 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOCP: Orthogonal Constrained Projection for Sparse Scaling in Industrial Commodity Recommendation
Mar 19, 2026In industrial commodity recommendation systems, the representation quality of Item-Id vocabularies directly impacts the scalability and generalization ability of recommendation models. A key challenge is that traditional Item-Id vocabularies, when subjected to sparse scaling, suffer from low-frequency information interference, which restricts their expressive power for massive item sets and leads to representation collapse. To address this issue, we propose an Orthogonal Constrained Projection method to optimize embedding representation. By enforcing orthogonality, the projection constrains the backpropagation manifold, aligning the singular value spectrum of the learned embeddings with the orthogonal basis. This alignment ensures high singular entropy, thereby preserving isotropic generalized features while suppressing spurious correlations and overfitting to rare items. Empirical results demonstrate that OCP accelerates loss convergence and enhances the model's scalability; notably, it enables consistent performance gains when scaling up dense layers. Large-scale industrial deployment on JD.com further confirms its efficacy, yielding a 12.97% increase in UCXR and an 8.9% uplift in GMV, highlighting its robust utility for scaling up both sparse vocabularies and dense architectures.
OxygenREC: An Instruction-Following Generative Framework for E-commerce Recommendation
Dec 31, 2025Traditional recommendation systems suffer from inconsistency in multi-stage optimization objectives. Generative Recommendation (GR) mitigates them through an end-to-end framework; however, existing methods still rely on matching mechanisms based on inductive patterns. Although responsive, they lack the ability to uncover complex user intents that require deductive reasoning based on world knowledge. Meanwhile, LLMs show strong deep reasoning capabilities, but their latency and computational costs remain challenging for industrial applications. More critically, there are performance bottlenecks in multi-scenario scalability: as shown in Figure 1, existing solutions require independent training and deployment for each scenario, leading to low resource utilization and high maintenance costs-a challenge unaddressed in GR literature. To address these, we present OxygenREC, an industrial recommendation system that leverages Fast-Slow Thinking to deliver deep reasoning with strict latency and multi-scenario requirements of real-world environments. First, we adopt a Fast-Slow Thinking architecture. Slow thinking uses a near-line LLM pipeline to synthesize Contextual Reasoning Instructions, while fast thinking employs a high-efficiency encoder-decoder backbone for real-time generation. Second, to ensure reasoning instructions effectively enhance recommendation generation, we introduce a semantic alignment mechanism with Instruction-Guided Retrieval (IGR) to filter intent-relevant historical behaviors and use a Query-to-Item (Q2I) loss for instruction-item consistency. Finally, to resolve multi-scenario scalability, we transform scenario information into controllable instructions, using unified reward mapping and Soft Adaptive Group Clip Policy Optimization (SA-GCPO) to align policies with diverse business objectives, realizing a train-once-deploy-everywhere paradigm.
