 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStaRPO: Stability-Augmented Reinforcement Policy Optimization
Apr 10, 2026Reinforcement learning (RL) is effective in enhancing the accuracy of large language models in complex reasoning tasks. Existing RL policy optimization frameworks rely on final-answer correctness as feedback signals and rarely capture the internal logical structure of the reasoning process. Consequently, the models would generate fluent and semantically relevant responses but logically inconsistent, structurally erratic, or redundant. To this end, we propose StaRPO, a stability-augmented reinforcement learning framework that explicitly incorporates reasoning stability into the optimization objective. Our StaRPO decomposes stability into two computable lightweight metrics: the Autocorrelation Function (ACF) to evaluate local step-to-step coherence, and Path Efficiency (PE) to evaluate global goal-directedness of the reasoning trajectory. These stability rewards are combined with task rewards to provide complementary and process-aware feedback. We validate the effectiveness of using ACF and PE rewards by showing their correlation with logic errors on two backbone models. Experiments on four reasoning benchmarks show that StaRPO consistently outperforms compared baselines and can enhance both final-answer accuracy and logical stability.
Mitigating Shortcut Reasoning in Language Models: A Gradient-Aware Training Approach
Mar 21, 2026Large language models exhibit strong reasoning capabilities, yet often rely on shortcuts such as surface pattern matching and answer memorization rather than genuine logical inference. We propose Shortcut-Aware Reasoning Training (SART), a gradient-aware framework that detects and mitigates shortcut-promoting samples via ShortcutScore and gradient surgery. Our method identifies shortcut signals through gradient misalignment with validation objectives and answer-token concentration, and modifies training dynamics accordingly. Experiments on controlled reasoning benchmarks show that SART achieves +16.5% accuracy and +40.2% robustness over the strongest baseline, significantly improving generalization under distribution shifts. Code is available at: https://github.com/fuyanjie/short-cut-aware-data-centric-reasoning.
Causally-Guided Diffusion for Stable Feature Selection
Mar 21, 2026Feature selection is fundamental to robust data-centric AI, but most existing methods optimize predictive performance under a single data distribution. This often selects spurious features that fail under distribution shifts. Motivated by principles from causal invariance, we study feature selection from a stability perspective and introduce Causally-Guided Diffusion for Stable Feature Selection (CGDFS). In CGDFS, we formalized feature selection as approximate posterior inference over feature subsets, whose posterior mass favors low prediction error and low cross-environment variance. Our framework combines three key insights: First, we formulate feature selection as stability-aware posterior sampling. Here, causal invariance serves as a soft inductive bias rather than explicit causal discovery. Second, we train a diffusion model as a learned prior over plausible continuous selection masks, combined with a stability-aware likelihood that rewards invariance across environments. This diffusion prior captures structural dependencies among features and enables scalable exploration of the combinatorially large selection space. Third, we perform guided annealed Langevin sampling that combines the diffusion prior with the stability objective, which yields a tractable, uncertainty-aware posterior inference that avoids discrete optimization and produces robust feature selections. We evaluate CGDFS on open-source real-world datasets exhibiting distribution shifts. Across both classification and regression tasks, CGDFS consistently selects more stable and transferable feature subsets, which leads to improved out-of-distribution performance and greater selection robustness compared to sparsity-based, tree-based, and stability-selection baselines.
AgentOS: From Application Silos to a Natural Language-Driven Data Ecosystem
Mar 11, 2026The rapid emergence of open-source, locally hosted intelligent agents marks a critical inflection point in human-computer interaction. Systems such as OpenClaw demonstrate that Large Language Model (LLM)-based agents can autonomously operate local computing environments, orchestrate workflows, and integrate external tools. However, within the current paradigm, these agents remain conventional applications running on legacy operating systems originally designed for Graphical User Interfaces (GUIs) or Command Line Interfaces (CLIs). This architectural mismatch leads to fragmented interaction models, poorly structured permission management (often described as "Shadow AI"), and severe context fragmentation. This paper proposes a new paradigm: a Personal Agent Operating System (AgentOS). In AgentOS, traditional GUI desktops are replaced by a Natural User Interface (NUI) centered on a unified natural language or voice portal. The system core becomes an Agent Kernel that interprets user intent, decomposes tasks, and coordinates multiple agents, while traditional applications evolve into modular Skills-as-Modules enabling users to compose software through natural language rules. We argue that realizing AgentOS fundamentally becomes a Knowledge Discovery and Data Mining (KDD) problem. The Agent Kernel must operate as a real-time engine for intent mining and knowledge discovery. Viewed through this lens, the operating system becomes a continuous data mining pipeline involving sequential pattern mining for workflow automation, recommender systems for skill retrieval, and dynamically evolving personal knowledge graphs. These challenges define a new research agenda for the KDD community in building the next generation of intelligent computing systems.
