 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTHOR: Inductive Link Prediction over Hyper-Relational Knowledge Graphs
Feb 05, 2026Knowledge graphs (KGs) have become a key ingredient supporting a variety of applications. Beyond the traditional triplet representation of facts where a relation connects two entities, modern KGs observe an increasing number of hyper-relational facts, where an arbitrary number of qualifiers associated with a triplet provide auxiliary information to further describe the rich semantics of the triplet, which can effectively boost the reasoning performance in link prediction tasks. However, existing link prediction techniques over such hyper-relational KGs (HKGs) mostly focus on a transductive setting, where KG embedding models are learned from the specific vocabulary of a given KG and subsequently can only make predictions within the same vocabulary, limiting their generalizability to previously unseen vocabularies. Against this background, we propose THOR, an inducTive link prediction technique for Hyper-relational knOwledge gRaphs. Specifically, we first introduce both relation and entity foundation graphs, modeling their fundamental inter- and intra-fact interactions in HKGs, which are agnostic to any specific relations and entities. Afterward, THOR is designed to learn from the two foundation graphs with two parallel graph encoders followed by a transformer decoder, which supports efficient masked training and fully-inductive inference. We conduct a thorough evaluation of THOR in hyper-relational link prediction tasks on 12 datasets with different settings. Results show that THOR outperforms a sizable collection of baselines, yielding 66.1%, 55.9%, and 20.4% improvement over the best-performing rule-based, semi-inductive, and fully-inductive techniques, respectively. A series of ablation studies also reveals our key design factors capturing the structural invariance transferable across HKGs for inductive tasks.
VITA: Versatile Time Representation Learning for Temporal Hyper-Relational Knowledge Graphs
May 17, 2025Knowledge graphs (KGs) have become an effective paradigm for managing real-world facts, which are not only complex but also dynamically evolve over time. The temporal validity of facts often serves as a strong clue in downstream link prediction tasks, which predicts a missing element in a fact. Traditional link prediction techniques on temporal KGs either consider a sequence of temporal snapshots of KGs with an ad-hoc defined time interval or expand a temporal fact over its validity period under a predefined time granularity; these approaches not only suffer from the sensitivity of the selection of time interval/granularity, but also face the computational challenges when handling facts with long (even infinite) validity. Although the recent hyper-relational KGs represent the temporal validity of a fact as qualifiers describing the fact, it is still suboptimal due to its ignorance of the infinite validity of some facts and the insufficient information encoded from the qualifiers about the temporal validity. Against this background, we propose VITA, a $\underline{V}$ersatile t$\underline{I}$me represen$\underline{TA}$tion learning method for temporal hyper-relational knowledge graphs. We first propose a versatile time representation that can flexibly accommodate all four types of temporal validity of facts (i.e., since, until, period, time-invariant), and then design VITA to effectively learn the time information in both aspects of time value and timespan to boost the link prediction performance. We conduct a thorough evaluation of VITA compared to a sizable collection of baselines on real-world KG datasets. Results show that VITA outperforms the best-performing baselines in various link prediction tasks (predicting missing entities, relations, time, and other numeric literals) by up to 75.3%. Ablation studies and a case study also support our key design choices.
Harnessing Multiple Large Language Models: A Survey on LLM Ensemble
Feb 25, 2025



LLM Ensemble -- which involves the comprehensive use of multiple large language models (LLMs), each aimed at handling user queries during downstream inference, to benefit from their individual strengths -- has gained substantial attention recently. The widespread availability of LLMs, coupled with their varying strengths and out-of-the-box usability, has profoundly advanced the field of LLM Ensemble. This paper presents the first systematic review of recent developments in LLM Ensemble. First, we introduce our taxonomy of LLM Ensemble and discuss several related research problems. Then, we provide a more in-depth classification of the methods under the broad categories of "ensemble-before-inference, ensemble-during-inference, ensemble-after-inference", and review all relevant methods. Finally, we introduce related benchmarks and applications, summarize existing studies, and suggest several future research directions. A curated list of papers on LLM Ensemble is available at https://github.com/junchenzhi/Awesome-LLM-Ensemble.
On Your Mark, Get Set, Predict! Modeling Continuous-Time Dynamics of Cascades for Information Popularity Prediction
Sep 25, 2024



