 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixture of States: Routing Token-Level Dynamics for Multimodal Generation
Nov 15, 2025We introduce MoS (Mixture of States), a novel fusion paradigm for multimodal diffusion models that merges modalities using flexible, state-based interactions. The core of MoS is a learnable, token-wise router that creates denoising timestep- and input-dependent interactions between modalities' hidden states, precisely aligning token-level features with the diffusion trajectory. This router sparsely selects the top-$k$ hidden states and is trained with an $ε$-greedy strategy, efficiently selecting contextual features with minimal learnable parameters and negligible computational overhead. We validate our design with text-to-image generation (MoS-Image) and editing (MoS-Editing), which achieve state-of-the-art results. With only 3B to 5B parameters, our models match or surpass counterparts up to $4\times$ larger. These findings establish MoS as a flexible and compute-efficient paradigm for scaling multimodal diffusion models.
MarDini: Masked Autoregressive Diffusion for Video Generation at Scale
Oct 26, 2024



We introduce MarDini, a new family of video diffusion models that integrate the advantages of masked auto-regression (MAR) into a unified diffusion model (DM) framework. Here, MAR handles temporal planning, while DM focuses on spatial generation in an asymmetric network design: i) a MAR-based planning model containing most of the parameters generates planning signals for each masked frame using low-resolution input; ii) a lightweight generation model uses these signals to produce high-resolution frames via diffusion de-noising. MarDini's MAR enables video generation conditioned on any number of masked frames at any frame positions: a single model can handle video interpolation (e.g., masking middle frames), image-to-video generation (e.g., masking from the second frame onward), and video expansion (e.g., masking half the frames). The efficient design allocates most of the computational resources to the low-resolution planning model, making computationally expensive but important spatio-temporal attention feasible at scale. MarDini sets a new state-of-the-art for video interpolation; meanwhile, within few inference steps, it efficiently generates videos on par with those of much more expensive advanced image-to-video models.
Deep Learning at the Intersection: Certified Robustness as a Tool for 3D Vision
Aug 23, 2024



This paper presents preliminary work on a novel connection between certified robustness in machine learning and the modeling of 3D objects. We highlight an intriguing link between the Maximal Certified Radius (MCR) of a classifier representing a space's occupancy and the space's Signed Distance Function (SDF). Leveraging this relationship, we propose to use the certification method of randomized smoothing (RS) to compute SDFs. Since RS' high computational cost prevents its practical usage as a way to compute SDFs, we propose an algorithm to efficiently run RS in low-dimensional applications, such as 3D space, by expressing RS' fundamental operations as Gaussian smoothing on pre-computed voxel grids. Our approach offers an innovative and practical tool to compute SDFs, validated through proof-of-concept experiments in novel view synthesis. This paper bridges two previously disparate areas of machine learning, opening new avenues for further exploration and potential cross-domain advancements.
Compressed-Language Models for Understanding Compressed File Formats: a JPEG Exploration
May 27, 2024This study investigates whether Compressed-Language Models (CLMs), i.e. language models operating on raw byte streams from Compressed File Formats~(CFFs), can understand files compressed by CFFs. We focus on the JPEG format as a representative CFF, given its commonality and its representativeness of key concepts in compression, such as entropy coding and run-length encoding. We test if CLMs understand the JPEG format by probing their capabilities to perform along three axes: recognition of inherent file properties, handling of files with anomalies, and generation of new files. Our findings demonstrate that CLMs can effectively perform these tasks. These results suggest that CLMs can understand the semantics of compressed data when directly operating on the byte streams of files produced by CFFs. The possibility to directly operate on raw compressed files offers the promise to leverage some of their remarkable characteristics, such as their ubiquity, compactness, multi-modality and segment-nature.
Adaptive Guidance: Training-free Acceleration of Conditional Diffusion Models
Dec 19, 2023This paper presents a comprehensive study on the role of Classifier-Free Guidance (CFG) in text-conditioned diffusion models from the perspective of inference efficiency. In particular, we relax the default choice of applying CFG in all diffusion steps and instead search for efficient guidance policies. We formulate the discovery of such policies in the differentiable Neural Architecture Search framework. Our findings suggest that the denoising steps proposed by CFG become increasingly aligned with simple conditional steps, which renders the extra neural network evaluation of CFG redundant, especially in the second half of the denoising process. Building upon this insight, we propose "Adaptive Guidance" (AG), an efficient variant of CFG, that adaptively omits network evaluations when the denoising process displays convergence. Our experiments demonstrate that AG preserves CFG's image quality while reducing computation by 25%. Thus, AG constitutes a plug-and-play alternative to Guidance Distillation, achieving 50% of the speed-ups of the latter while being training-free and retaining the capacity to handle negative prompts. Finally, we uncover further redundancies of CFG in the first half of the diffusion process, showing that entire neural function evaluations can be replaced by simple affine transformations of past score estimates. This method, termed LinearAG, offers even cheaper inference at the cost of deviating from the baseline model. Our findings provide insights into the efficiency of the conditional denoising process that contribute to more practical and swift deployment of text-conditioned diffusion models.
Enhancing Neural Rendering Methods with Image Augmentations
Jun 15, 2023



