 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing RAW-to-sRGB with Decoupled Style Structure in Fourier Domain
Jan 04, 2024



RAW to sRGB mapping, which aims to convert RAW images from smartphones into RGB form equivalent to that of Digital Single-Lens Reflex (DSLR) cameras, has become an important area of research. However, current methods often ignore the difference between cell phone RAW images and DSLR camera RGB images, a difference that goes beyond the color matrix and extends to spatial structure due to resolution variations. Recent methods directly rebuild color mapping and spatial structure via shared deep representation, limiting optimal performance. Inspired by Image Signal Processing (ISP) pipeline, which distinguishes image restoration and enhancement, we present a novel Neural ISP framework, named FourierISP. This approach breaks the image down into style and structure within the frequency domain, allowing for independent optimization. FourierISP is comprised of three subnetworks: Phase Enhance Subnet for structural refinement, Amplitude Refine Subnet for color learning, and Color Adaptation Subnet for blending them in a smooth manner. This approach sharpens both color and structure, and extensive evaluations across varied datasets confirm that our approach realizes state-of-the-art results. Code will be available at ~\url{https://github.com/alexhe101/FourierISP}.
Scale Optimization Using Evolutionary Reinforcement Learning for Object Detection on Drone Imagery
Dec 23, 2023Object detection in aerial imagery presents a significant challenge due to large scale variations among objects. This paper proposes an evolutionary reinforcement learning agent, integrated within a coarse-to-fine object detection framework, to optimize the scale for more effective detection of objects in such images. Specifically, a set of patches potentially containing objects are first generated. A set of rewards measuring the localization accuracy, the accuracy of predicted labels, and the scale consistency among nearby patches are designed in the agent to guide the scale optimization. The proposed scale-consistency reward ensures similar scales for neighboring objects of the same category. Furthermore, a spatial-semantic attention mechanism is designed to exploit the spatial semantic relations between patches. The agent employs the proximal policy optimization strategy in conjunction with the evolutionary strategy, effectively utilizing both the current patch status and historical experience embedded in the agent. The proposed model is compared with state-of-the-art methods on two benchmark datasets for object detection on drone imagery. It significantly outperforms all the compared methods.
An efficient algorithm for multiuser sum-rate maximization of large-scale active RIS-aided MIMO system
Dec 13, 2023



Active reconfigurable intelligent surface (RIS) is a new RIS architecture that can reflect and amplify communication signals. It can provide enhanced performance gain compared to the conventional passive RIS systems that can only reflect the signals. On the other hand, the design problem of active RIS-aided systems is more challenging than the passive RIS-aided systems and its efficient algorithms are less studied. In this paper, we consider the sum rate maximization problem in the multiuser massive multiple-input single-output (MISO) downlink with the aid of a large-scale active RIS. Existing approaches usually resort to general optimization solvers and can be computationally prohibitive in the considered settings. We propose an efficient block successive upper bound minimization (BSUM) method, of which each step has a (semi) closed-form update. Thus, the proposed algorithm has an attractive low per-iteration complexity. By simulation, our proposed algorithm consumes much less computation than the existing approaches. In particular, when the MIMO and/or RIS sizes are large, our proposed algorithm can be orders-of-magnitude faster than existing approaches.
An empirical study of next-basket recommendations
Dec 05, 2023



Next Basket Recommender Systems (NBRs) function to recommend the subsequent shopping baskets for users through the modeling of their preferences derived from purchase history, typically manifested as a sequence of historical baskets. Given their widespread applicability in the E-commerce industry, investigations into NBRs have garnered increased attention in recent years. Despite the proliferation of diverse NBR methodologies, a substantial challenge lies in the absence of a systematic and unified evaluation framework across these methodologies. Various studies frequently appraise NBR approaches using disparate datasets and diverse experimental settings, impeding a fair and effective comparative assessment of methodological performance. To bridge this gap, this study undertakes a systematic empirical inquiry into NBRs, reviewing seminal works within the domain and scrutinizing their respective merits and drawbacks. Subsequently, we implement designated NBR algorithms on uniform datasets, employing consistent experimental configurations, and assess their performances via identical metrics. This methodological rigor establishes a cohesive framework for the impartial evaluation of diverse NBR approaches. It is anticipated that this study will furnish a robust foundation and serve as a pivotal reference for forthcoming research endeavors in this dynamic field.
Circuit as Set of Points
Oct 26, 2023