Information popularity prediction is important yet challenging in various domains, including viral marketing and news recommendations. The key to accurately predicting information popularity lies in subtly modeling the underlying temporal information diffusion process behind observed events of an information cascade, such as the retweets of a tweet. To this end, most existing methods either adopt recurrent networks to capture the temporal dynamics from the first to the last observed event or develop a statistical model based on self-exciting point processes to make predictions. However, information diffusion is intrinsically a complex continuous-time process with irregularly observed discrete events, which is oversimplified using recurrent networks as they fail to capture the irregular time intervals between events, or using self-exciting point processes as they lack flexibility to capture the complex diffusion process. Against this background, we propose ConCat, modeling the Continuous-time dynamics of Cascades for information popularity prediction. On the one hand, it leverages neural Ordinary Differential Equations (ODEs) to model irregular events of a cascade in continuous time based on the cascade graph and sequential event information. On the other hand, it considers cascade events as neural temporal point processes (TPPs) parameterized by a conditional intensity function which can also benefit the popularity prediction task. We conduct extensive experiments to evaluate ConCat on three real-world datasets. Results show that ConCat achieves superior performance compared to state-of-the-art baselines, yielding a 2.3%-33.2% improvement over the best-performing baselines across the three datasets.
CasFT: Future Trend Modeling for Information Popularity Prediction with Dynamic Cues-Driven Diffusion Models
Sep 25, 2024



The rapid spread of diverse information on online social platforms has prompted both academia and industry to realize the importance of predicting content popularity, which could benefit a wide range of applications, such as recommendation systems and strategic decision-making. Recent works mainly focused on extracting spatiotemporal patterns inherent in the information diffusion process within a given observation period so as to predict its popularity over a future period of time. However, these works often overlook the future popularity trend, as future popularity could either increase exponentially or stagnate, introducing uncertainties to the prediction performance. Additionally, how to transfer the preceding-term dynamics learned from the observed diffusion process into future-term trends remains an unexplored challenge. Against this background, we propose CasFT, which leverages observed information Cascades and dynamic cues extracted via neural ODEs as conditions to guide the generation of Future popularity-increasing Trends through a diffusion model. These generated trends are then combined with the spatiotemporal patterns in the observed information cascade to make the final popularity prediction. Extensive experiments conducted on three real-world datasets demonstrate that CasFT significantly improves the prediction accuracy, compared to state-of-the-art approaches, yielding 2.2%-19.3% improvement across different datasets.
Make Graph Neural Networks Great Again: A Generic Integration Paradigm of Topology-Free Patterns for Traffic Speed Prediction
Jun 24, 2024



Urban traffic speed prediction aims to estimate the future traffic speed for improving urban transportation services. Enormous efforts have been made to exploit Graph Neural Networks (GNNs) for modeling spatial correlations and temporal dependencies of traffic speed evolving patterns, regularized by graph topology.While achieving promising results, current traffic speed prediction methods still suffer from ignoring topology-free patterns, which cannot be captured by GNNs. To tackle this challenge, we propose a generic model for enabling the current GNN-based methods to preserve topology-free patterns. Specifically, we first develop a Dual Cross-Scale Transformer (DCST) architecture, including a Spatial Transformer and a Temporal Transformer, to preserve the cross-scale topology-free patterns and associated dynamics, respectively. Then, to further integrate both topology-regularized/-free patterns, we propose a distillation-style learning framework, in which the existing GNN-based methods are considered as the teacher model, and the proposed DCST architecture is considered as the student model. The teacher model would inject the learned topology-regularized patterns into the student model for integrating topology-free patterns. The extensive experimental results demonstrated the effectiveness of our methods.
REPLAY: Modeling Time-Varying Temporal Regularities of Human Mobility for Location Prediction over Sparse Trajectories
Feb 26, 2024



