 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBreaking Shortcut: Exploring Fully Convolutional Cycle-Consistency for Video Correspondence Learning
May 12, 2021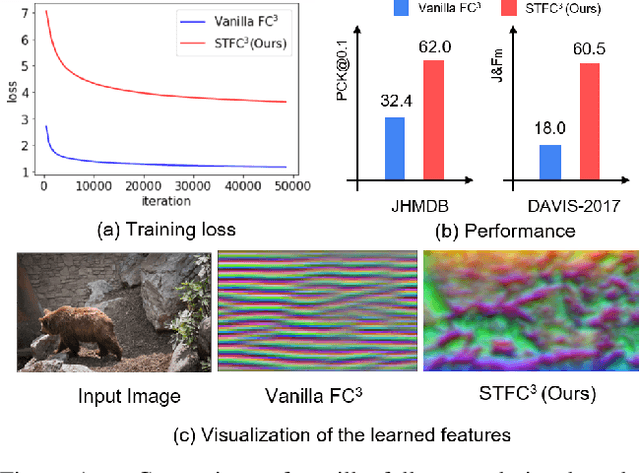
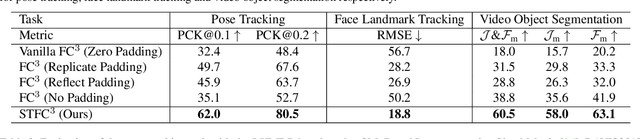
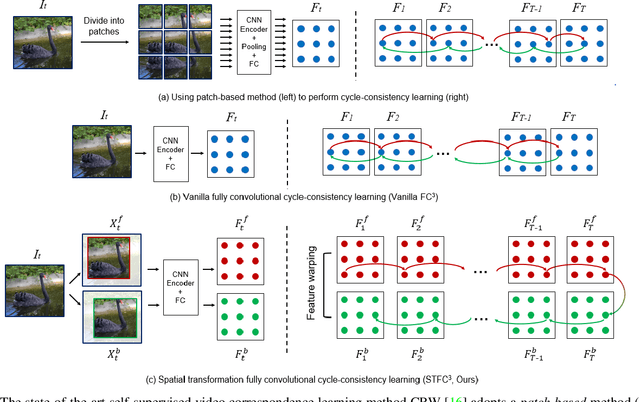
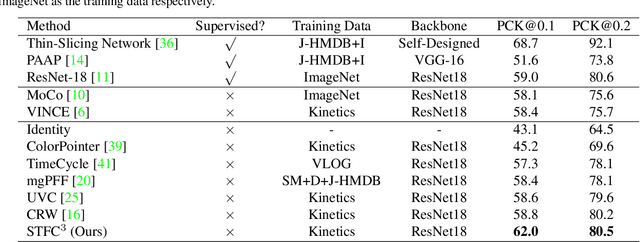
Previous cycle-consistency correspondence learning methods usually leverage image patches for training. In this paper, we present a fully convolutional method, which is simpler and more coherent to the inference process. While directly applying fully convolutional training results in model collapse, we study the underline reason behind this collapse phenomenon, indicating that the absolute positions of pixels provide a shortcut to easily accomplish cycle-consistence, which hinders the learning of meaningful visual representations. To break this absolute position shortcut, we propose to apply different crops for forward and backward frames, and adopt feature warping to establish correspondence between two crops of a same frame. The former technique enforces the corresponding pixels at forward and back tracks to have different absolute positions, and the latter effectively blocks the shortcuts going between forward and back tracks. In three label propagation benchmarks for pose tracking, face landmark tracking and video object segmentation, our method largely improves the results of vanilla fully convolutional cycle-consistency method, achieving very competitive performance compared with the self-supervised state-of-the-art approaches.
