 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePILOT: Policy-Informed Learned Optimization for Adaptive Deep Network Training
May 23, 2026Despite the central role of optimization in deep learning, most optimizers rely on update structures whose functional form is fixed before training begins. This static design can limit their ability to respond to changing gradient behavior across the loss landscape, where training may shift between stable, noisy, and inconsistent regimes. This study proposes PILOT (Policy-Informed Learned OpTimizer), an online optimizer that adapts its update behavior during training. Rather than using a fixed balance between momentum, normalization, and sign-based updates, PILOT uses gradient-direction agreement as a signal of local training stability. Conditioning the update rule on this agreement signal allows the optimizer to adjust its behavior when gradients become stable, noisy, or inconsistent. Experiments on FashionMNIST and CIFAR-10 show that PILOT consistently achieves the highest accuracy among the evaluated optimizers across convolutional settings. On the CNN architecture, PILOT reaches 94.13% on FashionMNIST and 81.94% on CIFAR-10. On ResNet-18, it further improves performance, reaching 95.71% on FashionMNIST and 93.42% on CIFAR-10. These results suggest that learning how to adapt the update structure during training can improve performance across both compact and deeper convolutional models while preserving a simple first-order optimization framework. The implementation of PILOT is publicly available at https://github.com/SattamAltwaim/PILOT.git
GridProbe: Posterior-Probing for Adaptive Test-Time Compute in Long-Video VLMs
May 11, 2026Long-video understanding in VLMs is bottlenecked by a single monolithic forward pass over thousands of frames at quadratic attention cost. A common mitigation is to first select a small subset of informative frames before the forward pass; common for training-free selectors via auxiliary encoder-space similarities. Such signals are capped by contrastive pretraining, which usually fails on reasoning-heavy queries (negation, cross-frame counting, holistic summarization). We propose GridProbe, an efficient training-free posterior-probing inference paradigm that scores evidence in answer space using a frozen VLM's own reasoning and then selects question-relevant frames adaptively, resulting in sub-quadratic attention cost with little to no accuracy loss. We arrange frames on a $K{\times}K$ grid and run lightweight row R and column C probes, where each probe reads its peak posterior as a query-conditioned confidence. The outer product of R and C yields an interpretable importance map whose skewness and kurtosis drive Shape-Adaptive Selection, a closed-form rule that reliably replaces the fixed frame budget $M$ with a per-question $M_{\mathrm{eff}}$. We show empirically that $M_{\mathrm{eff}}$ tracks intrinsic question difficulty without ever seeing the answer, a sign of test-time adaptive compute. On Video-MME-v2, GridProbe matches the monolithic baseline within $1.6$ pp Avg Acc at $3.36\times$ TFLOPs reduction, while on LongVideoBench it Pareto-dominates the baseline ($+0.9$ pp at $0.35\times$ compute). Because the selector and QA models can be decoupled, pairing a small 2B selector with a stronger 4B or 8B QA is strictly Pareto-dominant over the 2B monolithic baseline (up to $+4.0$ pp at $0.52\times$ compute, on average), with no retraining. Finally, the interpretability of the importance maps opens future avenues for behavioral diagnostics, grounding, and frame-selection distillation.
VideoAtlas: Navigating Long-Form Video in Logarithmic Compute
Mar 18, 2026Extending language models to video introduces two challenges: representation, where existing methods rely on lossy approximations, and long-context, where caption- or agent-based pipelines collapse video into text and lose visual fidelity. To overcome this, we introduce \textbf{VideoAtlas}, a task-agnostic environment to represent video as a hierarchical grid that is simultaneously lossless, navigable, scalable, caption- and preprocessing-free. An overview of the video is available at a glance, and any region can be recursively zoomed into, with the same visual representation used uniformly for the video, intermediate investigations, and the agent's memory, eliminating lossy text conversion end-to-end. This hierarchical structure ensures access depth grows only logarithmically with video length. For long-context, Recursive Language Models (RLMs) recently offered a powerful solution for long text, but extending them to visual domain requires a structured environment to recurse into, which \textbf{VideoAtlas} provides. \textbf{VideoAtlas} as a Markov Decision Process unlocks Video-RLM: a parallel Master-Worker architecture where a Master coordinates global exploration while Workers concurrently drill into assigned regions to accumulate lossless visual evidence. We demonstrate three key findings: (1)~logarithmic compute growth with video duration, further amplified by a 30-60\% multimodal cache hit rate arising from the grid's structural reuse. (2)~environment budgeting, where bounding the maximum exploration depth provides a principled compute-accuracy hyperparameter. (3)~emergent adaptive compute allocation that scales with question granularity. When scaling from 1-hour to 10-hour benchmarks, Video-RLM remains the most duration-robust method with minimal accuracy degradation, demonstrating that structured environment navigation is a viable and scalable paradigm for video understanding.