As the size of circuit designs continues to grow rapidly, artificial intelligence technologies are being extensively used in Electronic Design Automation (EDA) to assist with circuit design. Placement and routing are the most time-consuming parts of the physical design process, and how to quickly evaluate the placement has become a hot research topic. Prior works either transformed circuit designs into images using hand-crafted methods and then used Convolutional Neural Networks (CNN) to extract features, which are limited by the quality of the hand-crafted methods and could not achieve end-to-end training, or treated the circuit design as a graph structure and used Graph Neural Networks (GNN) to extract features, which require time-consuming preprocessing. In our work, we propose a novel perspective for circuit design by treating circuit components as point clouds and using Transformer-based point cloud perception methods to extract features from the circuit. This approach enables direct feature extraction from raw data without any preprocessing, allows for end-to-end training, and results in high performance. Experimental results show that our method achieves state-of-the-art performance in congestion prediction tasks on both the CircuitNet and ISPD2015 datasets, as well as in design rule check (DRC) violation prediction tasks on the CircuitNet dataset. Our method establishes a bridge between the relatively mature point cloud perception methods and the fast-developing EDA algorithms, enabling us to leverage more collective intelligence to solve this task. To facilitate the research of open EDA design, source codes and pre-trained models are released at https://github.com/hustvl/circuitformer.
Redistributing the Precision and Content in 3D-LUT-based Inverse Tone-mapping for HDR/WCG Display
Oct 15, 2023ITM(inverse tone-mapping) converts SDR (standard dynamic range) footage to HDR/WCG (high dynamic range /wide color gamut) for media production. It happens not only when remastering legacy SDR footage in front-end content provider, but also adapting on-theair SDR service on user-end HDR display. The latter requires more efficiency, thus the pre-calculated LUT (look-up table) has become a popular solution. Yet, conventional fixed LUT lacks adaptability, so we learn from research community and combine it with AI. Meanwhile, higher-bit-depth HDR/WCG requires larger LUT than SDR, so we consult traditional ITM for an efficiency-performance trade-off: We use 3 smaller LUTs, each has a non-uniform packing (precision) respectively denser in dark, middle and bright luma range. In this case, their results will have less error only in their own range, so we use a contribution map to combine their best parts to final result. With the guidance of this map, the elements (content) of 3 LUTs will also be redistributed during training. We conduct ablation studies to verify method's effectiveness, and subjective and objective experiments to show its practicability. Code is available at: https://github.com/AndreGuo/ITMLUT.
FireFly v2: Advancing Hardware Support for High-Performance Spiking Neural Network with a Spatiotemporal FPGA Accelerator
Sep 28, 2023



Spiking Neural Networks (SNNs) are expected to be a promising alternative to Artificial Neural Networks (ANNs) due to their strong biological interpretability and high energy efficiency. Specialized SNN hardware offers clear advantages over general-purpose devices in terms of power and performance. However, there's still room to advance hardware support for state-of-the-art (SOTA) SNN algorithms and improve computation and memory efficiency. As a further step in supporting high-performance SNNs on specialized hardware, we introduce FireFly v2, an FPGA SNN accelerator that can address the issue of non-spike operation in current SOTA SNN algorithms, which presents an obstacle in the end-to-end deployment onto existing SNN hardware. To more effectively align with the SNN characteristics, we design a spatiotemporal dataflow that allows four dimensions of parallelism and eliminates the need for membrane potential storage, enabling on-the-fly spike processing and spike generation. To further improve hardware acceleration performance, we develop a high-performance spike computing engine as a backend based on a systolic array operating at 500-600MHz. To the best of our knowledge, FireFly v2 achieves the highest clock frequency among all FPGA-based implementations. Furthermore, it stands as the first SNN accelerator capable of supporting non-spike operations, which are commonly used in advanced SNN algorithms. FireFly v2 has doubled the throughput and DSP efficiency when compared to our previous version of FireFly and it exhibits 1.33 times the DSP efficiency and 1.42 times the power efficiency compared to the current most advanced FPGA accelerators.
A Vision-Centric Approach for Static Map Element Annotation
Sep 21, 2023



