 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Data Synthesis and Post-training for Visual Abstract Reasoning
Apr 02, 2025



This paper is a pioneering work attempting to address abstract visual reasoning (AVR) problems for large vision-language models (VLMs). We make a common LLaVA-NeXT 7B model capable of perceiving and reasoning about specific AVR problems, surpassing both open-sourced (e.g., Qwen-2-VL-72B) and closed-sourced powerful VLMs (e.g., GPT-4o) with significant margin. This is a great breakthrough since almost all previous VLMs fail or show nearly random performance on representative AVR benchmarks. Our key success is our innovative data synthesis and post-training process, aiming to fully relieve the task difficulty and elicit the model to learn, step by step. Our 7B model is also shown to be behave well on AVR without sacrificing common multimodal comprehension abilities. We hope our paper could serve as an early effort in this area and would inspire further research in abstract visual reasoning.
Revisiting MLLMs: An In-Depth Analysis of Image Classification Abilities
Dec 21, 2024



With the rapid advancement of Multimodal Large Language Models (MLLMs), a variety of benchmarks have been introduced to evaluate their capabilities. While most evaluations have focused on complex tasks such as scientific comprehension and visual reasoning, little attention has been given to assessing their fundamental image classification abilities. In this paper, we address this gap by thoroughly revisiting the MLLMs with an in-depth analysis of image classification. Specifically, building on established datasets, we examine a broad spectrum of scenarios, from general classification tasks (e.g., ImageNet, ObjectNet) to more fine-grained categories such as bird and food classification. Our findings reveal that the most recent MLLMs can match or even outperform CLIP-style vision-language models on several datasets, challenging the previous assumption that MLLMs are bad at image classification \cite{VLMClassifier}. To understand the factors driving this improvement, we conduct an in-depth analysis of the network architecture, data selection, and training recipe used in public MLLMs. Our results attribute this success to advancements in language models and the diversity of training data sources. Based on these observations, we further analyze and attribute the potential reasons to conceptual knowledge transfer and enhanced exposure of target concepts, respectively. We hope our findings will offer valuable insights for future research on MLLMs and their evaluation in image classification tasks.
Continual SFT Matches Multimodal RLHF with Negative Supervision
Nov 22, 2024



Multimodal RLHF usually happens after supervised finetuning (SFT) stage to continually improve vision-language models' (VLMs) comprehension. Conventional wisdom holds its superiority over continual SFT during this preference alignment stage. In this paper, we observe that the inherent value of multimodal RLHF lies in its negative supervision, the logit of the rejected responses. We thus propose a novel negative supervised finetuning (nSFT) approach that fully excavates these information resided. Our nSFT disentangles this negative supervision in RLHF paradigm, and continually aligns VLMs with a simple SFT loss. This is more memory efficient than multimodal RLHF where 2 (e.g., DPO) or 4 (e.g., PPO) large VLMs are strictly required. The effectiveness of nSFT is rigorously proved by comparing it with various multimodal RLHF approaches, across different dataset sources, base VLMs and evaluation metrics. Besides, fruitful of ablations are provided to support our hypothesis. We hope this paper will stimulate further research to properly align large vision language models.
Exploring the Causality of End-to-End Autonomous Driving
Jul 09, 2024



Deep learning-based models are widely deployed in autonomous driving areas, especially the increasingly noticed end-to-end solutions. However, the black-box property of these models raises concerns about their trustworthiness and safety for autonomous driving, and how to debug the causality has become a pressing concern. Despite some existing research on the explainability of autonomous driving, there is currently no systematic solution to help researchers debug and identify the key factors that lead to the final predicted action of end-to-end autonomous driving. In this work, we propose a comprehensive approach to explore and analyze the causality of end-to-end autonomous driving. First, we validate the essential information that the final planning depends on by using controlled variables and counterfactual interventions for qualitative analysis. Then, we quantitatively assess the factors influencing model decisions by visualizing and statistically analyzing the response of key model inputs. Finally, based on the comprehensive study of the multi-factorial end-to-end autonomous driving system, we have developed a strong baseline and a tool for exploring causality in the close-loop simulator CARLA. It leverages the essential input sources to obtain a well-designed model, resulting in highly competitive capabilities. As far as we know, our work is the first to unveil the mystery of end-to-end autonomous driving and turn the black box into a white one. Thorough close-loop experiments demonstrate that our method can be applied to end-to-end autonomous driving solutions for causality debugging. Code will be available at https://github.com/bdvisl/DriveInsight.
Task-Oriented Multi-Modal Mutual Leaning for Vision-Language Models
Mar 30, 2023