Detecting and Quantifying Malicious Activity with Simulation-based Inference
Oct 07, 2021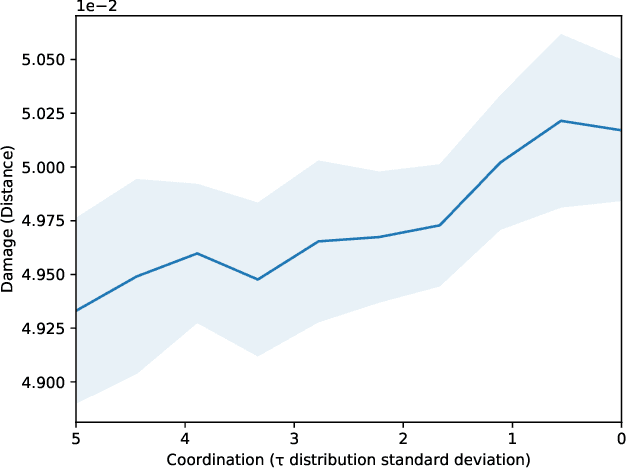
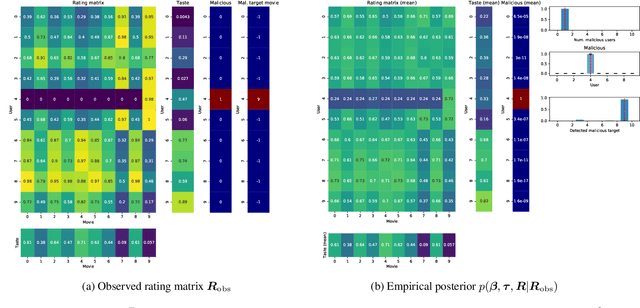
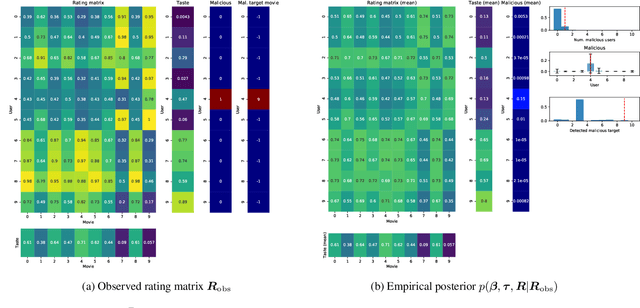
We propose the use of probabilistic programming techniques to tackle the malicious user identification problem in a recommendation algorithm. Probabilistic programming provides numerous advantages over other techniques, including but not limited to providing a disentangled representation of how malicious users acted under a structured model, as well as allowing for the quantification of damage caused by malicious users. We show experiments in malicious user identification using a model of regular and malicious users interacting with a simple recommendation algorithm, and provide a novel simulation-based measure for quantifying the effects of a user or group of users on its dynamics.
Class-Agnostic Segmentation Loss and Its Application to Salient Object Detection and Segmentation
Jul 16, 2021
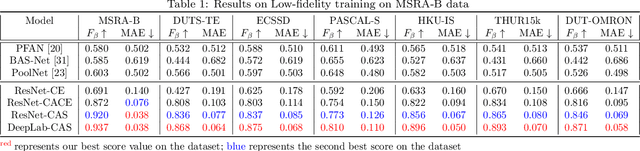

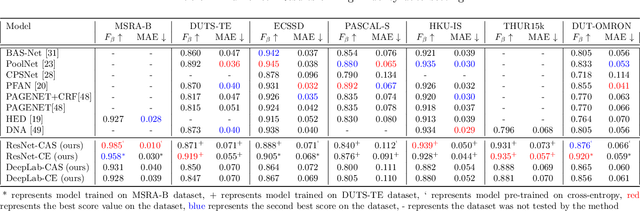
In this paper we present a novel loss function, called class-agnostic segmentation (CAS) loss. With CAS loss the class descriptors are learned during training of the network. We don't require to define the label of a class a-priori, rather the CAS loss clusters regions with similar appearance together in a weakly-supervised manner. Furthermore, we show that the CAS loss function is sparse, bounded, and robust to class-imbalance. We first apply our CAS loss function with fully-convolutional ResNet101 and DeepLab-v3 architectures to the binary segmentation problem of salient object detection. We investigate the performance against the state-of-the-art methods in two settings of low and high-fidelity training data on seven salient object detection datasets. For low-fidelity training data (incorrect class label) class-agnostic segmentation loss outperforms the state-of-the-art methods on salient object detection datasets by staggering margins of around 50%. For high-fidelity training data (correct class labels) class-agnostic segmentation models perform as good as the state-of-the-art approaches while beating the state-of-the-art methods on most datasets. In order to show the utility of the loss function across different domains we then also test on general segmentation dataset, where class-agnostic segmentation loss outperforms competing losses by huge margins.
