 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforced Preference Optimization for Reasoning-Augmented Recommendations
May 21, 2026Recommender systems are critical for delivering personalized content across digital platforms, and recent advances in Large Language Models (LLMs) offer new opportunities to enhance them with richer world knowledge and explicit reasoning capabilities. With the help of reasoning knowledge, recommendations can better infer users' underlying intents, adapt to evolving preferences, and leverage semantic relationships for improved accuracy and interpretability. However, existing reasoning-based recommendation methods often fail to fully align the LLM's reasoning process with recommendation-specific objectives due to structural disruption during integration and difficulties in translating free-form generation into accurate item predictions. In this paper, we introduce RPORec, a reinforced preference optimization framework that unifies an LLM backbone's reasoning ability with a dedicated recommendation head (Rechead) for precise item retrieval. RPORec comprises two stages: (1) Reasoning-Augmented Recommendation Modeling, where high-quality Chain-of-Thought (CoT) reasoning is generated and used as auxiliary knowledge to guide the Rechead in learning recommendation-specific representations; and (2) Advanced Reasoning Refinement and Alignment, in which the trained Rechead produces verifiable rewards to fine-tune the LLM backbone via reinforcement learning, enhancing reasoning quality, structural consistency, and task relevance. Extensive experiments on public benchmarks and large-scale online deployments show that RPORec consistently outperforms state-of-the-art LLM-based recommendation methods, demonstrating the effectiveness of reasoning-augmented recommendation modeling in real-world systems.
LBM: Hierarchical Large Auto-Bidding Model via Reasoning and Acting
Mar 05, 2026The growing scale of ad auctions on online advertising platforms has intensified competition, making manual bidding impractical and necessitating auto-bidding to help advertisers achieve their economic goals. Current auto-bidding methods have evolved to use offline reinforcement learning or generative methods to optimize bidding strategies, but they can sometimes behave counterintuitively due to the black-box training manner and limited mode coverage of datasets, leading to challenges in understanding task status and generalization in dynamic ad environments. Large language models (LLMs) offer a promising solution by leveraging prior human knowledge and reasoning abilities to improve auto-bidding performance. However, directly applying LLMs to auto-bidding faces difficulties due to the need for precise actions in competitive auctions and the lack of specialized auto-bidding knowledge, which can lead to hallucinations and suboptimal decisions. To address these challenges, we propose a hierarchical Large autoBidding Model (LBM) to leverage the reasoning capabilities of LLMs for developing a superior auto-bidding strategy. This includes a high-level LBM-Think model for reasoning and a low-level LBM-Act model for action generation. Specifically, we propose a dual embedding mechanism to efficiently fuse two modalities, including language and numerical inputs, for language-guided training of the LBM-Act; then, we propose an offline reinforcement fine-tuning technique termed GQPO for mitigating the LLM-Think's hallucinations and enhancing decision-making performance without simulation or real-world rollout like previous multi-turn LLM-based methods. Experiments demonstrate the superiority of a generative backbone based on our LBM, especially in an efficient training manner and generalization ability.
Phase-Aware Mixture of Experts for Agentic Reinforcement Learning
Feb 19, 2026Reinforcement learning (RL) has equipped LLM agents with a strong ability to solve complex tasks. However, existing RL methods normally use a \emph{single} policy network, causing \emph{simplicity bias} where simple tasks occupy most parameters and dominate gradient updates, leaving insufficient capacity for complex tasks. A plausible remedy could be employing the Mixture-of-Experts (MoE) architecture in the policy network, as MoE allows different parameters (experts) to specialize in different tasks, preventing simple tasks from dominating all parameters. However, a key limitation of traditional MoE is its token-level routing, where the router assigns each token to specialized experts, which fragments phase-consistent patterns into scattered expert assignments and thus undermines expert specialization. In this paper, we propose \textbf{Phase-Aware Mixture of Experts (PA-MoE)}. It first features a lightweight \emph{phase router} that learns latent phase boundaries directly from the RL objective without pre-defining phase categories. Then, the phase router allocates temporally consistent assignments to the same expert, allowing experts to preserve phase-specific expertise. Experimental results demonstrate the effectiveness of our proposed PA-MoE.
MindRec: A Diffusion-driven Coarse-to-Fine Paradigm for Generative Recommendation
Nov 18, 2025



Recent advancements in large language model-based recommendation systems often represent items as text or semantic IDs and generate recommendations in an auto-regressive manner. However, due to the left-to-right greedy decoding strategy and the unidirectional logical flow, such methods often fail to produce globally optimal recommendations. In contrast, human reasoning does not follow a rigid left-to-right sequence. Instead, it often begins with keywords or intuitive insights, which are then refined and expanded. Inspired by this fact, we propose MindRec, a diffusion-driven coarse-to-fine generative paradigm that emulates human thought processes. Built upon a diffusion language model, MindRec departs from auto-regressive generation by leveraging a masked diffusion process to reconstruct items in a flexible, non-sequential manner. Particularly, our method first generates key tokens that reflect user preferences, and then expands them into the complete item, enabling adaptive and human-like generation. To further emulate the structured nature of human decision-making, we organize items into a hierarchical category tree. This structure guides the model to first produce the coarse-grained category and then progressively refine its selection through finer-grained subcategories before generating the specific item. To mitigate the local optimum problem inherent in greedy decoding, we design a novel beam search algorithm, Diffusion Beam Search, tailored for our mind-inspired generation paradigm. Experimental results demonstrate that MindRec yields a 9.5\% average improvement in top-1 accuracy over state-of-the-art methods, highlighting its potential to enhance recommendation performance. The implementation is available via https://github.com/Mr-Peach0301/MindRec.