Constrained Reinforcement Learning for Short Video Recommendation
May 26, 2022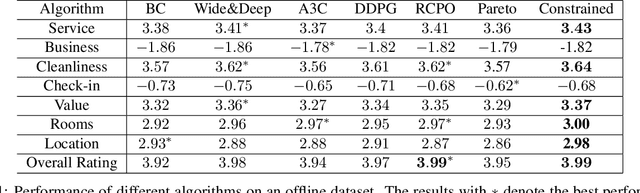
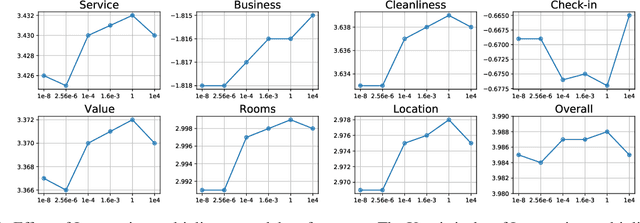
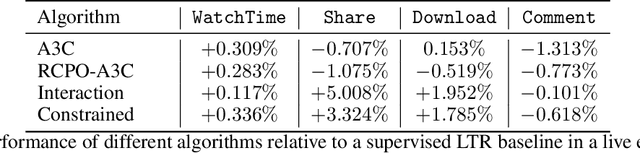
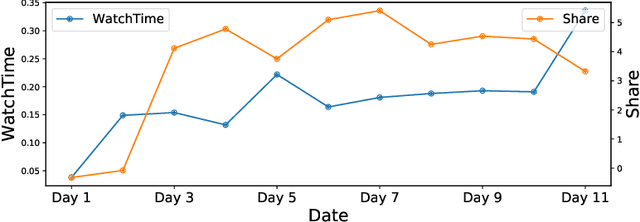
The wide popularity of short videos on social media poses new opportunities and challenges to optimize recommender systems on the video-sharing platforms. Users provide complex and multi-faceted responses towards recommendations, including watch time and various types of interactions with videos. As a result, established recommendation algorithms that concern a single objective are not adequate to meet this new demand of optimizing comprehensive user experiences. In this paper, we formulate the problem of short video recommendation as a constrained Markov Decision Process (MDP), where platforms want to optimize the main goal of user watch time in long term, with the constraint of accommodating the auxiliary responses of user interactions such as sharing/downloading videos. To solve the constrained MDP, we propose a two-stage reinforcement learning approach based on actor-critic framework. At stage one, we learn individual policies to optimize each auxiliary response. At stage two, we learn a policy to (i) optimize the main response and (ii) stay close to policies learned at the first stage, which effectively guarantees the performance of this main policy on the auxiliaries. Through extensive simulations, we demonstrate effectiveness of our approach over alternatives in both optimizing the main goal as well as balancing the others. We further show the advantage of our approach in live experiments of short video recommendations, where it significantly outperforms other baselines in terms of watch time and interactions from video views. Our approach has been fully launched in the production system to optimize user experiences on the platform.
Meta Graph Attention on Heterogeneous Graph with Node-Edge Co-evolution
Oct 09, 2020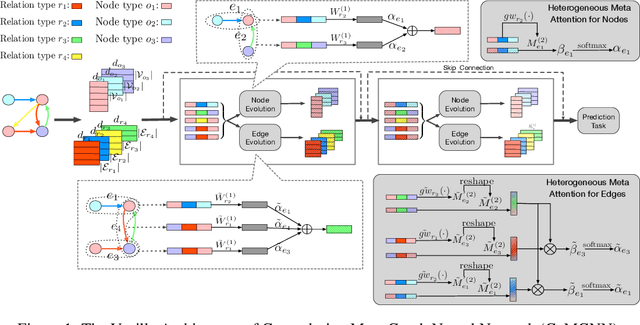
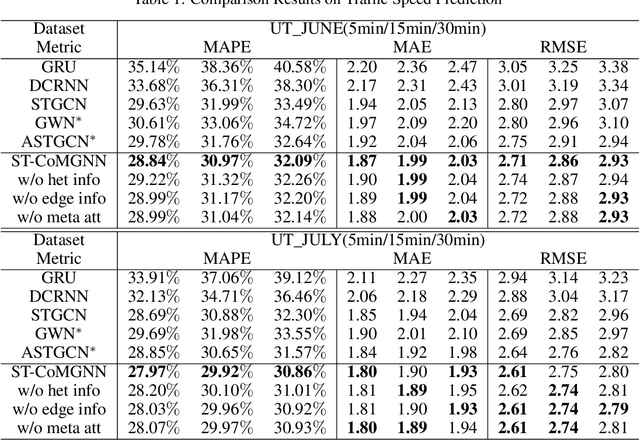
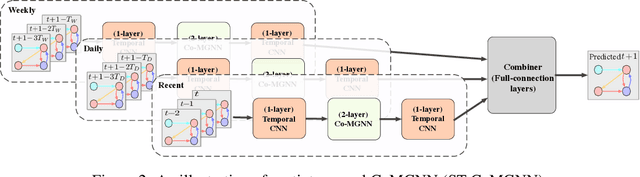
Graph neural networks have become an important tool for modeling structured data. In many real-world systems, intricate hidden information may exist, e.g., heterogeneity in nodes/edges, static node/edge attributes, and spatiotemporal node/edge features. However, most existing methods only take part of the information into consideration. In this paper, we present the Co-evolved Meta Graph Neural Network (CoMGNN), which applies meta graph attention to heterogeneous graphs with co-evolution of node and edge states. We further propose a spatiotemporal adaption of CoMGNN (ST-CoMGNN) for modeling spatiotemporal patterns on nodes and edges. We conduct experiments on two large-scale real-world datasets. Experimental results show that our models significantly outperform the state-of-the-art methods, demonstrating the effectiveness of encoding diverse information from different aspects.