Faithfully reconstructing 3D geometry and generating novel views of scenes are critical tasks in 3D computer vision. Despite the widespread use of image augmentations across computer vision applications, their potential remains underexplored when learning neural rendering methods (NRMs) for 3D scenes. This paper presents a comprehensive analysis of the use of image augmentations in NRMs, where we explore different augmentation strategies. We found that introducing image augmentations during training presents challenges such as geometric and photometric inconsistencies for learning NRMs from images. Specifically, geometric inconsistencies arise from alterations in shapes, positions, and orientations from the augmentations, disrupting spatial cues necessary for accurate 3D reconstruction. On the other hand, photometric inconsistencies arise from changes in pixel intensities introduced by the augmentations, affecting the ability to capture the underlying 3D structures of the scene. We alleviate these issues by focusing on color manipulations and introducing learnable appearance embeddings that allow NRMs to explain away photometric variations. Our experiments demonstrate the benefits of incorporating augmentations when learning NRMs, including improved photometric quality and surface reconstruction, as well as enhanced robustness against data quality issues, such as reduced training data and image degradations.
Revisiting Test Time Adaptation under Online Evaluation
Apr 10, 2023



This paper proposes a novel online evaluation protocol for Test Time Adaptation (TTA) methods, which penalizes slower methods by providing them with fewer samples for adaptation. TTA methods leverage unlabeled data at test time to adapt to distribution shifts. Though many effective methods have been proposed, their impressive performance usually comes at the cost of significantly increased computation budgets. Current evaluation protocols overlook the effect of this extra computation cost, affecting their real-world applicability. To address this issue, we propose a more realistic evaluation protocol for TTA methods, where data is received in an online fashion from a constant-speed data stream, thereby accounting for the method's adaptation speed. We apply our proposed protocol to benchmark several TTA methods on multiple datasets and scenarios. Extensive experiments shows that, when accounting for inference speed, simple and fast approaches can outperform more sophisticated but slower methods. For example, SHOT from 2020 outperforms the state-of-the-art method SAR from 2023 under our online setting. Our online evaluation protocol emphasizes the need for developing TTA methods that are efficient and applicable in realistic settings.
Certified Robustness in Federated Learning
Jun 06, 2022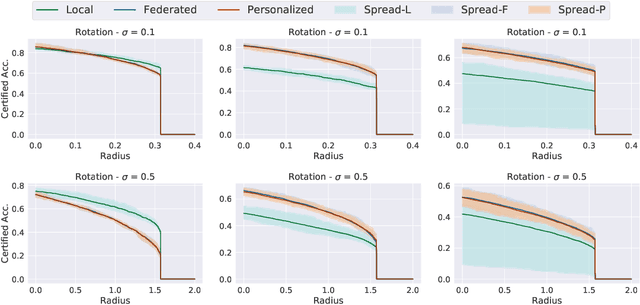
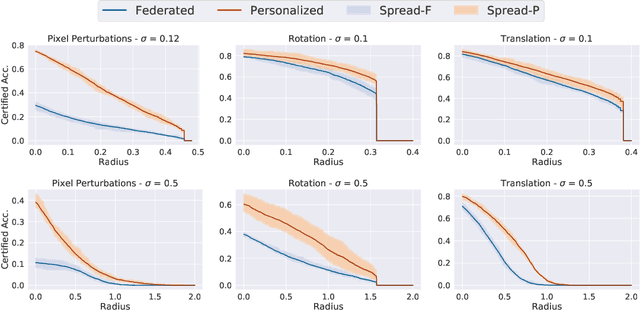

