 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClinically-Grounded Counterfactual Reasoning for Medical Video Diagnosis
May 26, 2026Medical video diagnosis involves inferring clinical decisions from dynamic tissue responses throughout examination processes. Existing methods rely on an end-to-end learning paradigm that i) focuses on appearance rather than pathology, ii) lacks clinical priors, and iii) reasons solely from observations without counterfactual comparison. This work introduces MedVCR, a counterfactual reasoning framework that mimics clinical diagnostic thinking. MedVCR comprises three components: a Counterfactual Generator that synthesizes tissue evolution under specified pathological states via a diffusion-based manner; a Counterfactual Representation Learning module that encodes diagnostic knowledge through clinical rules (i.e., temporal consistency, pathological separability, and counterfactual alignment); and a Dual Diagnostic Prediction strategy that integrates video-level assessment with frame-level counterfactual analysis. MedVCR is evaluated under both fully supervised (e.g., colposcopy) and weakly supervised (e.g., colonoscopy) video diagnosis settings, yielding 2.6%-10.2% performance gains compared with leading baselines. Comprehensive ablation studies further validate the effectiveness of each component. The code will be released.
APTOS-2024 challenge report: Generation of synthetic 3D OCT images from fundus photographs
Jun 09, 2025Optical Coherence Tomography (OCT) provides high-resolution, 3D, and non-invasive visualization of retinal layers in vivo, serving as a critical tool for lesion localization and disease diagnosis. However, its widespread adoption is limited by equipment costs and the need for specialized operators. In comparison, 2D color fundus photography offers faster acquisition and greater accessibility with less dependence on expensive devices. Although generative artificial intelligence has demonstrated promising results in medical image synthesis, translating 2D fundus images into 3D OCT images presents unique challenges due to inherent differences in data dimensionality and biological information between modalities. To advance generative models in the fundus-to-3D-OCT setting, the Asia Pacific Tele-Ophthalmology Society (APTOS-2024) organized a challenge titled Artificial Intelligence-based OCT Generation from Fundus Images. This paper details the challenge framework (referred to as APTOS-2024 Challenge), including: the benchmark dataset, evaluation methodology featuring two fidelity metrics-image-based distance (pixel-level OCT B-scan similarity) and video-based distance (semantic-level volumetric consistency), and analysis of top-performing solutions. The challenge attracted 342 participating teams, with 42 preliminary submissions and 9 finalists. Leading methodologies incorporated innovations in hybrid data preprocessing or augmentation (cross-modality collaborative paradigms), pre-training on external ophthalmic imaging datasets, integration of vision foundation models, and model architecture improvement. The APTOS-2024 Challenge is the first benchmark demonstrating the feasibility of fundus-to-3D-OCT synthesis as a potential solution for improving ophthalmic care accessibility in under-resourced healthcare settings, while helping to expedite medical research and clinical applications.
Benchmarking Large Multimodal Models for Ophthalmic Visual Question Answering with OphthalWeChat
May 26, 2025Purpose: To develop a bilingual multimodal visual question answering (VQA) benchmark for evaluating VLMs in ophthalmology. Methods: Ophthalmic image posts and associated captions published between January 1, 2016, and December 31, 2024, were collected from WeChat Official Accounts. Based on these captions, bilingual question-answer (QA) pairs in Chinese and English were generated using GPT-4o-mini. QA pairs were categorized into six subsets by question type and language: binary (Binary_CN, Binary_EN), single-choice (Single-choice_CN, Single-choice_EN), and open-ended (Open-ended_CN, Open-ended_EN). The benchmark was used to evaluate the performance of three VLMs: GPT-4o, Gemini 2.0 Flash, and Qwen2.5-VL-72B-Instruct. Results: The final OphthalWeChat dataset included 3,469 images and 30,120 QA pairs across 9 ophthalmic subspecialties, 548 conditions, 29 imaging modalities, and 68 modality combinations. Gemini 2.0 Flash achieved the highest overall accuracy (0.548), outperforming GPT-4o (0.522, P < 0.001) and Qwen2.5-VL-72B-Instruct (0.514, P < 0.001). It also led in both Chinese (0.546) and English subsets (0.550). Subset-specific performance showed Gemini 2.0 Flash excelled in Binary_CN (0.687), Single-choice_CN (0.666), and Single-choice_EN (0.646), while GPT-4o ranked highest in Binary_EN (0.717), Open-ended_CN (BLEU-1: 0.301; BERTScore: 0.382), and Open-ended_EN (BLEU-1: 0.183; BERTScore: 0.240). Conclusions: This study presents the first bilingual VQA benchmark for ophthalmology, distinguished by its real-world context and inclusion of multiple examinations per patient. The dataset reflects authentic clinical decision-making scenarios and enables quantitative evaluation of VLMs, supporting the development of accurate, specialized, and trustworthy AI systems for eye care.