Generative Auto-Bidding in Large-Scale Competitive Auctions via Diffusion Completer-Aligner
Sep 03, 2025Auto-bidding is central to computational advertising, achieving notable commercial success by optimizing advertisers' bids within economic constraints. Recently, large generative models show potential to revolutionize auto-bidding by generating bids that could flexibly adapt to complex, competitive environments. Among them, diffusers stand out for their ability to address sparse-reward challenges by focusing on trajectory-level accumulated rewards, as well as their explainable capability, i.e., planning a future trajectory of states and executing bids accordingly. However, diffusers struggle with generation uncertainty, particularly regarding dynamic legitimacy between adjacent states, which can lead to poor bids and further cause significant loss of ad impression opportunities when competing with other advertisers in a highly competitive auction environment. To address it, we propose a Causal auto-Bidding method based on a Diffusion completer-aligner framework, termed CBD. Firstly, we augment the diffusion training process with an extra random variable t, where the model observes t-length historical sequences with the goal of completing the remaining sequence, thereby enhancing the generated sequences' dynamic legitimacy. Then, we employ a trajectory-level return model to refine the generated trajectories, aligning more closely with advertisers' objectives. Experimental results across diverse settings demonstrate that our approach not only achieves superior performance on large-scale auto-bidding benchmarks, such as a 29.9% improvement in conversion value in the challenging sparse-reward auction setting, but also delivers significant improvements on the Kuaishou online advertising platform, including a 2.0% increase in target cost.
Navigate the Unknown: Enhancing LLM Reasoning with Intrinsic Motivation Guided Exploration
May 23, 2025Reinforcement learning (RL) has emerged as a pivotal method for improving the reasoning capabilities of Large Language Models (LLMs). However, prevalent RL approaches such as Proximal Policy Optimization (PPO) and Group-Regularized Policy Optimization (GRPO) face critical limitations due to their reliance on sparse outcome-based rewards and inadequate mechanisms for incentivizing exploration. These limitations result in inefficient guidance for multi-step reasoning processes. Specifically, sparse reward signals fail to deliver effective or sufficient feedback, particularly for challenging problems. Furthermore, such reward structures induce systematic biases that prioritize exploitation of familiar trajectories over novel solution discovery. These shortcomings critically hinder performance in complex reasoning tasks, which inherently demand iterative refinement across ipntermediate steps. To address these challenges, we propose an Intrinsic Motivation guidEd exploratioN meThOd foR LLM Reasoning (i-MENTOR), a novel method designed to both deliver dense rewards and amplify explorations in the RL-based training paradigm. i-MENTOR introduces three key innovations: trajectory-aware exploration rewards that mitigate bias in token-level strategies while maintaining computational efficiency; dynamic reward scaling to stabilize exploration and exploitation in large action spaces; and advantage-preserving reward implementation that maintains advantage distribution integrity while incorporating exploratory guidance. Experiments across three public datasets demonstrate i-MENTOR's effectiveness with a 22.39% improvement on the difficult dataset Countdown-4.
Generative Auto-Bidding with Value-Guided Explorations
Apr 20, 2025Auto-bidding, with its strong capability to optimize bidding decisions within dynamic and competitive online environments, has become a pivotal strategy for advertising platforms. Existing approaches typically employ rule-based strategies or Reinforcement Learning (RL) techniques. However, rule-based strategies lack the flexibility to adapt to time-varying market conditions, and RL-based methods struggle to capture essential historical dependencies and observations within Markov Decision Process (MDP) frameworks. Furthermore, these approaches often face challenges in ensuring strategy adaptability across diverse advertising objectives. Additionally, as offline training methods are increasingly adopted to facilitate the deployment and maintenance of stable online strategies, the issues of documented behavioral patterns and behavioral collapse resulting from training on fixed offline datasets become increasingly significant. To address these limitations, this paper introduces a novel offline Generative Auto-bidding framework with Value-Guided Explorations (GAVE). GAVE accommodates various advertising objectives through a score-based Return-To-Go (RTG) module. Moreover, GAVE integrates an action exploration mechanism with an RTG-based evaluation method to explore novel actions while ensuring stability-preserving updates. A learnable value function is also designed to guide the direction of action exploration and mitigate Out-of-Distribution (OOD) problems. Experimental results on two offline datasets and real-world deployments demonstrate that GAVE outperforms state-of-the-art baselines in both offline evaluations and online A/B tests. The implementation code is publicly available to facilitate reproducibility and further research.