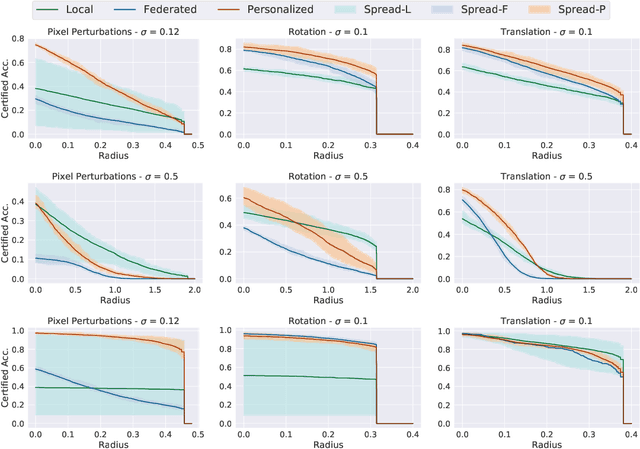
Federated learning has recently gained significant attention and popularity due to its effectiveness in training machine learning models on distributed data privately. However, as in the single-node supervised learning setup, models trained in federated learning suffer from vulnerability to imperceptible input transformations known as adversarial attacks, questioning their deployment in security-related applications. In this work, we study the interplay between federated training, personalization, and certified robustness. In particular, we deploy randomized smoothing, a widely-used and scalable certification method, to certify deep networks trained on a federated setup against input perturbations and transformations. We find that the simple federated averaging technique is effective in building not only more accurate, but also more certifiably-robust models, compared to training solely on local data. We further analyze personalization, a popular technique in federated training that increases the model's bias towards local data, on robustness. We show several advantages of personalization over both~(that is, only training on local data and federated training) in building more robust models with faster training. Finally, we explore the robustness of mixtures of global and local~(\ie personalized) models, and find that the robustness of local models degrades as they diverge from the global model
3DeformRS: Certifying Spatial Deformations on Point Clouds
Apr 12, 2022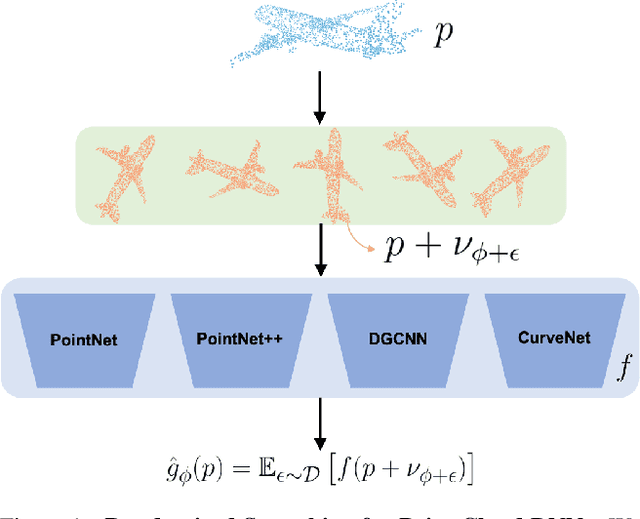



3D computer vision models are commonly used in security-critical applications such as autonomous driving and surgical robotics. Emerging concerns over the robustness of these models against real-world deformations must be addressed practically and reliably. In this work, we propose 3DeformRS, a method to certify the robustness of point cloud Deep Neural Networks (DNNs) against real-world deformations. We developed 3DeformRS by building upon recent work that generalized Randomized Smoothing (RS) from pixel-intensity perturbations to vector-field deformations. In particular, we specialized RS to certify DNNs against parameterized deformations (e.g. rotation, twisting), while enjoying practical computational costs. We leverage the virtues of 3DeformRS to conduct a comprehensive empirical study on the certified robustness of four representative point cloud DNNs on two datasets and against seven different deformations. Compared to previous approaches for certifying point cloud DNNs, 3DeformRS is fast, scales well with point cloud size, and provides comparable-to-better certificates. For instance, when certifying a plain PointNet against a 3{\deg} z-rotation on 1024-point clouds, 3DeformRS grants a certificate 3x larger and 20x faster than previous work.
Towards Assessing and Characterizing the Semantic Robustness of Face Recognition
Feb 10, 2022Deep Neural Networks (DNNs) lack robustness against imperceptible perturbations to their input. Face Recognition Models (FRMs) based on DNNs inherit this vulnerability. We propose a methodology for assessing and characterizing the robustness of FRMs against semantic perturbations to their input. Our methodology causes FRMs to malfunction by designing adversarial attacks that search for identity-preserving modifications to faces. In particular, given a face, our attacks find identity-preserving variants of the face such that an FRM fails to recognize the images belonging to the same identity. We model these identity-preserving semantic modifications via direction- and magnitude-constrained perturbations in the latent space of StyleGAN. We further propose to characterize the semantic robustness of an FRM by statistically describing the perturbations that induce the FRM to malfunction. Finally, we combine our methodology with a certification technique, thus providing (i) theoretical guarantees on the performance of an FRM, and (ii) a formal description of how an FRM may model the notion of face identity.