 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFRIH: Fine-grained Region-aware Image Harmonization
May 13, 2022

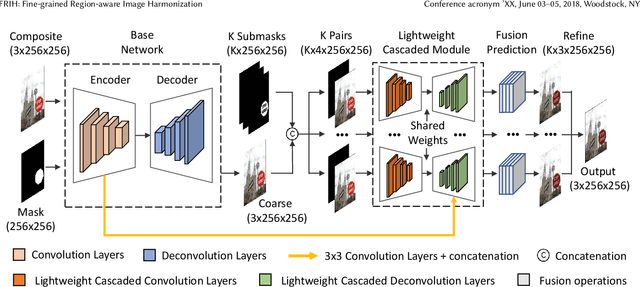
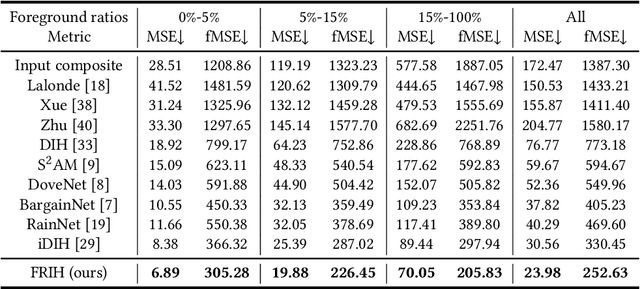
Image harmonization aims to generate a more realistic appearance of foreground and background for a composite image. Existing methods perform the same harmonization process for the whole foreground. However, the implanted foreground always contains different appearance patterns. All the existing solutions ignore the difference of each color block and losing some specific details. Therefore, we propose a novel global-local two stages framework for Fine-grained Region-aware Image Harmonization (FRIH), which is trained end-to-end. In the first stage, the whole input foreground mask is used to make a global coarse-grained harmonization. In the second stage, we adaptively cluster the input foreground mask into several submasks by the corresponding pixel RGB values in the composite image. Each submask and the coarsely adjusted image are concatenated respectively and fed into a lightweight cascaded module, adjusting the global harmonization performance according to the region-aware local feature. Moreover, we further designed a fusion prediction module by fusing features from all the cascaded decoder layers together to generate the final result, which could utilize the different degrees of harmonization results comprehensively. Without bells and whistles, our FRIH algorithm achieves the best performance on iHarmony4 dataset (PSNR is 38.19 dB) with a lightweight model. The parameters for our model are only 11.98 M, far below the existing methods.
Learning Distinctive Margin toward Active Domain Adaptation
Apr 03, 2022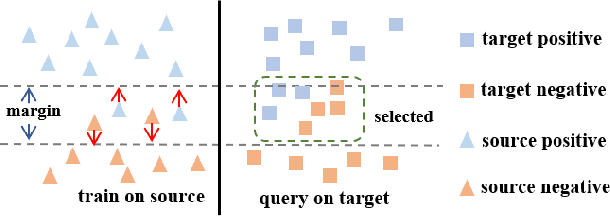
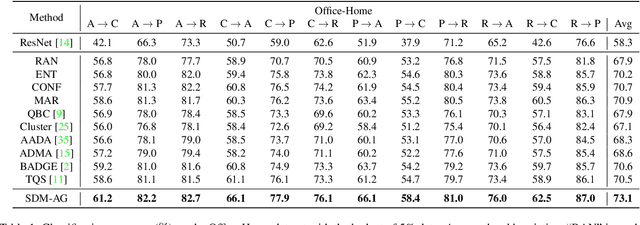
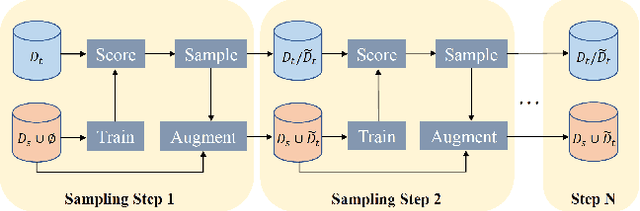
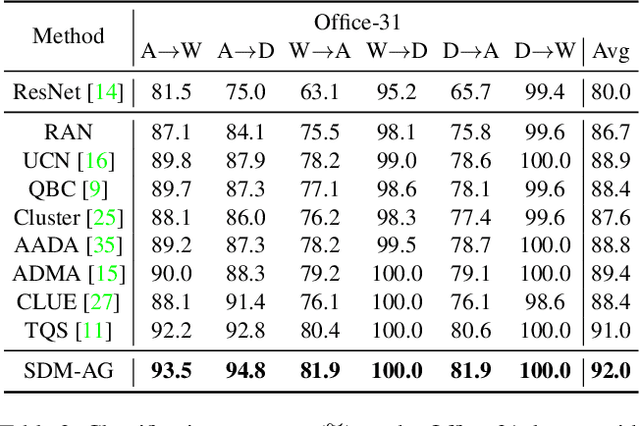
Despite plenty of efforts focusing on improving the domain adaptation ability (DA) under unsupervised or few-shot semi-supervised settings, recently the solution of active learning started to attract more attention due to its suitability in transferring model in a more practical way with limited annotation resource on target data. Nevertheless, most active learning methods are not inherently designed to handle domain gap between data distribution, on the other hand, some active domain adaptation methods (ADA) usually requires complicated query functions, which is vulnerable to overfitting. In this work, we propose a concise but effective ADA method called Select-by-Distinctive-Margin (SDM), which consists of a maximum margin loss and a margin sampling algorithm for data selection. We provide theoretical analysis to show that SDM works like a Support Vector Machine, storing hard examples around decision boundaries and exploiting them to find informative and transferable data. In addition, we propose two variants of our method, one is designed to adaptively adjust the gradient from margin loss, the other boosts the selectivity of margin sampling by taking the gradient direction into account. We benchmark SDM with standard active learning setting, demonstrating our algorithm achieves competitive results with good data scalability. Code is available at https://github.com/TencentYoutuResearch/ActiveLearning-SDM
NMS-Loss: Learning with Non-Maximum Suppression for Crowded Pedestrian Detection
Jun 04, 2021