Sim2Act: Robust Simulation-to-Decision Learning via Adversarial Calibration and Group-Relative Perturbation
Mar 10, 2026Simulation-to-decision learning enables safe policy training in digital environments without risking real-world deployment, and has become essential in mission-critical domains such as supply chains and industrial systems. However, simulators learned from noisy or biased real-world data often exhibit prediction errors in decision-critical regions, leading to unstable action ranking and unreliable policies. Existing approaches either focus on improving average simulation fidelity or adopt conservative regularization, which may cause policy collapse by discarding high-risk high-reward actions. We propose Sim2Act, a robust simulation-to-decision framework that addresses both simulator and policy robustness. First, we introduce an adversarial calibration mechanism that re-weights simulation errors in decision-critical state-action pairs to align surrogate fidelity with downstream decision impact. Second, we develop a group-relative perturbation strategy that stabilizes policy learning under simulator uncertainty without enforcing overly pessimistic constraints. Extensive experiments on multiple supply chain benchmarks demonstrate improved simulation robustness and more stable decision performance under structured and unstructured perturbations.
City Editing: Hierarchical Agentic Execution for Dependency-Aware Urban Geospatial Modification
Feb 22, 2026As cities evolve over time, challenges such as traffic congestion and functional imbalance increasingly necessitate urban renewal through efficient modification of existing plans, rather than complete re-planning. In practice, even minor urban changes require substantial manual effort to redraw geospatial layouts, slowing the iterative planning and decision-making procedure. Motivated by recent advances in agentic systems and multimodal reasoning, we formulate urban renewal as a machine-executable task that iteratively modifies existing urban plans represented in structured geospatial formats. More specifically, we represent urban layouts using GeoJSON and decompose natural-language editing instructions into hierarchical geometric intents spanning polygon-, line-, and point-level operations. To coordinate interdependent edits across spatial elements and abstraction levels, we propose a hierarchical agentic framework that jointly performs multi-level planning and execution with explicit propagation of intermediate spatial constraints. We further introduce an iterative execution-validation mechanism that mitigates error accumulation and enforces global spatial consistency during multi-step editing. Extensive experiments across diverse urban editing scenarios demonstrate significant improvements in efficiency, robustness, correctness, and spatial validity over existing baselines.
AgentCPM-Report: Interleaving Drafting and Deepening for Open-Ended Deep Research
Feb 06, 2026Generating deep research reports requires large-scale information acquisition and the synthesis of insight-driven analysis, posing a significant challenge for current language models. Most existing approaches follow a plan-then-write paradigm, whose performance heavily depends on the quality of the initial outline. However, constructing a comprehensive outline itself demands strong reasoning ability, causing current deep research systems to rely almost exclusively on closed-source or online large models. This reliance raises practical barriers to deployment and introduces safety and privacy concerns for user-authored data. In this work, we present AgentCPM-Report, a lightweight yet high-performing local solution composed of a framework that mirrors the human writing process and an 8B-parameter deep research agent. Our framework uses a Writing As Reasoning Policy (WARP), which enables models to dynamically revise outlines during report generation. Under this policy, the agent alternates between Evidence-Based Drafting and Reasoning-Driven Deepening, jointly supporting information acquisition, knowledge refinement, and iterative outline evolution. To effectively equip small models with this capability, we introduce a Multi-Stage Agentic Training strategy, consisting of cold-start, atomic skill RL, and holistic pipeline RL. Experiments on DeepResearch Bench, DeepConsult, and DeepResearch Gym demonstrate that AgentCPM-Report outperforms leading closed-source systems, with substantial gains in Insight.
Data-Efficient Symbolic Regression via Foundation Model Distillation
Aug 27, 2025Discovering interpretable mathematical equations from observed data (a.k.a. equation discovery or symbolic regression) is a cornerstone of scientific discovery, enabling transparent modeling of physical, biological, and economic systems. While foundation models pre-trained on large-scale equation datasets offer a promising starting point, they often suffer from negative transfer and poor generalization when applied to small, domain-specific datasets. In this paper, we introduce EQUATE (Equation Generation via QUality-Aligned Transfer Embeddings), a data-efficient fine-tuning framework that adapts foundation models for symbolic equation discovery in low-data regimes via distillation. EQUATE combines symbolic-numeric alignment with evaluator-guided embedding optimization, enabling a principled embedding-search-generation paradigm. Our approach reformulates discrete equation search as a continuous optimization task in a shared embedding space, guided by data-equation fitness and simplicity. Experiments across three standard public benchmarks (Feynman, Strogatz, and black-box datasets) demonstrate that EQUATE consistently outperforms state-of-the-art baselines in both accuracy and robustness, while preserving low complexity and fast inference. These results highlight EQUATE as a practical and generalizable solution for data-efficient symbolic regression in foundation model distillation settings.