Learning from Very Few Samples: A Survey
Sep 12, 2020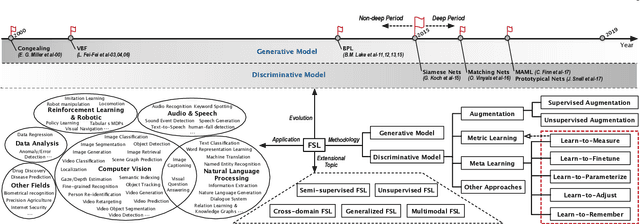
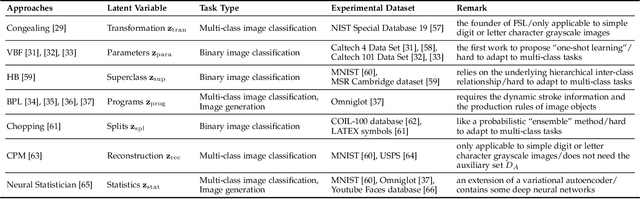
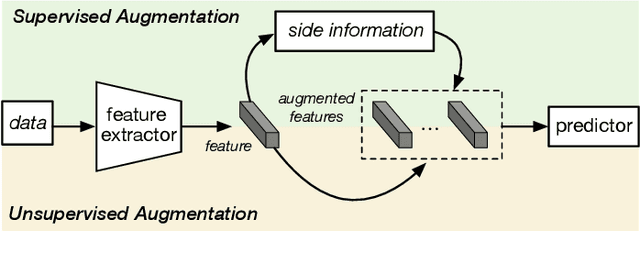
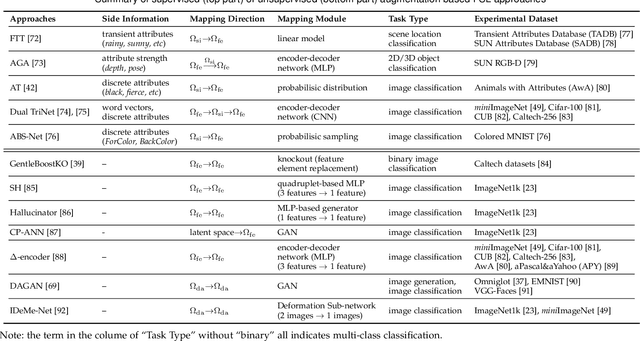
Few sample learning (FSL) is significant and challenging in the field of machine learning. The capability of learning and generalizing from very few samples successfully is a noticeable demarcation separating artificial intelligence and human intelligence since humans can readily establish their cognition to novelty from just a single or a handful of examples whereas machine learning algorithms typically entail hundreds or thousands of supervised samples to guarantee generalization ability. Despite the long history dated back to the early 2000s and the widespread attention in recent years with booming deep learning technologies, little surveys or reviews for FSL are available until now. In this context, we extensively review 300+ papers of FSL spanning from the 2000s to 2019 and provide a timely and comprehensive survey for FSL. In this survey, we review the evolution history as well as the current progress on FSL, categorize FSL approaches into the generative model based and discriminative model based kinds in principle, and emphasize particularly on the meta learning based FSL approaches. We also summarize several recently emerging extensional topics of FSL and review the latest advances on these topics. Furthermore, we highlight the important FSL applications covering many research hotspots in computer vision, natural language processing, audio and speech, reinforcement learning and robotic, data analysis, etc. Finally, we conclude the survey with a discussion on promising trends in the hope of providing guidance and insights to follow-up researches.