The recent development of online static map element (a.k.a. HD Map) construction algorithms has raised a vast demand for data with ground truth annotations. However, available public datasets currently cannot provide high-quality training data regarding consistency and accuracy. To this end, we present CAMA: a vision-centric approach for Consistent and Accurate Map Annotation. Without LiDAR inputs, our proposed framework can still generate high-quality 3D annotations of static map elements. Specifically, the annotation can achieve high reprojection accuracy across all surrounding cameras and is spatial-temporal consistent across the whole sequence. We apply our proposed framework to the popular nuScenes dataset to provide efficient and highly accurate annotations. Compared with the original nuScenes static map element, models trained with annotations from CAMA achieve lower reprojection errors (e.g., 4.73 vs. 8.03 pixels).
Artificial to Spiking Neural Networks Conversion for Scientific Machine Learning
Aug 31, 2023We introduce a method to convert Physics-Informed Neural Networks (PINNs), commonly used in scientific machine learning, to Spiking Neural Networks (SNNs), which are expected to have higher energy efficiency compared to traditional Artificial Neural Networks (ANNs). We first extend the calibration technique of SNNs to arbitrary activation functions beyond ReLU, making it more versatile, and we prove a theorem that ensures the effectiveness of the calibration. We successfully convert PINNs to SNNs, enabling computational efficiency for diverse regression tasks in solving multiple differential equations, including the unsteady Navier-Stokes equations. We demonstrate great gains in terms of overall efficiency, including Separable PINNs (SPINNs), which accelerate the training process. Overall, this is the first work of this kind and the proposed method achieves relatively good accuracy with low spike rates.
Improving Few-shot Image Generation by Structural Discrimination and Textural Modulation
Aug 30, 2023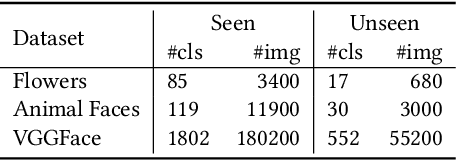
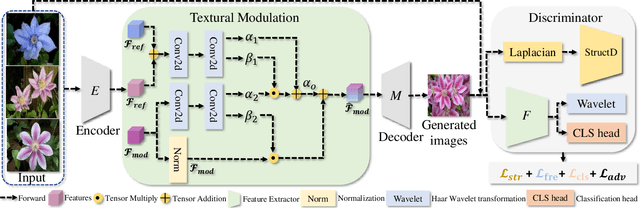
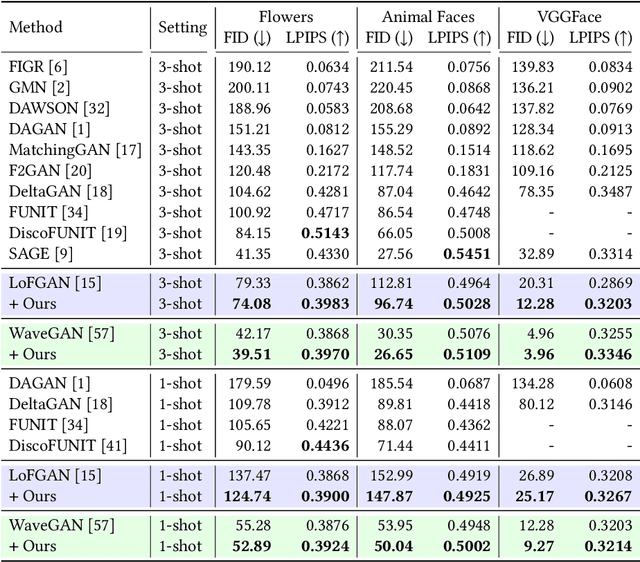

Few-shot image generation, which aims to produce plausible and diverse images for one category given a few images from this category, has drawn extensive attention. Existing approaches either globally interpolate different images or fuse local representations with pre-defined coefficients. However, such an intuitive combination of images/features only exploits the most relevant information for generation, leading to poor diversity and coarse-grained semantic fusion. To remedy this, this paper proposes a novel textural modulation (TexMod) mechanism to inject external semantic signals into internal local representations. Parameterized by the feedback from the discriminator, our TexMod enables more fined-grained semantic injection while maintaining the synthesis fidelity. Moreover, a global structural discriminator (StructD) is developed to explicitly guide the model to generate images with reasonable layout and outline. Furthermore, the frequency awareness of the model is reinforced by encouraging the model to distinguish frequency signals. Together with these techniques, we build a novel and effective model for few-shot image generation. The effectiveness of our model is identified by extensive experiments on three popular datasets and various settings. Besides achieving state-of-the-art synthesis performance on these datasets, our proposed techniques could be seamlessly integrated into existing models for a further performance boost.