Gradient Matching for Domain Generalization
Apr 20, 2021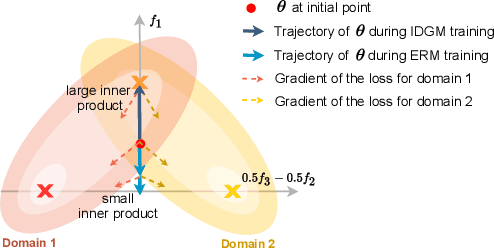


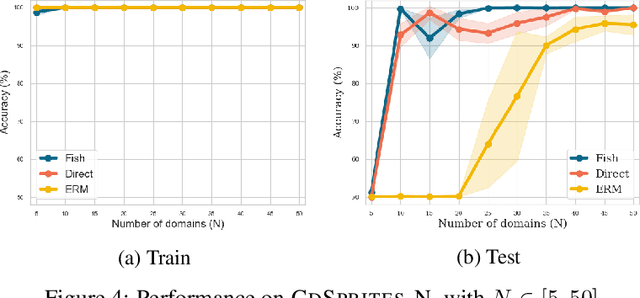
Machine learning systems typically assume that the distributions of training and test sets match closely. However, a critical requirement of such systems in the real world is their ability to generalize to unseen domains. Here, we propose an inter-domain gradient matching objective that targets domain generalization by maximizing the inner product between gradients from different domains. Since direct optimization of the gradient inner product can be computationally prohibitive -- requires computation of second-order derivatives -- we derive a simpler first-order algorithm named Fish that approximates its optimization. We demonstrate the efficacy of Fish on 6 datasets from the Wilds benchmark, which captures distribution shift across a diverse range of modalities. Our method produces competitive results on these datasets and surpasses all baselines on 4 of them. We perform experiments on both the Wilds benchmark, which captures distribution shift in the real world, as well as datasets in DomainBed benchmark that focuses more on synthetic-to-real transfer. Our method produces competitive results on both benchmarks, demonstrating its effectiveness across a wide range of domain generalization tasks.
Improved Branch and Bound for Neural Network Verification via Lagrangian Decomposition
Apr 14, 2021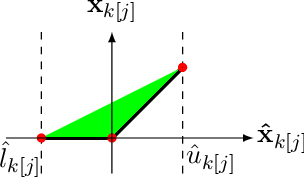
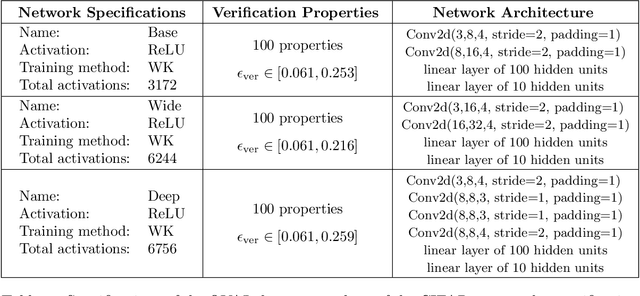
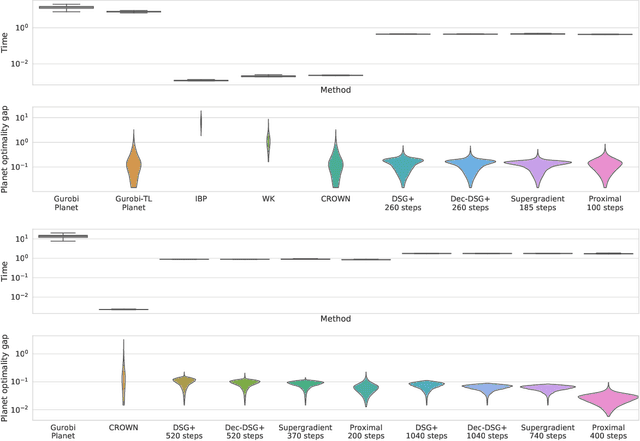
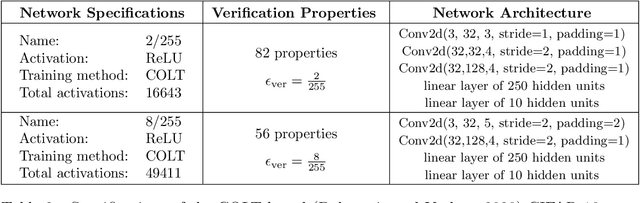
We improve the scalability of Branch and Bound (BaB) algorithms for formally proving input-output properties of neural networks. First, we propose novel bounding algorithms based on Lagrangian Decomposition. Previous works have used off-the-shelf solvers to solve relaxations at each node of the BaB tree, or constructed weaker relaxations that can be solved efficiently, but lead to unnecessarily weak bounds. Our formulation restricts the optimization to a subspace of the dual domain that is guaranteed to contain the optimum, resulting in accelerated convergence. Furthermore, it allows for a massively parallel implementation, which is amenable to GPU acceleration via modern deep learning frameworks. Second, we present a novel activation-based branching strategy. By coupling an inexpensive heuristic with fast dual bounding, our branching scheme greatly reduces the size of the BaB tree compared to previous heuristic methods. Moreover, it performs competitively with a recent strategy based on learning algorithms, without its large offline training cost. Finally, we design a BaB framework, named Branch and Dual Network Bound (BaDNB), based on our novel bounding and branching algorithms. We show that BaDNB outperforms previous complete verification systems by a large margin, cutting average verification times by factors up to 50 on adversarial robustness properties.
