 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgescSiameseClu: A Siamese Clustering Framework for Interpreting single-cell RNA Sequencing Data
May 19, 2025



Single-cell RNA sequencing (scRNA-seq) reveals cell heterogeneity, with cell clustering playing a key role in identifying cell types and marker genes. Recent advances, especially graph neural networks (GNNs)-based methods, have significantly improved clustering performance. However, the analysis of scRNA-seq data remains challenging due to noise, sparsity, and high dimensionality. Compounding these challenges, GNNs often suffer from over-smoothing, limiting their ability to capture complex biological information. In response, we propose scSiameseClu, a novel Siamese Clustering framework for interpreting single-cell RNA-seq data, comprising of 3 key steps: (1) Dual Augmentation Module, which applies biologically informed perturbations to the gene expression matrix and cell graph relationships to enhance representation robustness; (2) Siamese Fusion Module, which combines cross-correlation refinement and adaptive information fusion to capture complex cellular relationships while mitigating over-smoothing; and (3) Optimal Transport Clustering, which utilizes Sinkhorn distance to efficiently align cluster assignments with predefined proportions while maintaining balance. Comprehensive evaluations on seven real-world datasets demonstrate that~\methodname~outperforms state-of-the-art methods in single-cell clustering, cell type annotation, and cell type classification, providing a powerful tool for scRNA-seq data interpretation.
Exploring Implicit Visual Misunderstandings in Multimodal Large Language Models through Attention Analysis
May 15, 2025Recent advancements have enhanced the capability of Multimodal Large Language Models (MLLMs) to comprehend multi-image information. However, existing benchmarks primarily evaluate answer correctness, overlooking whether models genuinely comprehend the visual input. To address this, we define implicit visual misunderstanding (IVM), where MLLMs provide correct answers without fully comprehending the visual input. Through our analysis, we decouple the visual and textual modalities within the causal attention module, revealing that attention distribution increasingly converges on the image associated with the correct answer as the network layers deepen. This insight leads to the introduction of a scale-agnostic metric, \textit{attention accuracy}, and a novel benchmark for quantifying IVMs. Attention accuracy directly evaluates the model's visual understanding via internal mechanisms, remaining robust to positional biases for more reliable assessments. Furthermore, we extend our approach to finer granularities and demonstrate its effectiveness in unimodal scenarios, underscoring its versatility and generalizability.
Rethinking Graph Contrastive Learning through Relative Similarity Preservation
May 08, 2025Graph contrastive learning (GCL) has achieved remarkable success by following the computer vision paradigm of preserving absolute similarity between augmented views. However, this approach faces fundamental challenges in graphs due to their discrete, non-Euclidean nature -- view generation often breaks semantic validity and similarity verification becomes unreliable. Through analyzing 11 real-world graphs, we discover a universal pattern transcending the homophily-heterophily dichotomy: label consistency systematically diminishes as structural distance increases, manifesting as smooth decay in homophily graphs and oscillatory decay in heterophily graphs. We establish theoretical guarantees for this pattern through random walk theory, proving label distribution convergence and characterizing the mechanisms behind different decay behaviors. This discovery reveals that graphs naturally encode relative similarity patterns, where structurally closer nodes exhibit collectively stronger semantic relationships. Leveraging this insight, we propose RELGCL, a novel GCL framework with complementary pairwise and listwise implementations that preserve these inherent patterns through collective similarity objectives. Extensive experiments demonstrate that our method consistently outperforms 20 existing approaches across both homophily and heterophily graphs, validating the effectiveness of leveraging natural relative similarity over artificial absolute similarity.
PCF-Grasp: Converting Point Completion to Geometry Feature to Enhance 6-DoF Grasp
Apr 22, 2025The 6-Degree of Freedom (DoF) grasp method based on point clouds has shown significant potential in enabling robots to grasp target objects. However, most existing methods are based on the point clouds (2.5D points) generated from single-view depth images. These point clouds only have one surface side of the object providing incomplete geometry information, which mislead the grasping algorithm to judge the shape of the target object, resulting in low grasping accuracy. Humans can accurately grasp objects from a single view by leveraging their geometry experience to estimate object shapes. Inspired by humans, we propose a novel 6-DoF grasping framework that converts the point completion results as object shape features to train the 6-DoF grasp network. Here, point completion can generate approximate complete points from the 2.5D points similar to the human geometry experience, and converting it as shape features is the way to utilize it to improve grasp efficiency. Furthermore, due to the gap between the network generation and actual execution, we integrate a score filter into our framework to select more executable grasp proposals for the real robot. This enables our method to maintain a high grasp quality in any camera viewpoint. Extensive experiments demonstrate that utilizing complete point features enables the generation of significantly more accurate grasp proposals and the inclusion of a score filter greatly enhances the credibility of real-world robot grasping. Our method achieves a 17.8\% success rate higher than the state-of-the-art method in real-world experiments.