Predicting Diabetic Macular Edema Treatment Responses Using OCT: Dataset and Methods of APTOS Competition
May 09, 2025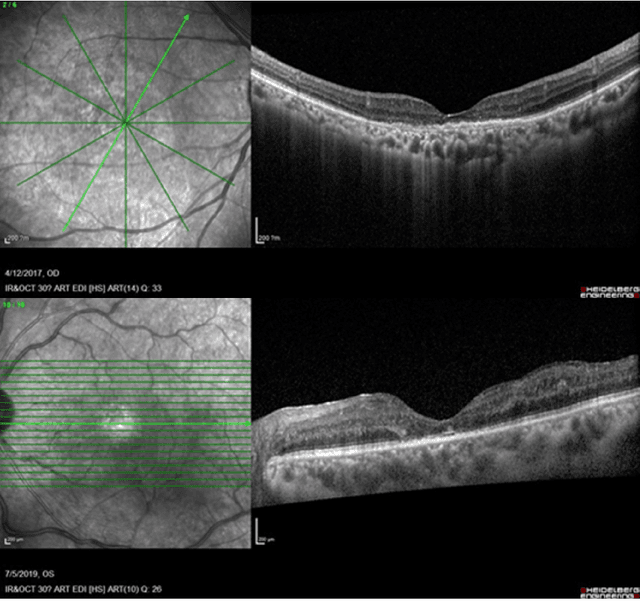
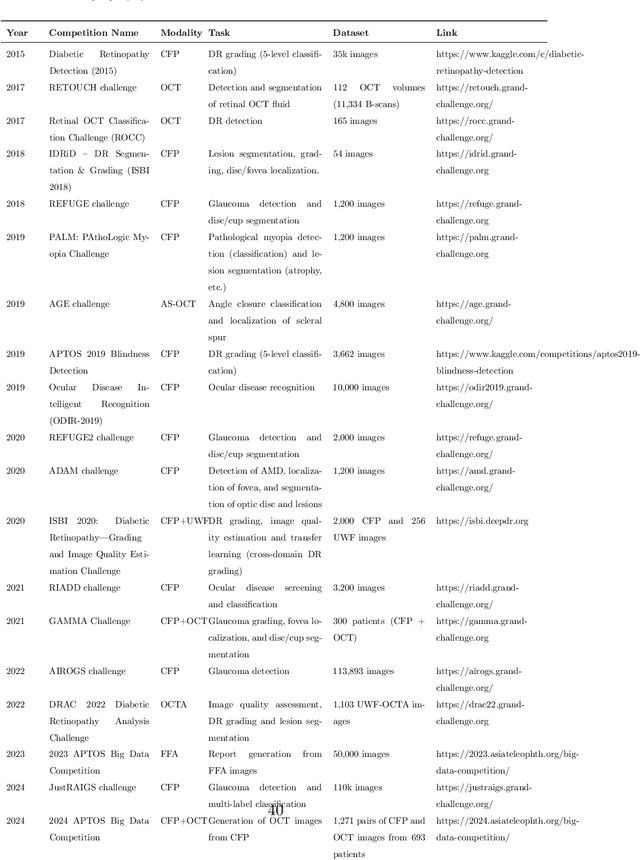
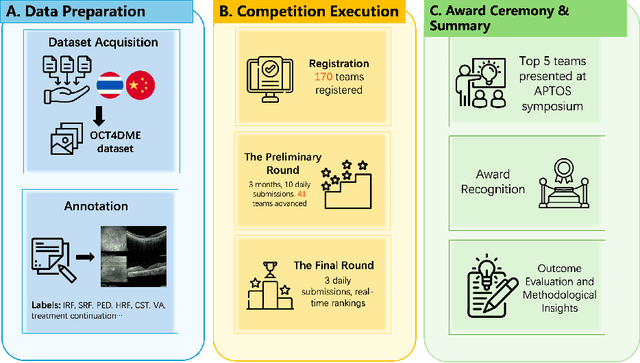

Diabetic macular edema (DME) significantly contributes to visual impairment in diabetic patients. Treatment responses to intravitreal therapies vary, highlighting the need for patient stratification to predict therapeutic benefits and enable personalized strategies. To our knowledge, this study is the first to explore pre-treatment stratification for predicting DME treatment responses. To advance this research, we organized the 2nd Asia-Pacific Tele-Ophthalmology Society (APTOS) Big Data Competition in 2021. The competition focused on improving predictive accuracy for anti-VEGF therapy responses using ophthalmic OCT images. We provided a dataset containing tens of thousands of OCT images from 2,000 patients with labels across four sub-tasks. This paper details the competition's structure, dataset, leading methods, and evaluation metrics. The competition attracted strong scientific community participation, with 170 teams initially registering and 41 reaching the final round. The top-performing team achieved an AUC of 80.06%, highlighting the potential of AI in personalized DME treatment and clinical decision-making.