Cloth Interactive Transformer for Virtual Try-On
Apr 12, 20212D image-based virtual try-on has attracted increased attention from the multimedia and computer vision communities. However, most of the existing image-based virtual try-on methods directly put both person and the in-shop clothing representations together, without considering the mutual correlation between them. What is more, the long-range information, which is crucial for generating globally consistent results, is also hard to be established via the regular convolution operation. To alleviate these two problems, in this paper we propose a novel two-stage Cloth Interactive Transformer (CIT) for virtual try-on. In the first stage, we design a CIT matching block, aiming to perform a learnable thin-plate spline transformation that can capture more reasonable long-range relation. As a result, the warped in-shop clothing looks more natural. In the second stage, we propose a novel CIT reasoning block for establishing the global mutual interactive dependence. Based on this mutual dependence, the significant region within the input data can be highlighted, and consequently, the try-on results can become more realistic. Extensive experiments on a public fashion dataset demonstrate that our CIT can achieve the new state-of-the-art virtual try-on performance both qualitatively and quantitatively. The source code and trained models are available at https://github.com/Amazingren/CIT.
Combating Adversaries with Anti-Adversaries
Mar 26, 2021
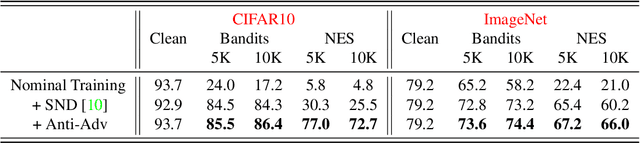
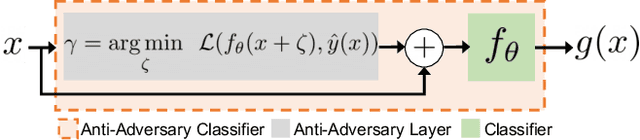
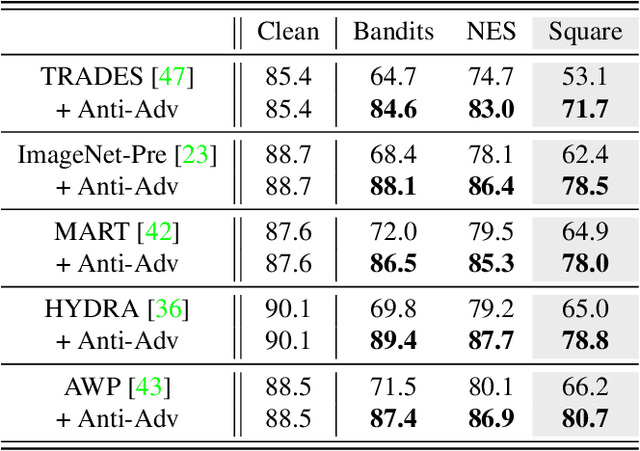
Deep neural networks are vulnerable to small input perturbations known as adversarial attacks. Inspired by the fact that these adversaries are constructed by iteratively minimizing the confidence of a network for the true class label, we propose the anti-adversary layer, aimed at countering this effect. In particular, our layer generates an input perturbation in the opposite direction of the adversarial one, and feeds the classifier a perturbed version of the input. Our approach is training-free and theoretically supported. We verify the effectiveness of our approach by combining our layer with both nominally and robustly trained models, and conduct large scale experiments from black-box to adaptive attacks on CIFAR10, CIFAR100 and ImageNet. Our anti-adversary layer significantly enhances model robustness while coming at no cost on clean accuracy.