Galaxy: A Cognition-Centered Framework for Proactive, Privacy-Preserving, and Self-Evolving LLM Agents
Aug 06, 2025Intelligent personal assistants (IPAs) such as Siri and Google Assistant are designed to enhance human capabilities and perform tasks on behalf of users. The emergence of LLM agents brings new opportunities for the development of IPAs. While responsive capabilities have been widely studied, proactive behaviors remain underexplored. Designing an IPA that is proactive, privacy-preserving, and capable of self-evolution remains a significant challenge. Designing such IPAs relies on the cognitive architecture of LLM agents. This work proposes Cognition Forest, a semantic structure designed to align cognitive modeling with system-level design. We unify cognitive architecture and system design into a self-reinforcing loop instead of treating them separately. Based on this principle, we present Galaxy, a framework that supports multidimensional interactions and personalized capability generation. Two cooperative agents are implemented based on Galaxy: KoRa, a cognition-enhanced generative agent that supports both responsive and proactive skills; and Kernel, a meta-cognition-based meta-agent that enables Galaxy's self-evolution and privacy preservation. Experimental results show that Galaxy outperforms multiple state-of-the-art benchmarks. Ablation studies and real-world interaction cases validate the effectiveness of Galaxy.
Efficient Post-Training Refinement of Latent Reasoning in Large Language Models
Jun 10, 2025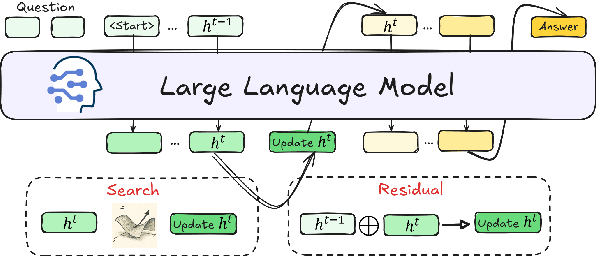
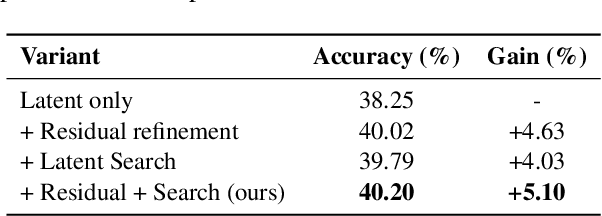
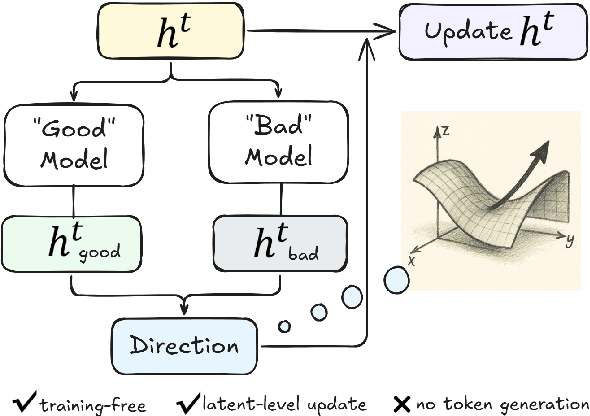
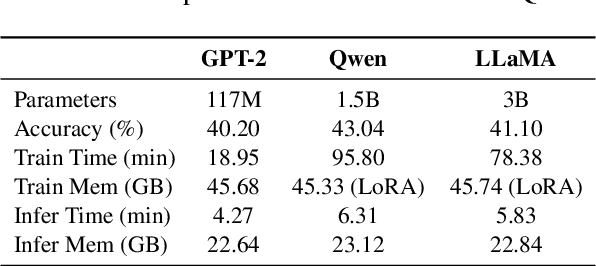
Reasoning is a key component of language understanding in Large Language Models. While Chain-of-Thought prompting enhances performance via explicit intermediate steps, it suffers from sufficient token overhead and a fixed reasoning trajectory, preventing step-wise refinement. Recent advances in latent reasoning address these limitations by refining internal reasoning processes directly in the model's latent space, without producing explicit outputs. However, a key challenge remains: how to effectively update reasoning embeddings during post-training to guide the model toward more accurate solutions. To overcome this challenge, we propose a lightweight post-training framework that refines latent reasoning trajectories using two novel strategies: 1) Contrastive reasoning feedback, which compares reasoning embeddings against strong and weak baselines to infer effective update directions via embedding enhancement; 2) Residual embedding refinement, which stabilizes updates by progressively integrating current and historical gradients, enabling fast yet controlled convergence. Extensive experiments and case studies are conducted on five reasoning benchmarks to demonstrate the effectiveness of the proposed framework. Notably, a 5\% accuracy gain on MathQA without additional training.