Deep Multi-View Spatial-Temporal Network for Taxi Demand Prediction
Feb 27, 2018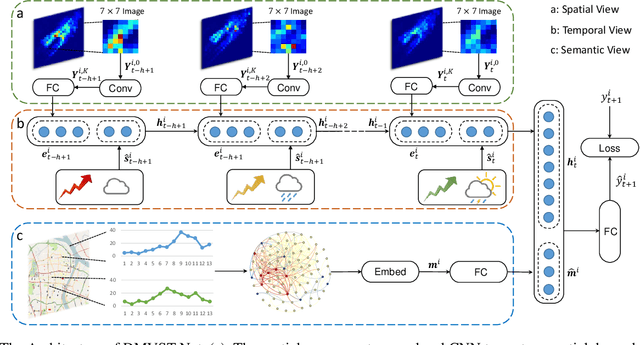
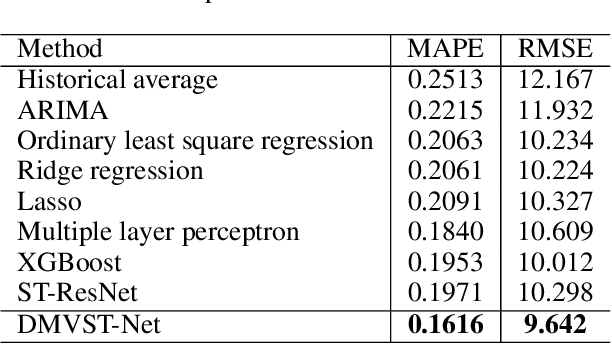

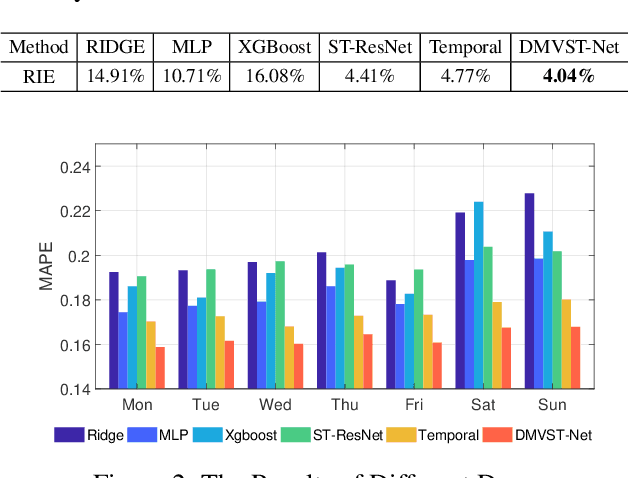
Taxi demand prediction is an important building block to enabling intelligent transportation systems in a smart city. An accurate prediction model can help the city pre-allocate resources to meet travel demand and to reduce empty taxis on streets which waste energy and worsen the traffic congestion. With the increasing popularity of taxi requesting services such as Uber and Didi Chuxing (in China), we are able to collect large-scale taxi demand data continuously. How to utilize such big data to improve the demand prediction is an interesting and critical real-world problem. Traditional demand prediction methods mostly rely on time series forecasting techniques, which fail to model the complex non-linear spatial and temporal relations. Recent advances in deep learning have shown superior performance on traditionally challenging tasks such as image classification by learning the complex features and correlations from large-scale data. This breakthrough has inspired researchers to explore deep learning techniques on traffic prediction problems. However, existing methods on traffic prediction have only considered spatial relation (e.g., using CNN) or temporal relation (e.g., using LSTM) independently. We propose a Deep Multi-View Spatial-Temporal Network (DMVST-Net) framework to model both spatial and temporal relations. Specifically, our proposed model consists of three views: temporal view (modeling correlations between future demand values with near time points via LSTM), spatial view (modeling local spatial correlation via local CNN), and semantic view (modeling correlations among regions sharing similar temporal patterns). Experiments on large-scale real taxi demand data demonstrate effectiveness of our approach over state-of-the-art methods.
