 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimal-Transport-Guided Functional Flow Matching for Turbulent Field Generation in Hilbert Space
Apr 07, 2026High-fidelity modeling of turbulent flows requires capturing complex spatiotemporal dynamics and multi-scale intermittency, posing a fundamental challenge for traditional knowledge-based systems. While deep generative models, such as diffusion models and Flow Matching, have shown promising performance, they are fundamentally constrained by their discrete, pixel-based nature. This limitation restricts their applicability in turbulence computing, where data inherently exists in a functional form. To address this gap, we propose Functional Optimal Transport Conditional Flow Matching (FOT-CFM), a generative framework defined directly in infinite-dimensional function space. Unlike conventional approaches defined on fixed grids, FOT-CFM treats physical fields as elements of an infinite-dimensional Hilbert space, and learns resolution-invariant generative dynamics directly at the level of probability measures. By integrating Optimal Transport (OT) theory, we construct deterministic, straight-line probability paths between noise and data measures in Hilbert space. This formulation enables simulation-free training and significantly accelerates the sampling process. We rigorously evaluate the proposed system on a diverse suite of chaotic dynamical systems, including the Navier-Stokes equations, Kolmogorov Flow, and Hasegawa-Wakatani equations, all of which exhibit rich multi-scale turbulent structures. Experimental results demonstrate that FOT-CFM achieves superior fidelity in reproducing high-order turbulent statistics and energy spectra compared to state-of-the-art baselines.
Content-Aware RSMA-Enabled Pinching-Antenna Systems for Latency Optimization in 6G Networks
Dec 19, 2025The Pinching Antenna System (PAS) has emerged as a promising technology to dynamically reconfigure wireless propagation environments in 6G networks. By activating radiating elements at arbitrary positions along a dielectric waveguide, PAS can establish strong line-of-sight (LoS) links with users, significantly enhancing channel gain and deployment flexibility, particularly in high-frequency bands susceptible to severe path loss. To further improve multi-user performance, this paper introduces a novel content-aware transmission framework that integrates PAS with rate-splitting multiple access (RSMA). Unlike conventional RSMA, the proposed RSMA scheme enables users requesting the same content to share a unified private stream, thereby mitigating inter-user interference and reducing power fragmentation. We formulate a joint optimization problem aimed at minimizing the average system latency by dynamically adapting both antenna positioning and RSMA parameters according to channel conditions and user requests. A Content-Aware RSMA and Pinching-antenna Joint Optimization (CARP-JO) algorithm is developed, which decomposes the non-convex problem into tractable subproblems solved via bisection search, convex programming, and golden-section search. Simulation results demonstrate that the proposed CARP-JO scheme consistently outperforms Traditional RSMA, NOMA, and Fixed-antenna systems across diverse network scenarios in terms of latency, underscoring the effectiveness of co-designing physical-layer reconfigurability with intelligent communication strategies.
SeerAttention-R: Sparse Attention Adaptation for Long Reasoning
Jun 10, 2025



We introduce SeerAttention-R, a sparse attention framework specifically tailored for the long decoding of reasoning models. Extended from SeerAttention, SeerAttention-R retains the design of learning attention sparsity through a self-distilled gating mechanism, while removing query pooling to accommodate auto-regressive decoding. With a lightweight plug-in gating, SeerAttention-R is flexible and can be easily integrated into existing pretrained model without modifying the original parameters. We demonstrate that SeerAttention-R, trained on just 0.4B tokens, maintains near-lossless reasoning accuracy with 4K token budget in AIME benchmark under large sparse attention block sizes (64/128). Using TileLang, we develop a highly optimized sparse decoding kernel that achieves near-theoretical speedups of up to 9x over FlashAttention-3 on H100 GPU at 90% sparsity. Code is available at: https://github.com/microsoft/SeerAttention.
Deterministic-to-Stochastic Diverse Latent Feature Mapping for Human Motion Synthesis
May 02, 2025Human motion synthesis aims to generate plausible human motion sequences, which has raised widespread attention in computer animation. Recent score-based generative models (SGMs) have demonstrated impressive results on this task. However, their training process involves complex curvature trajectories, leading to unstable training process. In this paper, we propose a Deterministic-to-Stochastic Diverse Latent Feature Mapping (DSDFM) method for human motion synthesis. DSDFM consists of two stages. The first human motion reconstruction stage aims to learn the latent space distribution of human motions. The second diverse motion generation stage aims to build connections between the Gaussian distribution and the latent space distribution of human motions, thereby enhancing the diversity and accuracy of the generated human motions. This stage is achieved by the designed deterministic feature mapping procedure with DerODE and stochastic diverse output generation procedure with DivSDE.DSDFM is easy to train compared to previous SGMs-based methods and can enhance diversity without introducing additional training parameters.Through qualitative and quantitative experiments, DSDFM achieves state-of-the-art results surpassing the latest methods, validating its superiority in human motion synthesis.
