 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Low-Rank Subspace Analysis of LLM Interventions
Jun 12, 2026Interventions designed to modify a particular behavior in LLMs, such as refusal or sycophancy, often produce unintended changes in other behaviors. This lack of targeted control makes it difficult to design and implement reliable safety controls. To understand these side-effects, we introduce a diagnostic framework for analyzing interacting behaviors in LLMs. We model behaviors as low-rank subspaces in activation space, and study how interventions influence across behaviors. Across multiple instruction-tuned models (7B-70B) and across refusal, jailbreak, and sycophancy settings, we find that different behaviors share internal representations, and intervening on one behavior alters others in asymmetric ways. Some behaviors act as upstream control points whose interventions propagate broadly across other behaviors, while others remain more isolated. We relate these effects to two geometric quantities: (i) the overlap between behavior subspaces, measured as the average squared cosine of principal angles, and (ii) the angle between each behavior subspace and the decision subspace (capturing the model's final decision e.g., refuse vs. comply). Empirically, intervention effects on other behaviors tend to be larger for behavior pairs with higher subspace overlap, and for source behaviors whose subspaces lie closer (smaller angle) to the decision subspace. These findings highlight a challenge for targeted behavior control: behaviors are difficult to modify independently, as interventions can propagate through shared representations and asymmetric interactions.
When Language Representations Interact: Separability and Cross-Lingual Effects in LLMs
Jun 12, 2026Large language models exhibit strong multilingual capabilities, however, their internal representations are difficult to interpret. Understanding these interactions is important for ensuring reliable behavior in multilingual systems. Recent work has shown that causal-geometric structure can explain how certain concepts are encoded as approximately linear and separable directions, but whether this framework extends to multilingual models, where language identity is correlated and hierarchical, is underexplored. We apply causal-geometric analysis to multilingual LLMs, studying 28 bilingual contrasts across three models, allowing us to analyze when languages behave as approximately independent factors and when structured dependencies persist. We find evidence that language concepts admit stable linear representations that are largely separable under a covariance-adjusted (causal) inner product, with structured deviations reflecting linguistic similarity. Moreover, languages within the same family (such as Germanic or Romance) exhibit a simplex-like geometric structure, suggesting hierarchical organization. These results extend causal-geometric interpretability to multilingual settings and provide insight into how separability and similarity may exist in multilingual LLM representations, motivating interpretability analyses that diagnose when and how structured dependencies between concepts can be anticipated. This has implications for trustworthy deployment, as residual structure between languages may lead to unintended cross-lingual effects when models are monitored or intervened upon.
Class-Agnostic Segmentation Loss and Its Application to Salient Object Detection and Segmentation
Jul 16, 2021
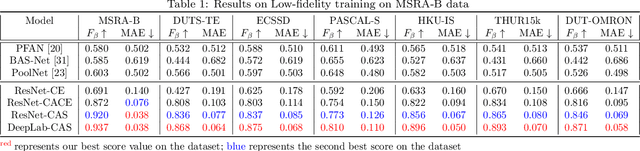

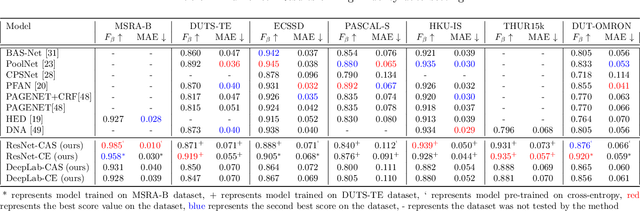
In this paper we present a novel loss function, called class-agnostic segmentation (CAS) loss. With CAS loss the class descriptors are learned during training of the network. We don't require to define the label of a class a-priori, rather the CAS loss clusters regions with similar appearance together in a weakly-supervised manner. Furthermore, we show that the CAS loss function is sparse, bounded, and robust to class-imbalance. We first apply our CAS loss function with fully-convolutional ResNet101 and DeepLab-v3 architectures to the binary segmentation problem of salient object detection. We investigate the performance against the state-of-the-art methods in two settings of low and high-fidelity training data on seven salient object detection datasets. For low-fidelity training data (incorrect class label) class-agnostic segmentation loss outperforms the state-of-the-art methods on salient object detection datasets by staggering margins of around 50%. For high-fidelity training data (correct class labels) class-agnostic segmentation models perform as good as the state-of-the-art approaches while beating the state-of-the-art methods on most datasets. In order to show the utility of the loss function across different domains we then also test on general segmentation dataset, where class-agnostic segmentation loss outperforms competing losses by huge margins.