Linear Convergence of Variance-Reduced Stochastic Gradient without Strong Convexity
Jul 10, 2015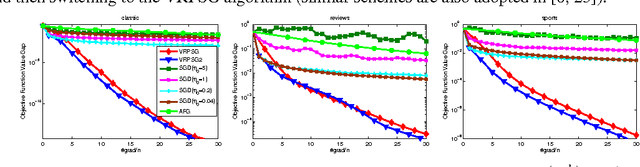
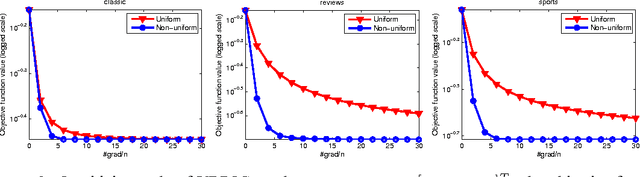
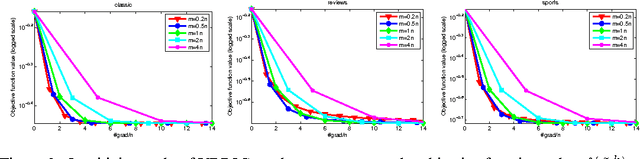
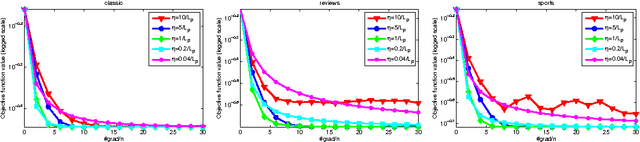
Stochastic gradient algorithms estimate the gradient based on only one or a few samples and enjoy low computational cost per iteration. They have been widely used in large-scale optimization problems. However, stochastic gradient algorithms are usually slow to converge and achieve sub-linear convergence rates, due to the inherent variance in the gradient computation. To accelerate the convergence, some variance-reduced stochastic gradient algorithms, e.g., proximal stochastic variance-reduced gradient (Prox-SVRG) algorithm, have recently been proposed to solve strongly convex problems. Under the strongly convex condition, these variance-reduced stochastic gradient algorithms achieve a linear convergence rate. However, many machine learning problems are convex but not strongly convex. In this paper, we introduce Prox-SVRG and its projected variant called Variance-Reduced Projected Stochastic Gradient (VRPSG) to solve a class of non-strongly convex optimization problems widely used in machine learning. As the main technical contribution of this paper, we show that both VRPSG and Prox-SVRG achieve a linear convergence rate without strong convexity. A key ingredient in our proof is a Semi-Strongly Convex (SSC) inequality which is the first to be rigorously proved for a class of non-strongly convex problems in both constrained and regularized settings. Moreover, the SSC inequality is independent of algorithms and may be applied to analyze other stochastic gradient algorithms besides VRPSG and Prox-SVRG, which may be of independent interest. To the best of our knowledge, this is the first work that establishes the linear convergence rate for the variance-reduced stochastic gradient algorithms on solving both constrained and regularized problems without strong convexity.