Prompt learning has become one of the most efficient paradigms for adapting large pre-trained vision-language models to downstream tasks. Current state-of-the-art methods, like CoOp and ProDA, tend to adopt soft prompts to learn an appropriate prompt for each specific task. Recent CoCoOp further boosts the base-to-new generalization performance via an image-conditional prompt. However, it directly fuses identical image semantics to prompts of different labels and significantly weakens the discrimination among different classes as shown in our experiments. Motivated by this observation, we first propose a class-aware text prompt (CTP) to enrich generated prompts with label-related image information. Unlike CoCoOp, CTP can effectively involve image semantics and avoid introducing extra ambiguities into different prompts. On the other hand, instead of reserving the complete image representations, we propose text-guided feature tuning (TFT) to make the image branch attend to class-related representation. A contrastive loss is employed to align such augmented text and image representations on downstream tasks. In this way, the image-to-text CTP and text-to-image TFT can be mutually promoted to enhance the adaptation of VLMs for downstream tasks. Extensive experiments demonstrate that our method outperforms the existing methods by a significant margin. Especially, compared to CoCoOp, we achieve an average improvement of 4.03% on new classes and 3.19% on harmonic-mean over eleven classification benchmarks.
EGNet:Edge Guidance Network for Salient Object Detection
Aug 22, 2019
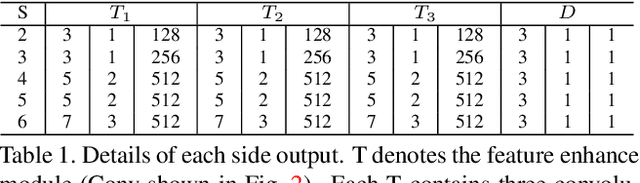
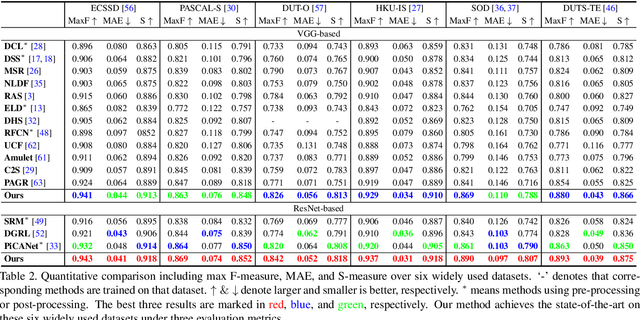
Fully convolutional neural networks (FCNs) have shown their advantages in the salient object detection task. However, most existing FCNs-based methods still suffer from coarse object boundaries. In this paper, to solve this problem, we focus on the complementarity between salient edge information and salient object information. Accordingly, we present an edge guidance network (EGNet) for salient object detection with three steps to simultaneously model these two kinds of complementary information in a single network. In the first step, we extract the salient object features by a progressive fusion way. In the second step, we integrate the local edge information and global location information to obtain the salient edge features. Finally, to sufficiently leverage these complementary features, we couple the same salient edge features with salient object features at various resolutions. Benefiting from the rich edge information and location information in salient edge features, the fused features can help locate salient objects, especially their boundaries more accurately. Experimental results demonstrate that the proposed method performs favorably against the state-of-the-art methods on six widely used datasets without any pre-processing and post-processing. The source code is available at http: //mmcheng.net/egnet/.