FFA Sora, video generation as fundus fluorescein angiography simulator
Dec 23, 2024



Fundus fluorescein angiography (FFA) is critical for diagnosing retinal vascular diseases, but beginners often struggle with image interpretation. This study develops FFA Sora, a text-to-video model that converts FFA reports into dynamic videos via a Wavelet-Flow Variational Autoencoder (WF-VAE) and a diffusion transformer (DiT). Trained on an anonymized dataset, FFA Sora accurately simulates disease features from the input text, as confirmed by objective metrics: Frechet Video Distance (FVD) = 329.78, Learned Perceptual Image Patch Similarity (LPIPS) = 0.48, and Visual-question-answering Score (VQAScore) = 0.61. Specific evaluations showed acceptable alignment between the generated videos and textual prompts, with BERTScore of 0.35. Additionally, the model demonstrated strong privacy-preserving performance in retrieval evaluations, achieving an average Recall@K of 0.073. Human assessments indicated satisfactory visual quality, with an average score of 1.570(scale: 1 = best, 5 = worst). This model addresses privacy concerns associated with sharing large-scale FFA data and enhances medical education.
EyeDiff: text-to-image diffusion model improves rare eye disease diagnosis
Nov 15, 2024The rising prevalence of vision-threatening retinal diseases poses a significant burden on the global healthcare systems. Deep learning (DL) offers a promising solution for automatic disease screening but demands substantial data. Collecting and labeling large volumes of ophthalmic images across various modalities encounters several real-world challenges, especially for rare diseases. Here, we introduce EyeDiff, a text-to-image model designed to generate multimodal ophthalmic images from natural language prompts and evaluate its applicability in diagnosing common and rare diseases. EyeDiff is trained on eight large-scale datasets using the advanced latent diffusion model, covering 14 ophthalmic image modalities and over 80 ocular diseases, and is adapted to ten multi-country external datasets. The generated images accurately capture essential lesional characteristics, achieving high alignment with text prompts as evaluated by objective metrics and human experts. Furthermore, integrating generated images significantly enhances the accuracy of detecting minority classes and rare eye diseases, surpassing traditional oversampling methods in addressing data imbalance. EyeDiff effectively tackles the issue of data imbalance and insufficiency typically encountered in rare diseases and addresses the challenges of collecting large-scale annotated images, offering a transformative solution to enhance the development of expert-level diseases diagnosis models in ophthalmic field.
MiniTac: An Ultra-Compact 8 mm Vision-Based Tactile Sensor for Enhanced Palpation in Robot-Assisted Minimally Invasive Surgery
Oct 30, 2024Robot-assisted minimally invasive surgery (RAMIS) provides substantial benefits over traditional open and laparoscopic methods. However, a significant limitation of RAMIS is the surgeon's inability to palpate tissues, a crucial technique for examining tissue properties and detecting abnormalities, restricting the widespread adoption of RAMIS. To overcome this obstacle, we introduce MiniTac, a novel vision-based tactile sensor with an ultra-compact cross-sectional diameter of 8 mm, designed for seamless integration into mainstream RAMIS devices, particularly the Da Vinci surgical systems. MiniTac features a novel mechanoresponsive photonic elastomer membrane that changes color distribution under varying contact pressures. This color change is captured by an embedded miniature camera, allowing MiniTac to detect tumors both on the tissue surface and in deeper layers typically obscured from endoscopic view. MiniTac's efficacy has been rigorously tested on both phantoms and ex-vivo tissues. By leveraging advanced mechanoresponsive photonic materials, MiniTac represents a significant advancement in integrating tactile sensing into RAMIS, potentially expanding its applicability to a wider array of clinical scenarios that currently rely on traditional surgical approaches.