From Principles to Applications: A Comprehensive Survey of Discrete Tokenizers in Generation, Comprehension, Recommendation, and Information Retrieval
Feb 18, 2025
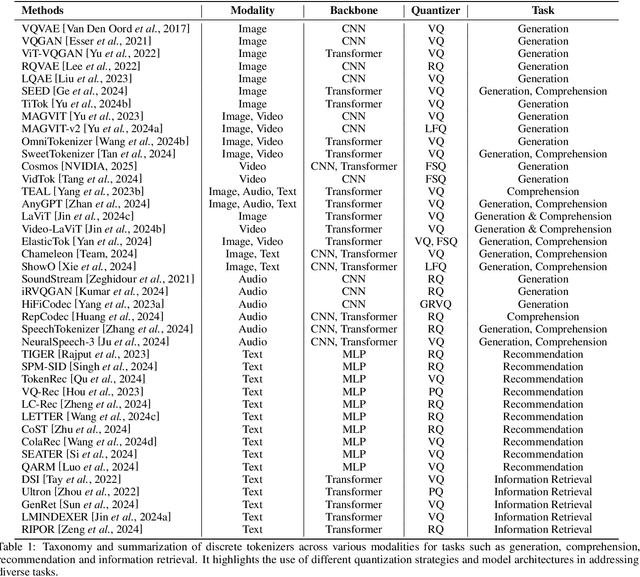
Discrete tokenizers have emerged as indispensable components in modern machine learning systems, particularly within the context of autoregressive modeling and large language models (LLMs). These tokenizers serve as the critical interface that transforms raw, unstructured data from diverse modalities into discrete tokens, enabling LLMs to operate effectively across a wide range of tasks. Despite their central role in generation, comprehension, and recommendation systems, a comprehensive survey dedicated to discrete tokenizers remains conspicuously absent in the literature. This paper addresses this gap by providing a systematic review of the design principles, applications, and challenges of discrete tokenizers. We begin by dissecting the sub-modules of tokenizers and systematically demonstrate their internal mechanisms to provide a comprehensive understanding of their functionality and design. Building on this foundation, we synthesize state-of-the-art methods, categorizing them into multimodal generation and comprehension tasks, and semantic tokens for personalized recommendations. Furthermore, we critically analyze the limitations of existing tokenizers and outline promising directions for future research. By presenting a unified framework for understanding discrete tokenizers, this survey aims to guide researchers and practitioners in addressing open challenges and advancing the field, ultimately contributing to the development of more robust and versatile AI systems.
Value Function Decomposition in Markov Recommendation Process
Jan 29, 2025



Recent advances in recommender systems have shown that user-system interaction essentially formulates long-term optimization problems, and online reinforcement learning can be adopted to improve recommendation performance. The general solution framework incorporates a value function that estimates the user's expected cumulative rewards in the future and guides the training of the recommendation policy. To avoid local maxima, the policy may explore potential high-quality actions during inference to increase the chance of finding better future rewards. To accommodate the stepwise recommendation process, one widely adopted approach to learning the value function is learning from the difference between the values of two consecutive states of a user. However, we argue that this paradigm involves an incorrect approximation in the stochastic process. Specifically, between the current state and the next state in each training sample, there exist two separate random factors from the stochastic policy and the uncertain user environment. Original temporal difference (TD) learning under these mixed random factors may result in a suboptimal estimation of the long-term rewards. As a solution, we show that these two factors can be separately approximated by decomposing the original temporal difference loss. The disentangled learning framework can achieve a more accurate estimation with faster learning and improved robustness against action exploration. As empirical verification of our proposed method, we conduct offline experiments with online simulated environments built based on public datasets.
Future-Conditioned Recommendations with Multi-Objective Controllable Decision Transformer
Jan 13, 2025Securing long-term success is the ultimate aim of recommender systems, demanding strategies capable of foreseeing and shaping the impact of decisions on future user satisfaction. Current recommendation strategies grapple with two significant hurdles. Firstly, the future impacts of recommendation decisions remain obscured, rendering it impractical to evaluate them through direct optimization of immediate metrics. Secondly, conflicts often emerge between multiple objectives, like enhancing accuracy versus exploring diverse recommendations. Existing strategies, trapped in a "training, evaluation, and retraining" loop, grow more labor-intensive as objectives evolve. To address these challenges, we introduce a future-conditioned strategy for multi-objective controllable recommendations, allowing for the direct specification of future objectives and empowering the model to generate item sequences that align with these goals autoregressively. We present the Multi-Objective Controllable Decision Transformer (MocDT), an offline Reinforcement Learning (RL) model capable of autonomously learning the mapping from multiple objectives to item sequences, leveraging extensive offline data. Consequently, it can produce recommendations tailored to any specified objectives during the inference stage. Our empirical findings emphasize the controllable recommendation strategy's ability to produce item sequences according to different objectives while maintaining performance that is competitive with current recommendation strategies across various objectives.