataset for Evaluating Scientific Context Understanding in Large Language Models
May 21, 2025


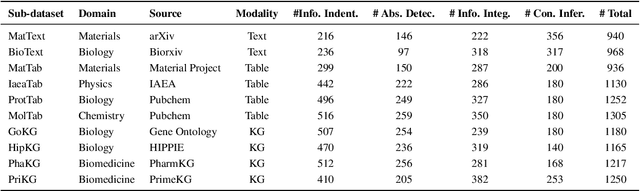
Large Language Models (LLMs) have shown impressive capabilities in contextual understanding and reasoning. However, evaluating their performance across diverse scientific domains remains underexplored, as existing benchmarks primarily focus on general domains and fail to capture the intricate complexity of scientific data. To bridge this gap, we construct SciCUEval, a comprehensive benchmark dataset tailored to assess the scientific context understanding capability of LLMs. It comprises ten domain-specific sub-datasets spanning biology, chemistry, physics, biomedicine, and materials science, integrating diverse data modalities including structured tables, knowledge graphs, and unstructured texts. SciCUEval systematically evaluates four core competencies: Relevant information identification, Information-absence detection, Multi-source information integration, and Context-aware inference, through a variety of question formats. We conduct extensive evaluations of state-of-the-art LLMs on SciCUEval, providing a fine-grained analysis of their strengths and limitations in scientific context understanding, and offering valuable insights for the future development of scientific-domain LLMs.
Self-cross Feature based Spiking Neural Networks for Efficient Few-shot Learning
May 15, 2025



Deep neural networks (DNNs) excel in computer vision tasks, especially, few-shot learning (FSL), which is increasingly important for generalizing from limited examples. However, DNNs are computationally expensive with scalability issues in real world. Spiking Neural Networks (SNNs), with their event-driven nature and low energy consumption, are particularly efficient in processing sparse and dynamic data, though they still encounter difficulties in capturing complex spatiotemporal features and performing accurate cross-class comparisons. To further enhance the performance and efficiency of SNNs in few-shot learning, we propose a few-shot learning framework based on SNNs, which combines a self-feature extractor module and a cross-feature contrastive module to refine feature representation and reduce power consumption. We apply the combination of temporal efficient training loss and InfoNCE loss to optimize the temporal dynamics of spike trains and enhance the discriminative power. Experimental results show that the proposed FSL-SNN significantly improves the classification performance on the neuromorphic dataset N-Omniglot, and also achieves competitive performance to ANNs on static datasets such as CUB and miniImageNet with low power consumption.
Fine-Grained Bias Exploration and Mitigation for Group-Robust Classification
May 11, 2025Achieving group-robust generalization in the presence of spurious correlations remains a significant challenge, particularly when bias annotations are unavailable. Recent studies on Class-Conditional Distribution Balancing (CCDB) reveal that spurious correlations often stem from mismatches between the class-conditional and marginal distributions of bias attributes. They achieve promising results by addressing this issue through simple distribution matching in a bias-agnostic manner. However, CCDB approximates each distribution using a single Gaussian, which is overly simplistic and rarely holds in real-world applications. To address this limitation, we propose a novel method called Bias Exploration via Overfitting (BEO), which captures each distribution in greater detail by modeling it as a mixture of latent groups. Building on these group-level descriptions, we introduce a fine-grained variant of CCDB, termed FG-CCDB, which performs more precise distribution matching and balancing within each group. Through group-level reweighting, FG-CCDB learns sample weights from a global perspective, achieving stronger mitigation of spurious correlations without incurring substantial storage or computational costs. Extensive experiments demonstrate that BEO serves as a strong proxy for ground-truth bias annotations and can be seamlessly integrated with bias-supervised methods. Moreover, when combined with FG-CCDB, our method performs on par with bias-supervised approaches on binary classification tasks and significantly outperforms them in highly biased multi-class scenarios.
Occupancy World Model for Robots
May 07, 2025Understanding and forecasting the scene evolutions deeply affect the exploration and decision of embodied agents. While traditional methods simulate scene evolutions through trajectory prediction of potential instances, current works use the occupancy world model as a generative framework for describing fine-grained overall scene dynamics. However, existing methods cluster on the outdoor structured road scenes, while ignoring the exploration of forecasting 3D occupancy scene evolutions for robots in indoor scenes. In this work, we explore a new framework for learning the scene evolutions of observed fine-grained occupancy and propose an occupancy world model based on the combined spatio-temporal receptive field and guided autoregressive transformer to forecast the scene evolutions, called RoboOccWorld. We propose the Conditional Causal State Attention (CCSA), which utilizes camera poses of next state as conditions to guide the autoregressive transformer to adapt and understand the indoor robotics scenarios. In order to effectively exploit the spatio-temporal cues from historical observations, Hybrid Spatio-Temporal Aggregation (HSTA) is proposed to obtain the combined spatio-temporal receptive field based on multi-scale spatio-temporal windows. In addition, we restructure the OccWorld-ScanNet benchmark based on local annotations to facilitate the evaluation of the indoor 3D occupancy scene evolution prediction task. Experimental results demonstrate that our RoboOccWorld outperforms state-of-the-art methods in indoor 3D occupancy scene evolution prediction task. The code will be released soon.
Deterministic-to-Stochastic Diverse Latent Feature Mapping for Human Motion Synthesis
May 02, 2025Human motion synthesis aims to generate plausible human motion sequences, which has raised widespread attention in computer animation. Recent score-based generative models (SGMs) have demonstrated impressive results on this task. However, their training process involves complex curvature trajectories, leading to unstable training process. In this paper, we propose a Deterministic-to-Stochastic Diverse Latent Feature Mapping (DSDFM) method for human motion synthesis. DSDFM consists of two stages. The first human motion reconstruction stage aims to learn the latent space distribution of human motions. The second diverse motion generation stage aims to build connections between the Gaussian distribution and the latent space distribution of human motions, thereby enhancing the diversity and accuracy of the generated human motions. This stage is achieved by the designed deterministic feature mapping procedure with DerODE and stochastic diverse output generation procedure with DivSDE.DSDFM is easy to train compared to previous SGMs-based methods and can enhance diversity without introducing additional training parameters.Through qualitative and quantitative experiments, DSDFM achieves state-of-the-art results surpassing the latest methods, validating its superiority in human motion synthesis.
Class-Conditional Distribution Balancing for Group Robust Classification
Apr 24, 2025Spurious correlations that lead models to correct predictions for the wrong reasons pose a critical challenge for robust real-world generalization. Existing research attributes this issue to group imbalance and addresses it by maximizing group-balanced or worst-group accuracy, which heavily relies on expensive bias annotations. A compromise approach involves predicting bias information using extensively pretrained foundation models, which requires large-scale data and becomes impractical for resource-limited rare domains. To address these challenges, we offer a novel perspective by reframing the spurious correlations as imbalances or mismatches in class-conditional distributions, and propose a simple yet effective robust learning method that eliminates the need for both bias annotations and predictions. With the goal of reducing the mutual information between spurious factors and label information, our method leverages a sample reweighting strategy to achieve class-conditional distribution balancing, which automatically highlights minority groups and classes, effectively dismantling spurious correlations and producing a debiased data distribution for classification. Extensive experiments and analysis demonstrate that our approach consistently delivers state-of-the-art performance, rivaling methods that rely on bias supervision.