Visual Question Answering in Ophthalmology: A Progressive and Practical Perspective
Oct 22, 2024

Accurate diagnosis of ophthalmic diseases relies heavily on the interpretation of multimodal ophthalmic images, a process often time-consuming and expertise-dependent. Visual Question Answering (VQA) presents a potential interdisciplinary solution by merging computer vision and natural language processing to comprehend and respond to queries about medical images. This review article explores the recent advancements and future prospects of VQA in ophthalmology from both theoretical and practical perspectives, aiming to provide eye care professionals with a deeper understanding and tools for leveraging the underlying models. Additionally, we discuss the promising trend of large language models (LLM) in enhancing various components of the VQA framework to adapt to multimodal ophthalmic tasks. Despite the promising outlook, ophthalmic VQA still faces several challenges, including the scarcity of annotated multimodal image datasets, the necessity of comprehensive and unified evaluation methods, and the obstacles to achieving effective real-world applications. This article highlights these challenges and clarifies future directions for advancing ophthalmic VQA with LLMs. The development of LLM-based ophthalmic VQA systems calls for collaborative efforts between medical professionals and AI experts to overcome existing obstacles and advance the diagnosis and care of eye diseases.
Fundus to Fluorescein Angiography Video Generation as a Retinal Generative Foundation Model
Oct 17, 2024



Fundus fluorescein angiography (FFA) is crucial for diagnosing and monitoring retinal vascular issues but is limited by its invasive nature and restricted accessibility compared to color fundus (CF) imaging. Existing methods that convert CF images to FFA are confined to static image generation, missing the dynamic lesional changes. We introduce Fundus2Video, an autoregressive generative adversarial network (GAN) model that generates dynamic FFA videos from single CF images. Fundus2Video excels in video generation, achieving an FVD of 1497.12 and a PSNR of 11.77. Clinical experts have validated the fidelity of the generated videos. Additionally, the model's generator demonstrates remarkable downstream transferability across ten external public datasets, including blood vessel segmentation, retinal disease diagnosis, systemic disease prediction, and multimodal retrieval, showcasing impressive zero-shot and few-shot capabilities. These findings position Fundus2Video as a powerful, non-invasive alternative to FFA exams and a versatile retinal generative foundation model that captures both static and temporal retinal features, enabling the representation of complex inter-modality relationships.
EyeCLIP: A visual-language foundation model for multi-modal ophthalmic image analysis
Sep 10, 2024Early detection of eye diseases like glaucoma, macular degeneration, and diabetic retinopathy is crucial for preventing vision loss. While artificial intelligence (AI) foundation models hold significant promise for addressing these challenges, existing ophthalmic foundation models primarily focus on a single modality, whereas diagnosing eye diseases requires multiple modalities. A critical yet often overlooked aspect is harnessing the multi-view information across various modalities for the same patient. Additionally, due to the long-tail nature of ophthalmic diseases, standard fully supervised or unsupervised learning approaches often struggle. Therefore, it is essential to integrate clinical text to capture a broader spectrum of diseases. We propose EyeCLIP, a visual-language foundation model developed using over 2.77 million multi-modal ophthalmology images with partial text data. To fully leverage the large multi-modal unlabeled and labeled data, we introduced a pretraining strategy that combines self-supervised reconstructions, multi-modal image contrastive learning, and image-text contrastive learning to learn a shared representation of multiple modalities. Through evaluation using 14 benchmark datasets, EyeCLIP can be transferred to a wide range of downstream tasks involving ocular and systemic diseases, achieving state-of-the-art performance in disease classification, visual question answering, and cross-modal retrieval. EyeCLIP represents a significant advancement over previous methods, especially showcasing few-shot, even zero-shot capabilities in real-world long-tail scenarios.