Deterministic Neural Networks with Appropriate Inductive Biases Capture Epistemic and Aleatoric Uncertainty
Feb 23, 2021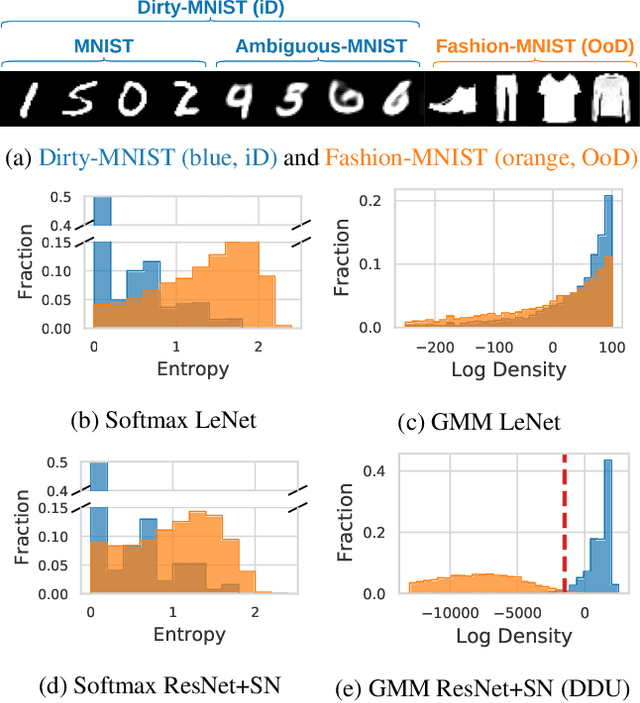

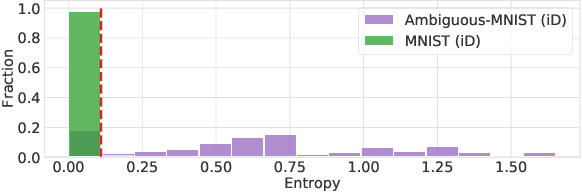
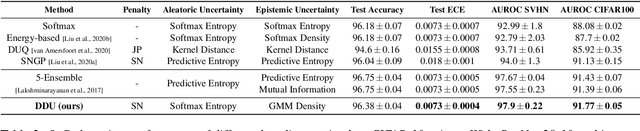
We show that a single softmax neural net with minimal changes can beat the uncertainty predictions of Deep Ensembles and other more complex single-forward-pass uncertainty approaches. Softmax neural nets cannot capture epistemic uncertainty reliably because for OoD points they extrapolate arbitrarily and suffer from feature collapse. This results in arbitrary softmax entropies for OoD points which can have high entropy, low, or anything in between. We study why, and show that with the right inductive biases, softmax neural nets trained with maximum likelihood reliably capture epistemic uncertainty through the feature-space density. This density is obtained using Gaussian Discriminant Analysis, but it cannot disentangle uncertainties. We show that it is necessary to combine this density with the softmax entropy to disentangle aleatoric and epistemic uncertainty -- crucial e.g. for active learning. We examine the quality of epistemic uncertainty on active learning and OoD detection, where we obtain SOTA ~0.98 AUROC on CIFAR-10 vs SVHN.