A General Iterative Shrinkage and Thresholding Algorithm for Non-convex Regularized Optimization Problems
Mar 18, 2013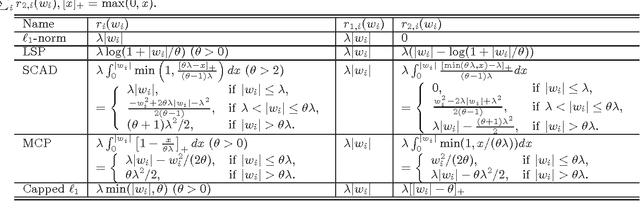
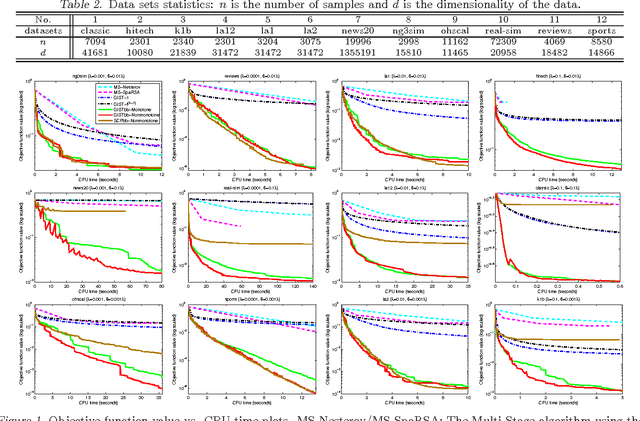
Non-convex sparsity-inducing penalties have recently received considerable attentions in sparse learning. Recent theoretical investigations have demonstrated their superiority over the convex counterparts in several sparse learning settings. However, solving the non-convex optimization problems associated with non-convex penalties remains a big challenge. A commonly used approach is the Multi-Stage (MS) convex relaxation (or DC programming), which relaxes the original non-convex problem to a sequence of convex problems. This approach is usually not very practical for large-scale problems because its computational cost is a multiple of solving a single convex problem. In this paper, we propose a General Iterative Shrinkage and Thresholding (GIST) algorithm to solve the nonconvex optimization problem for a large class of non-convex penalties. The GIST algorithm iteratively solves a proximal operator problem, which in turn has a closed-form solution for many commonly used penalties. At each outer iteration of the algorithm, we use a line search initialized by the Barzilai-Borwein (BB) rule that allows finding an appropriate step size quickly. The paper also presents a detailed convergence analysis of the GIST algorithm. The efficiency of the proposed algorithm is demonstrated by extensive experiments on large-scale data sets.
Efficient Superimposition Recovering Algorithm
Nov 19, 2012In this article, we address the issue of recovering latent transparent layers from superimposition images. Here, we assume we have the estimated transformations and extracted gradients of latent layers. To rapidly recover high-quality image layers, we propose an Efficient Superimposition Recovering Algorithm (ESRA) by extending the framework of accelerated gradient method. In addition, a key building block (in each iteration) in our proposed method is the proximal operator calculating. Here we propose to employ a dual approach and present our Parallel Algorithm with Constrained Total Variation (PACTV) method. Our recovering method not only reconstructs high-quality layers without color-bias problem, but also theoretically guarantees good convergence performance.
Multi-Stage Multi-Task Feature Learning
Oct 22, 2012Multi-task sparse feature learning aims to improve the generalization performance by exploiting the shared features among tasks. It has been successfully applied to many applications including computer vision and biomedical informatics. Most of the existing multi-task sparse feature learning algorithms are formulated as a convex sparse regularization problem, which is usually suboptimal, due to its looseness for approximating an $\ell_0$-type regularizer. In this paper, we propose a non-convex formulation for multi-task sparse feature learning based on a novel non-convex regularizer. To solve the non-convex optimization problem, we propose a Multi-Stage Multi-Task Feature Learning (MSMTFL) algorithm; we also provide intuitive interpretations, detailed convergence and reproducibility analysis for the proposed algorithm. Moreover, we present a detailed theoretical analysis showing that MSMTFL achieves a better parameter estimation error bound than the convex formulation. Empirical studies on both synthetic and real-world data sets demonstrate the effectiveness of MSMTFL in comparison with the state of the art multi-task sparse feature learning algorithms.