DeformRS: Certifying Input Deformations with Randomized Smoothing
Jul 02, 2021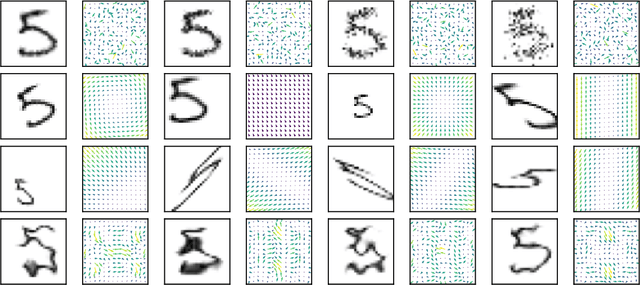


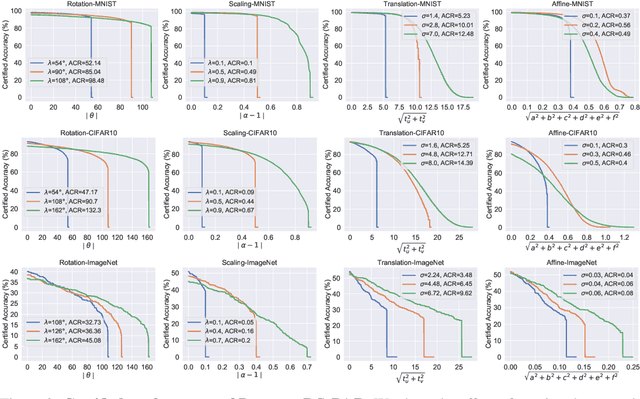
Deep neural networks are vulnerable to input deformations in the form of vector fields of pixel displacements and to other parameterized geometric deformations e.g. translations, rotations, etc. Current input deformation certification methods either (i) do not scale to deep networks on large input datasets, or (ii) can only certify a specific class of deformations, e.g. only rotations. We reformulate certification in randomized smoothing setting for both general vector field and parameterized deformations and propose DeformRS-VF and DeformRS-Par, respectively. Our new formulation scales to large networks on large input datasets. For instance, DeformRS-Par certifies rich deformations, covering translations, rotations, scaling, affine deformations, and other visually aligned deformations such as ones parameterized by Discrete-Cosine-Transform basis. Extensive experiments on MNIST, CIFAR10 and ImageNet show that DeformRS-Par outperforms existing state-of-the-art in certified accuracy, e.g. improved certified accuracy of 6% against perturbed rotations in the set [-10,10] degrees on ImageNet.
Shape-Tailored Deep Neural Networks
Feb 16, 2021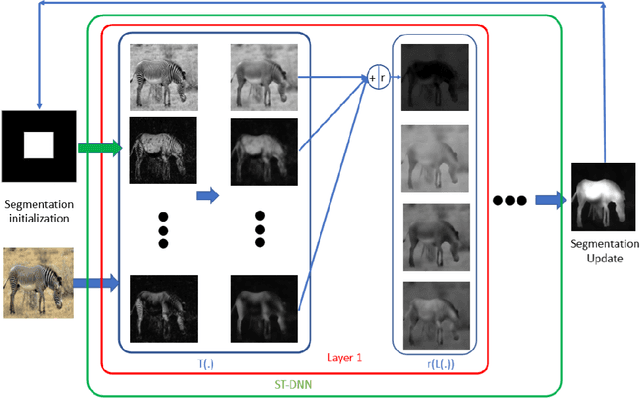
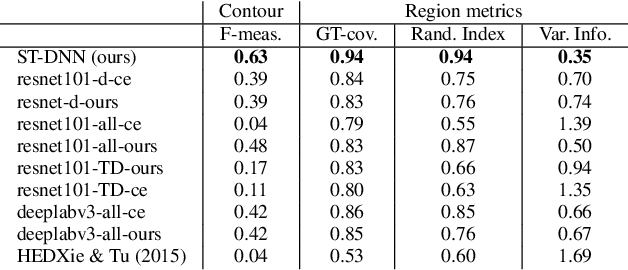
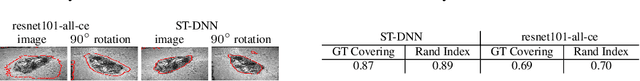

We present Shape-Tailored Deep Neural Networks (ST-DNN). ST-DNN extend convolutional networks (CNN), which aggregate data from fixed shape (square) neighborhoods, to compute descriptors defined on arbitrarily shaped regions. This is natural for segmentation, where descriptors should describe regions (e.g., of objects) that have diverse shape. We formulate these descriptors through the Poisson partial differential equation (PDE), which can be used to generalize convolution to arbitrary regions. We stack multiple PDE layers to generalize a deep CNN to arbitrary regions, and apply it to segmentation. We show that ST-DNN are covariant to translations and rotations and robust to domain deformations, natural for segmentation, which existing CNN based methods lack. ST-DNN are 3-4 orders of magnitude smaller then CNNs used for segmentation. We show that they exceed segmentation performance compared to state-of-the-art CNN-based descriptors using 2-3 orders smaller training sets on the texture segmentation problem.