Shape-Tailored Deep Neural Networks
Feb 16, 2021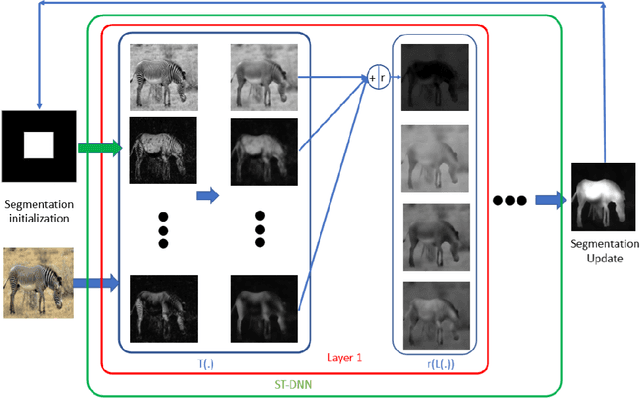
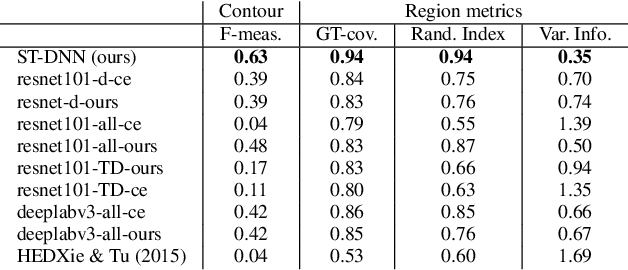
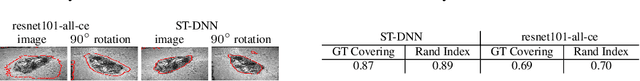

We present Shape-Tailored Deep Neural Networks (ST-DNN). ST-DNN extend convolutional networks (CNN), which aggregate data from fixed shape (square) neighborhoods, to compute descriptors defined on arbitrarily shaped regions. This is natural for segmentation, where descriptors should describe regions (e.g., of objects) that have diverse shape. We formulate these descriptors through the Poisson partial differential equation (PDE), which can be used to generalize convolution to arbitrary regions. We stack multiple PDE layers to generalize a deep CNN to arbitrary regions, and apply it to segmentation. We show that ST-DNN are covariant to translations and rotations and robust to domain deformations, natural for segmentation, which existing CNN based methods lack. ST-DNN are 3-4 orders of magnitude smaller then CNNs used for segmentation. We show that they exceed segmentation performance compared to state-of-the-art CNN-based descriptors using 2-3 orders smaller training sets on the texture segmentation problem.
Occluded Video Instance Segmentation
Feb 08, 2021
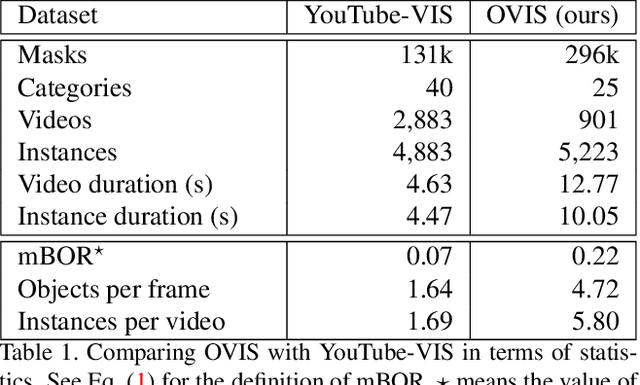

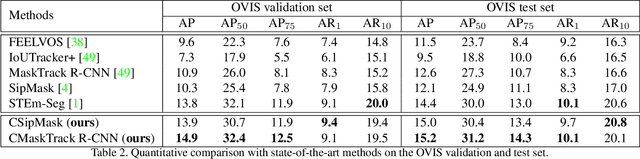
Can our video understanding systems perceive objects when a heavy occlusion exists in a scene? To answer this question, we collect a large scale dataset called OVIS for occluded video instance segmentation, that is, to simultaneously detect, segment, and track instances in occluded scenes. OVIS consists of 296k high-quality instance masks from 25 semantic categories, where object occlusions usually occur. While our human vision systems can understand those occluded instances by contextual reasoning and association, our experiments suggest that current video understanding systems are not satisfying. On the OVIS dataset, the highest AP achieved by state-of-the-art algorithms is only 14.4, which reveals that we are still at a nascent stage for understanding objects, instances, and videos in a real-world scenario. Moreover, to complement missing object cues caused by occlusion, we propose a plug-and-play module called temporal feature calibration. Built upon MaskTrack R-CNN and SipMask, we report an AP of 15.2 and 15.0 respectively. The OVIS dataset is released at http://songbai.site/ovis , and the project code will be available soon.