Non-Maximum Suppression (NMS) is essential for object detection and affects the evaluation results by incorporating False Positives (FP) and False Negatives (FN), especially in crowd occlusion scenes. In this paper, we raise the problem of weak connection between the training targets and the evaluation metrics caused by NMS and propose a novel NMS-Loss making the NMS procedure can be trained end-to-end without any additional network parameters. Our NMS-Loss punishes two cases when FP is not suppressed and FN is wrongly eliminated by NMS. Specifically, we propose a pull loss to pull predictions with the same target close to each other, and a push loss to push predictions with different targets away from each other. Experimental results show that with the help of NMS-Loss, our detector, namely NMS-Ped, achieves impressive results with Miss Rate of 5.92% on Caltech dataset and 10.08% on CityPersons dataset, which are both better than state-of-the-art competitors.
Rethinking Semantic Segmentation from a Sequence-to-Sequence Perspective with Transformers
Dec 31, 2020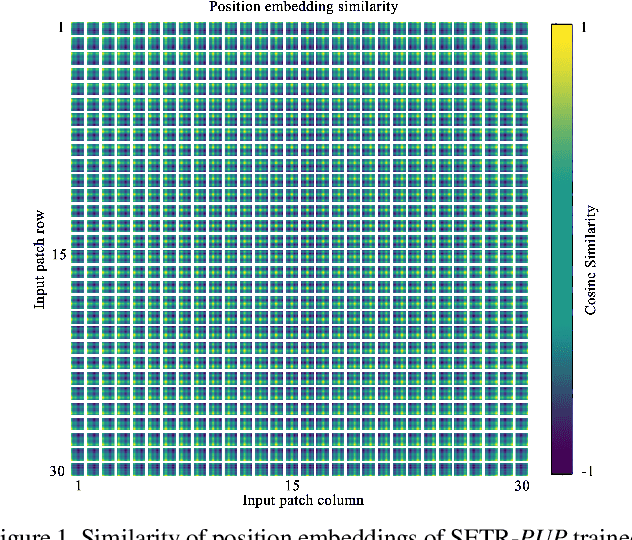



Most recent semantic segmentation methods adopt a fully-convolutional network (FCN) with an encoder-decoder architecture. The encoder progressively reduces the spatial resolution and learns more abstract/semantic visual concepts with larger receptive fields. Since context modeling is critical for segmentation, the latest efforts have been focused on increasing the receptive field, through either dilated/atrous convolutions or inserting attention modules. However, the encoder-decoder based FCN architecture remains unchanged. In this paper, we aim to provide an alternative perspective by treating semantic segmentation as a sequence-to-sequence prediction task. Specifically, we deploy a pure transformer (ie, without convolution and resolution reduction) to encode an image as a sequence of patches. With the global context modeled in every layer of the transformer, this encoder can be combined with a simple decoder to provide a powerful segmentation model, termed SEgmentation TRansformer (SETR). Extensive experiments show that SETR achieves new state of the art on ADE20K (50.28% mIoU), Pascal Context (55.83% mIoU) and competitive results on Cityscapes. Particularly, we achieve the first (44.42% mIoU) position in the highly competitive ADE20K test server leaderboard.