Shape-Tailored Deep Neural Networks
Feb 16, 2021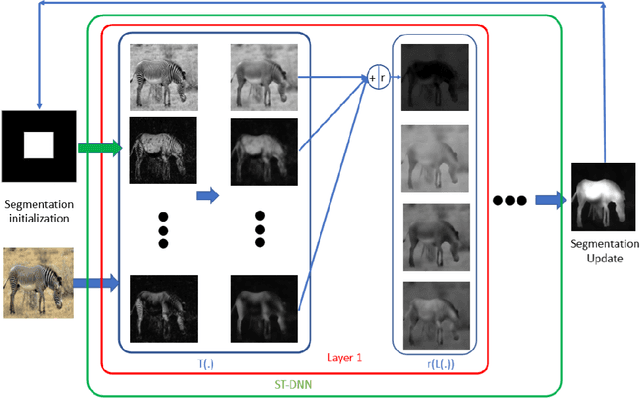
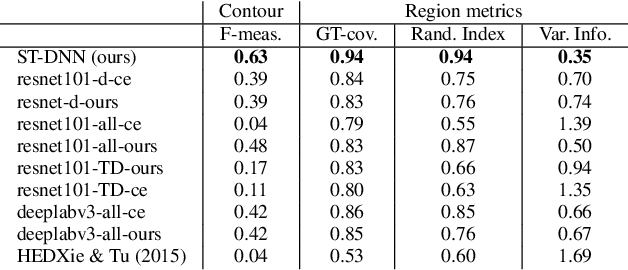
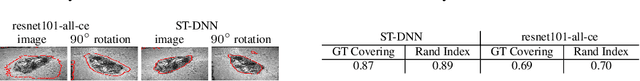

We present Shape-Tailored Deep Neural Networks (ST-DNN). ST-DNN extend convolutional networks (CNN), which aggregate data from fixed shape (square) neighborhoods, to compute descriptors defined on arbitrarily shaped regions. This is natural for segmentation, where descriptors should describe regions (e.g., of objects) that have diverse shape. We formulate these descriptors through the Poisson partial differential equation (PDE), which can be used to generalize convolution to arbitrary regions. We stack multiple PDE layers to generalize a deep CNN to arbitrary regions, and apply it to segmentation. We show that ST-DNN are covariant to translations and rotations and robust to domain deformations, natural for segmentation, which existing CNN based methods lack. ST-DNN are 3-4 orders of magnitude smaller then CNNs used for segmentation. We show that they exceed segmentation performance compared to state-of-the-art CNN-based descriptors using 2-3 orders smaller training sets on the texture segmentation problem.
Digital Twins: State of the Art Theory and Practice, Challenges, and Open Research Questions
Nov 06, 2020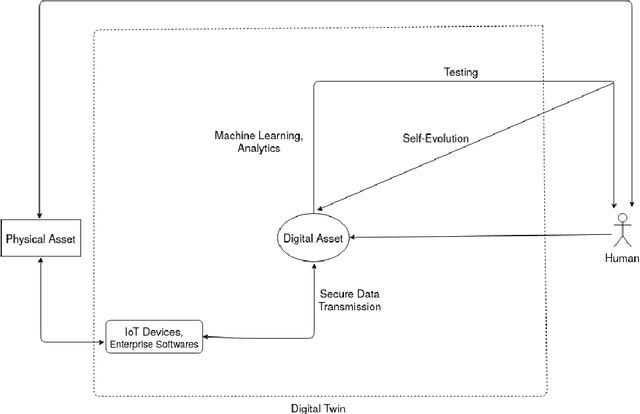
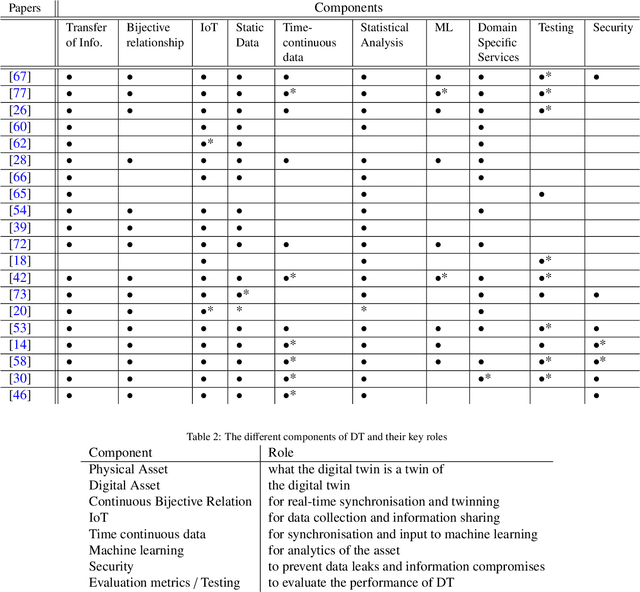
Digital Twin was introduced over a decade ago, as an innovative all-encompassing tool, with perceived benefits including real-time monitoring, simulation and forecasting. However, the theoretical framework and practical implementations of digital twins (DT) are still far from this vision. Although successful implementations exist, sufficient implementation details are not publicly available, therefore it is difficult to assess their effectiveness, draw comparisons and jointly advance the DT methodology. This work explores the various DT features and current approaches, the shortcomings and reasons behind the delay in the implementation and adoption of digital twin. Advancements in machine learning, internet of things and big data have contributed hugely to the improvements in DT with regards to its real-time monitoring and forecasting properties. Despite this progress and individual company-based efforts, certain research gaps exist in the field, which have caused delay in the widespread adoption of this concept. We reviewed relevant works and identified that the major reasons for this delay are the lack of a universal reference framework, domain dependence, security concerns of shared data, reliance of digital twin on other technologies, and lack of quantitative metrics. We define the necessary components of a digital twin required for a universal reference framework, which also validate its uniqueness as a concept compared to similar concepts like simulation, autonomous systems, etc. This work further assesses the digital twin applications in different domains and the current state of machine learning and big data in it. It thus answers and identifies novel research questions, both of which will help to better understand and advance the theory and practice of digital twins.