HSACNet: Hierarchical Scale-Aware Consistency Regularized Semi-Supervised Change Detection
Apr 18, 2025Semi-supervised change detection (SSCD) aims to detect changes between bi-temporal remote sensing images by utilizing limited labeled data and abundant unlabeled data. Existing methods struggle in complex scenarios, exhibiting poor performance when confronted with noisy data. They typically neglect intra-layer multi-scale features while emphasizing inter-layer fusion, harming the integrity of change objects with different scales. In this paper, we propose HSACNet, a Hierarchical Scale-Aware Consistency regularized Network for SSCD. Specifically, we integrate Segment Anything Model 2 (SAM2), using its Hiera backbone as the encoder to extract inter-layer multi-scale features and applying adapters for parameter-efficient fine-tuning. Moreover, we design a Scale-Aware Differential Attention Module (SADAM) that can precisely capture intra-layer multi-scale change features and suppress noise. Additionally, a dual-augmentation consistency regularization strategy is adopted to effectively utilize the unlabeled data. Extensive experiments across four CD benchmarks demonstrate that our HSACNet achieves state-of-the-art performance, with reduced parameters and computational cost.
PCM-SAR: Physics-Driven Contrastive Mutual Learning for SAR Classification
Apr 13, 2025Existing SAR image classification methods based on Contrastive Learning often rely on sample generation strategies designed for optical images, failing to capture the distinct semantic and physical characteristics of SAR data. To address this, we propose Physics-Driven Contrastive Mutual Learning for SAR Classification (PCM-SAR), which incorporates domain-specific physical insights to improve sample generation and feature extraction. PCM-SAR utilizes the gray-level co-occurrence matrix (GLCM) to simulate realistic noise patterns and applies semantic detection for unsupervised local sampling, ensuring generated samples accurately reflect SAR imaging properties. Additionally, a multi-level feature fusion mechanism based on mutual learning enables collaborative refinement of feature representations. Notably, PCM-SAR significantly enhances smaller models by refining SAR feature representations, compensating for their limited capacity. Experimental results show that PCM-SAR consistently outperforms SOTA methods across diverse datasets and SAR classification tasks.
Deep Cut-informed Graph Embedding and Clustering
Mar 09, 2025Graph clustering aims to divide the graph into different clusters. The recently emerging deep graph clustering approaches are largely built on graph neural networks (GNN). However, GNN is designed for general graph encoding and there is a common issue of representation collapse in existing GNN-based deep graph clustering algorithms. We attribute two main reasons for such issue: (i) the inductive bias of GNN models: GNNs tend to generate similar representations for proximal nodes. Since graphs often contain a non-negligible amount of inter-cluster links, the bias results in error message passing and leads to biased clustering; (ii) the clustering guided loss function: most traditional approaches strive to make all samples closer to pre-learned cluster centers, which cause a degenerate solution assigning all data points to a single label thus make all samples and less discriminative. To address these challenges, we investigate graph clustering from a graph cut perspective and propose an innovative and non-GNN-based Deep Cut-informed Graph embedding and Clustering framework, namely DCGC. This framework includes two modules: (i) cut-informed graph encoding; (ii) self-supervised graph clustering via optimal transport. For the encoding module, we derive a cut-informed graph embedding objective to fuse graph structure and attributes by minimizing their joint normalized cut. For the clustering module, we utilize the optimal transport theory to obtain the clustering assignments, which can balance the guidance of proximity to the pre-learned cluster center. With the above two tailored designs, DCGC is more suitable for the graph clustering task, which can effectively alleviate the problem of representation collapse and achieve better performance. We conduct extensive experiments to demonstrate that our method is simple but effective compared with benchmarks.
Qwen2.5-VL Technical Report
Feb 19, 2025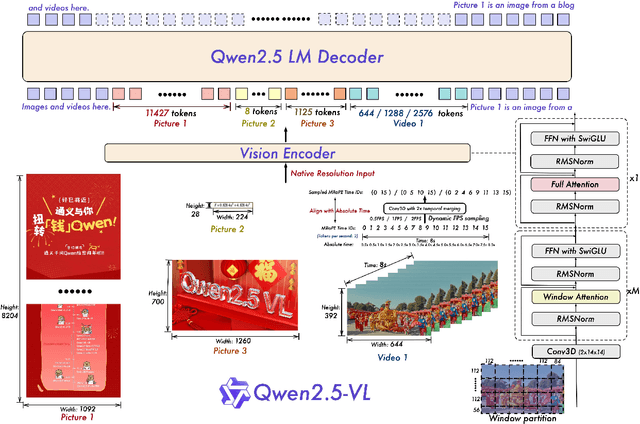
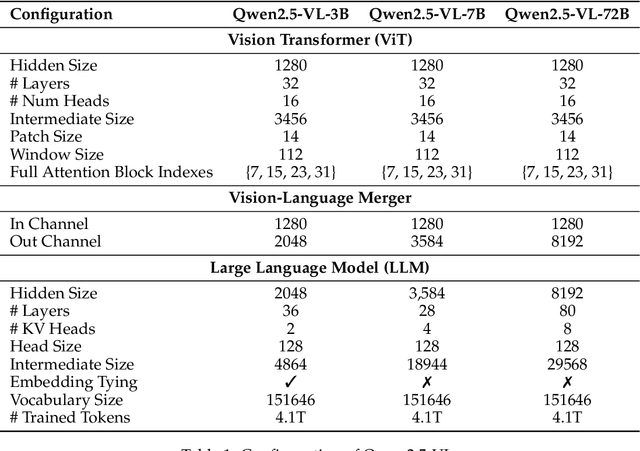
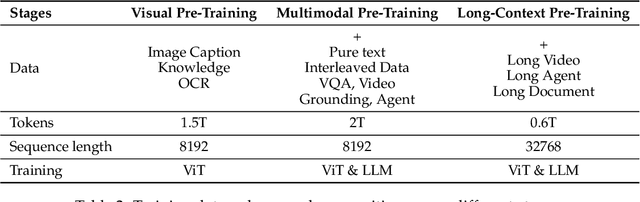
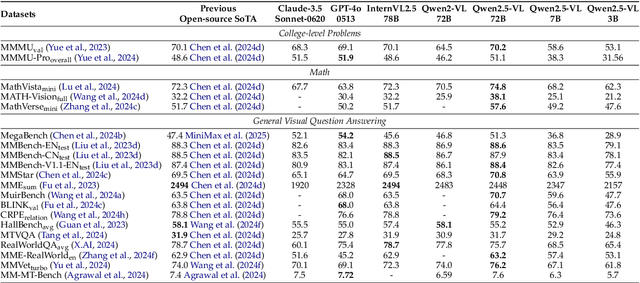