Continual Learning in Low-rank Orthogonal Subspaces
Oct 22, 2020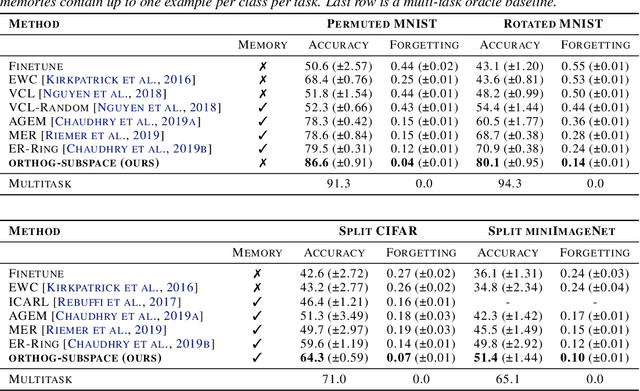

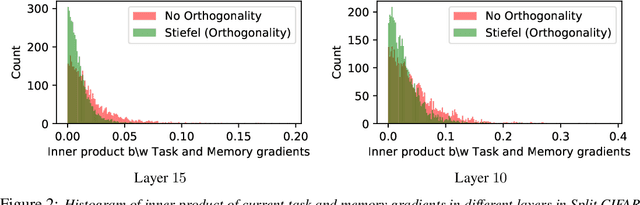
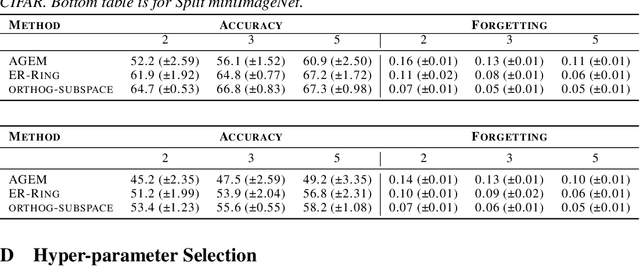
In continual learning (CL), a learner is faced with a sequence of tasks, arriving one after the other, and the goal is to remember all the tasks once the continual learning experience is finished. The prior art in CL uses episodic memory, parameter regularization or extensible network structures to reduce interference among tasks, but in the end, all the approaches learn different tasks in a joint vector space. We believe this invariably leads to interference among different tasks. We propose to learn tasks in different (low-rank) vector subspaces that are kept orthogonal to each other in order to minimize interference. Further, to keep the gradients of different tasks coming from these subspaces orthogonal to each other, we learn isometric mappings by posing network training as an optimization problem over the Stiefel manifold. To the best of our understanding, we report, for the first time, strong results over experience-replay baseline with and without memory on standard classification benchmarks in continual learning. The code is made publicly available.
* The paper is accepted at NeurIPS'20
Coarse-to-Fine Segmentation With Shape-Tailored Scale Spaces
Mar 24, 2016
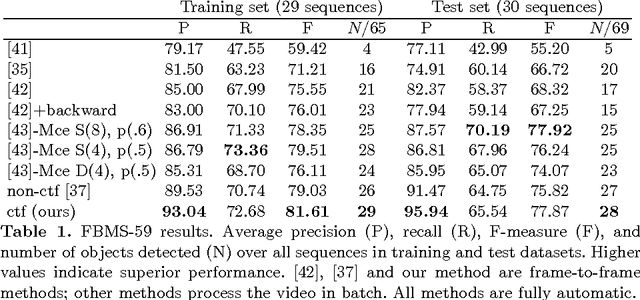

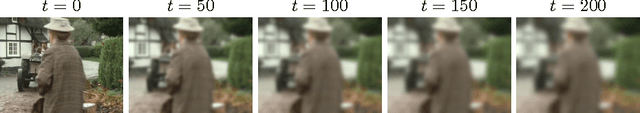
We formulate a general energy and method for segmentation that is designed to have preference for segmenting the coarse structure over the fine structure of the data, without smoothing across boundaries of regions. The energy is formulated by considering data terms at a continuum of scales from the scale space computed from the Heat Equation within regions, and integrating these terms over all time. We show that the energy may be approximately optimized without solving for the entire scale space, but rather solving time-independent linear equations at the native scale of the image, making the method computationally feasible. We provide a multi-region scheme, and apply our method to motion segmentation. Experiments on a benchmark dataset shows that our method is less sensitive to clutter or other undesirable fine-scale structure, and leads to better performance in motion segmentation.