A Scalable Learned Index Scheme in Storage Systems
May 08, 2019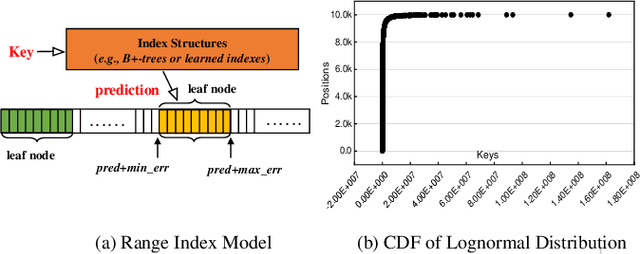
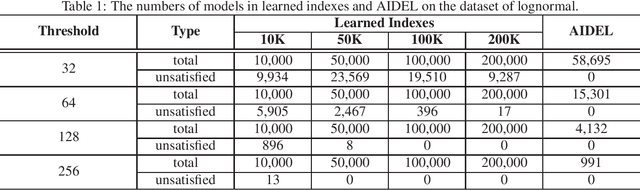
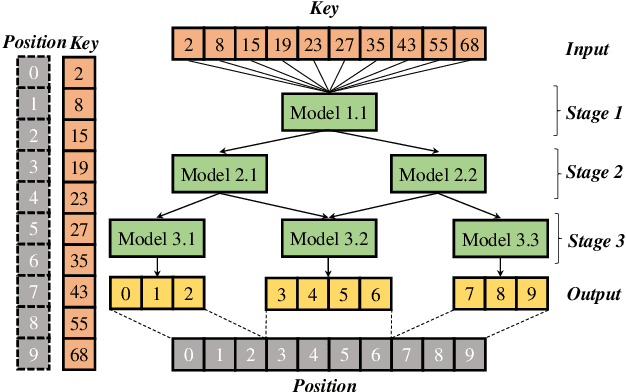
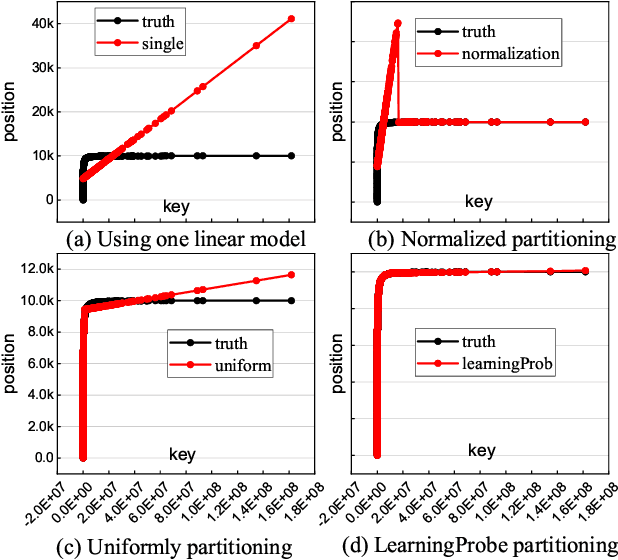
Index structures are important for efficient data access, which have been widely used to improve the performance in many in-memory systems. Due to high in-memory overheads, traditional index structures become difficult to process the explosive growth of data, let alone providing low latency and high throughput performance with limited system resources. The promising learned indexes leverage deep-learning models to complement existing index structures and obtain significant memory savings. However, the learned indexes fail to become scalable due to the heavy inter-model dependency and expensive retraining. To address these problems, we propose a scalable learned index scheme to construct different linear regression models according to the data distribution. Moreover, the used models are independent so as to reduce the complexity of retraining and become easy to partition and store the data into different pages, blocks or distributed systems. Our experimental results show that compared with state-of-the-art schemes, AIDEL improves the insertion performance by about 2$\times$ and provides comparable lookup performance, while efficiently supporting scalability.