We introduce Qwen2.5-VL, the latest flagship model of Qwen vision-language series, which demonstrates significant advancements in both foundational capabilities and innovative functionalities. Qwen2.5-VL achieves a major leap forward in understanding and interacting with the world through enhanced visual recognition, precise object localization, robust document parsing, and long-video comprehension. A standout feature of Qwen2.5-VL is its ability to localize objects using bounding boxes or points accurately. It provides robust structured data extraction from invoices, forms, and tables, as well as detailed analysis of charts, diagrams, and layouts. To handle complex inputs, Qwen2.5-VL introduces dynamic resolution processing and absolute time encoding, enabling it to process images of varying sizes and videos of extended durations (up to hours) with second-level event localization. This allows the model to natively perceive spatial scales and temporal dynamics without relying on traditional normalization techniques. By training a native dynamic-resolution Vision Transformer (ViT) from scratch and incorporating Window Attention, we reduce computational overhead while maintaining native resolution. As a result, Qwen2.5-VL excels not only in static image and document understanding but also as an interactive visual agent capable of reasoning, tool usage, and task execution in real-world scenarios such as operating computers and mobile devices. Qwen2.5-VL is available in three sizes, addressing diverse use cases from edge AI to high-performance computing. The flagship Qwen2.5-VL-72B model matches state-of-the-art models like GPT-4o and Claude 3.5 Sonnet, particularly excelling in document and diagram understanding. Additionally, Qwen2.5-VL maintains robust linguistic performance, preserving the core language competencies of the Qwen2.5 LLM.
Diversity-Oriented Data Augmentation with Large Language Models
Feb 17, 2025Data augmentation is an essential technique in natural language processing (NLP) for enriching training datasets by generating diverse samples. This process is crucial for improving the robustness and generalization capabilities of NLP models. However, a significant challenge remains: \textit{Insufficient Attention to Sample Distribution Diversity}. Most existing methods focus on increasing the sample numbers while neglecting the sample distribution diversity, which can lead to model overfitting. In response, we explore data augmentation's impact on dataset diversity and propose a \textbf{\underline{D}}iversity-\textbf{\underline{o}}riented data \textbf{\underline{Aug}}mentation framework (\textbf{DoAug}). % \(\mathscr{DoAug}\) Specifically, we utilize a diversity-oriented fine-tuning approach to train an LLM as a diverse paraphraser, which is capable of augmenting textual datasets by generating diversified paraphrases. Then, we apply the LLM paraphraser to a selected coreset of highly informative samples and integrate the paraphrases with the original data to create a more diverse augmented dataset. Finally, we conduct extensive experiments on 12 real-world textual datasets. The results show that our fine-tuned LLM augmenter improves diversity while preserving label consistency, thereby enhancing the robustness and performance of downstream tasks. Specifically, it achieves an average performance gain of \(10.52\%\), surpassing the runner-up baseline with more than three percentage points.
Towards Data-Centric AI: A Comprehensive Survey of Traditional, Reinforcement, and Generative Approaches for Tabular Data Transformation
Jan 17, 2025



Tabular data is one of the most widely used formats across industries, driving critical applications in areas such as finance, healthcare, and marketing. In the era of data-centric AI, improving data quality and representation has become essential for enhancing model performance, particularly in applications centered around tabular data. This survey examines the key aspects of tabular data-centric AI, emphasizing feature selection and feature generation as essential techniques for data space refinement. We provide a systematic review of feature selection methods, which identify and retain the most relevant data attributes, and feature generation approaches, which create new features to simplify the capture of complex data patterns. This survey offers a comprehensive overview of current methodologies through an analysis of recent advancements, practical applications, and the strengths and limitations of these techniques. Finally, we outline open challenges and suggest future perspectives to inspire continued innovation in this field.