Scaling the Convex Barrier with Sparse Dual Algorithms
Jan 26, 2021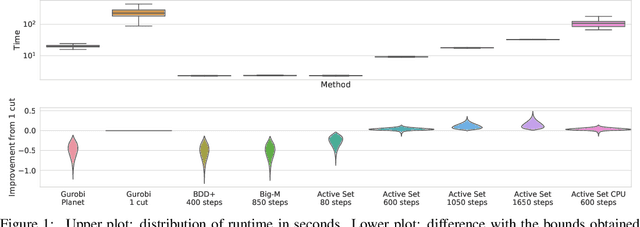
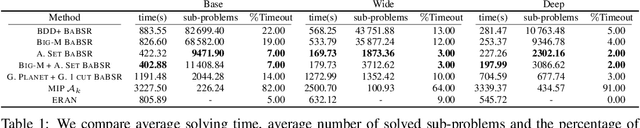
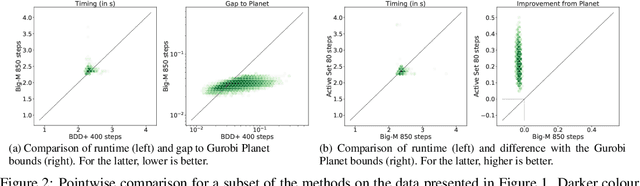
Tight and efficient neural network bounding is crucial to the scaling of neural network verification systems. Many efficient bounding algorithms have been presented recently, but they are often too loose to verify more challenging properties. This is due to the weakness of the employed relaxation, which is usually a linear program of size linear in the number of neurons. While a tighter linear relaxation for piecewise-linear activations exists, it comes at the cost of exponentially many constraints and currently lacks an efficient customized solver. We alleviate this deficiency by presenting two novel dual algorithms: one operates a subgradient method on a small active set of dual variables, the other exploits the sparsity of Frank-Wolfe type optimizers to incur only a linear memory cost. Both methods recover the strengths of the new relaxation: tightness and a linear separation oracle. At the same time, they share the benefits of previous dual approaches for weaker relaxations: massive parallelism, GPU implementation, low cost per iteration and valid bounds at any time. As a consequence, we can obtain better bounds than off-the-shelf solvers in only a fraction of their running time, attaining significant formal verification speed-ups.
Rethinking Semantic Segmentation from a Sequence-to-Sequence Perspective with Transformers
Dec 31, 2020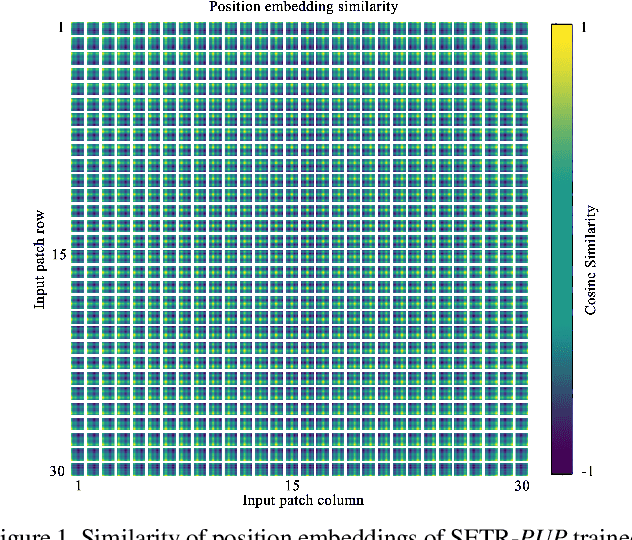



Most recent semantic segmentation methods adopt a fully-convolutional network (FCN) with an encoder-decoder architecture. The encoder progressively reduces the spatial resolution and learns more abstract/semantic visual concepts with larger receptive fields. Since context modeling is critical for segmentation, the latest efforts have been focused on increasing the receptive field, through either dilated/atrous convolutions or inserting attention modules. However, the encoder-decoder based FCN architecture remains unchanged. In this paper, we aim to provide an alternative perspective by treating semantic segmentation as a sequence-to-sequence prediction task. Specifically, we deploy a pure transformer (ie, without convolution and resolution reduction) to encode an image as a sequence of patches. With the global context modeled in every layer of the transformer, this encoder can be combined with a simple decoder to provide a powerful segmentation model, termed SEgmentation TRansformer (SETR). Extensive experiments show that SETR achieves new state of the art on ADE20K (50.28% mIoU), Pascal Context (55.83% mIoU) and competitive results on Cityscapes. Particularly, we achieve the first (44.42% mIoU) position in the highly competitive ADE20K test server leaderboard.