Three Birds One Stone: A Unified Framework for Salient Object Segmentation, Edge Detection and Skeleton Extraction
Mar 27, 2018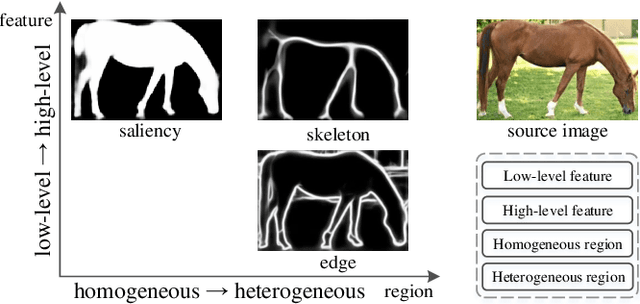
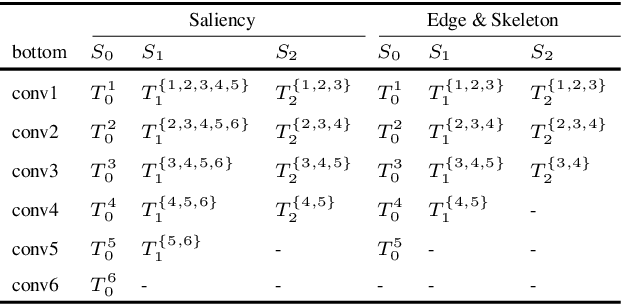
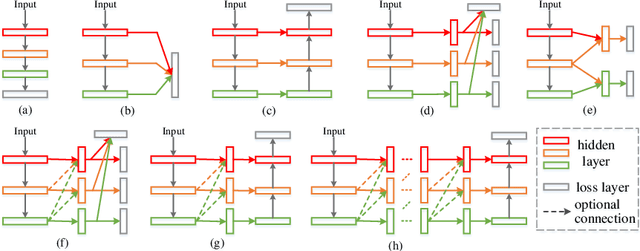
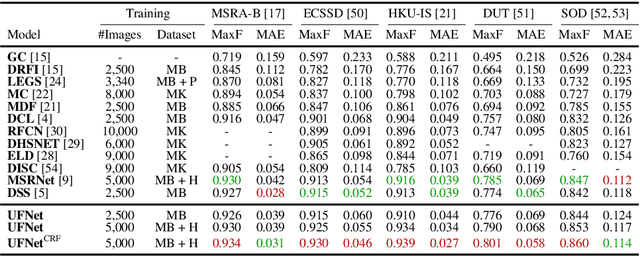
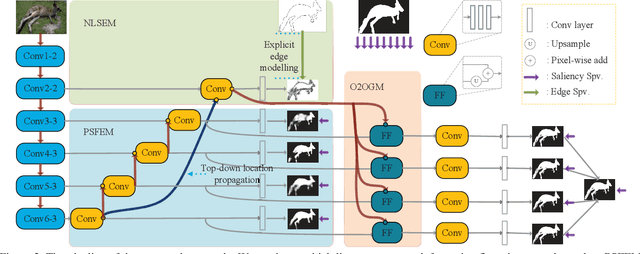
In this paper, we aim at solving pixel-wise binary problems, including salient object segmentation, skeleton extraction, and edge detection, by introducing a unified architecture. Previous works have proposed tailored methods for solving each of the three tasks independently. Here, we show that these tasks share some similarities that can be exploited for developing a unified framework. In particular, we introduce a horizontal cascade, each component of which is densely connected to the outputs of previous component. Stringing these components together allows us to effectively exploit features across different levels hierarchically to effectively address the multiple pixel-wise binary regression tasks. To assess the performance of our proposed network on these tasks, we carry out exhaustive evaluations on multiple representative datasets. Although these tasks are inherently very different, we show that our unified approach performs very well on all of them and works far better than current single-purpose state-of-the-art methods. All the code in this paper will be publicly available.
WebSeg: Learning Semantic Segmentation from Web Searches
Mar 27, 2018


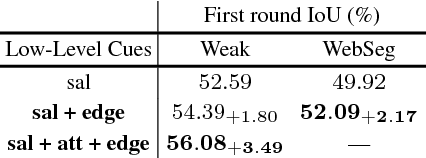
In this paper, we improve semantic segmentation by automatically learning from Flickr images associated with a particular keyword, without relying on any explicit user annotations, thus substantially alleviating the dependence on accurate annotations when compared to previous weakly supervised methods. To solve such a challenging problem, we leverage several low-level cues (such as saliency, edges, etc.) to help generate a proxy ground truth. Due to the diversity of web-crawled images, we anticipate a large amount of 'label noise' in which other objects might be present. We design an online noise filtering scheme which is able to deal with this label noise, especially in cluttered images. We use this filtering strategy as an auxiliary module to help assist the segmentation network in learning cleaner proxy annotations. Extensive experiments on the popular PASCAL VOC 2012 semantic segmentation benchmark show surprising good results in both our WebSeg (mIoU = 57.0%) and weakly supervised (mIoU = 63.3%) settings.