Location prediction forecasts a user's location based on historical user mobility traces. To tackle the intrinsic sparsity issue of real-world user mobility traces, spatiotemporal contexts have been shown as significantly useful. Existing solutions mostly incorporate spatiotemporal distances between locations in mobility traces, either by feeding them as additional inputs to Recurrent Neural Networks (RNNs) or by using them to search for informative past hidden states for prediction. However, such distance-based methods fail to capture the time-varying temporal regularities of human mobility, where human mobility is often more regular in the morning than in other periods, for example; this suggests the usefulness of the actual timestamps besides the temporal distances. Against this background, we propose REPLAY, a general RNN architecture learning to capture the time-varying temporal regularities for location prediction. Specifically, REPLAY not only resorts to the spatiotemporal distances in sparse trajectories to search for the informative past hidden states, but also accommodates the time-varying temporal regularities by incorporating smoothed timestamp embeddings using Gaussian weighted averaging with timestamp-specific learnable bandwidths, which can flexibly adapt to the temporal regularities of different strengths across different timestamps. Our extensive evaluation compares REPLAY against a sizable collection of state-of-the-art techniques on two real-world datasets. Results show that REPLAY consistently and significantly outperforms state-of-the-art methods by 7.7\%-10.9\% in the location prediction task, and the bandwidths reveal interesting patterns of the time-varying temporal regularities.
Spatial-Temporal Interplay in Human Mobility: A Hierarchical Reinforcement Learning Approach with Hypergraph Representation
Dec 25, 2023In the realm of human mobility, the decision-making process for selecting the next-visit location is intricately influenced by a trade-off between spatial and temporal constraints, which are reflective of individual needs and preferences. This trade-off, however, varies across individuals, making the modeling of these spatial-temporal dynamics a formidable challenge. To address the problem, in this work, we introduce the "Spatial-temporal Induced Hierarchical Reinforcement Learning" (STI-HRL) framework, for capturing the interplay between spatial and temporal factors in human mobility decision-making. Specifically, STI-HRL employs a two-tiered decision-making process: the low-level focuses on disentangling spatial and temporal preferences using dedicated agents, while the high-level integrates these considerations to finalize the decision. To complement the hierarchical decision setting, we construct a hypergraph to organize historical data, encapsulating the multi-aspect semantics of human mobility. We propose a cross-channel hypergraph embedding module to learn the representations as the states to facilitate the decision-making cycle. Our extensive experiments on two real-world datasets validate the superiority of STI-HRL over state-of-the-art methods in predicting users' next visits across various performance metrics.
Bridging the Gap between Community and Node Representations: Graph Embedding via Community Detection
Dec 17, 2019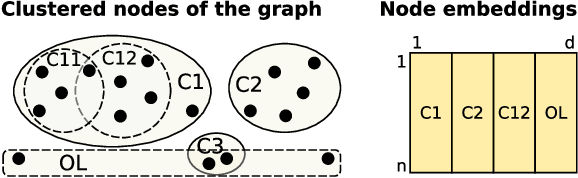
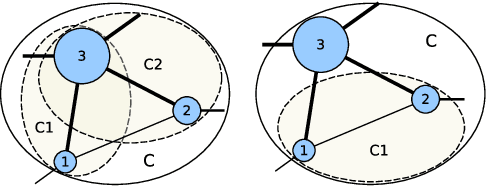
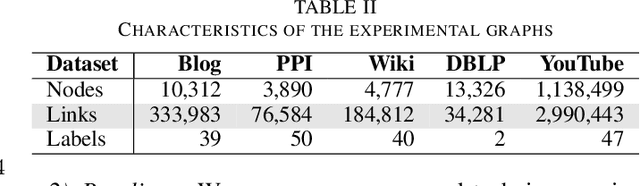
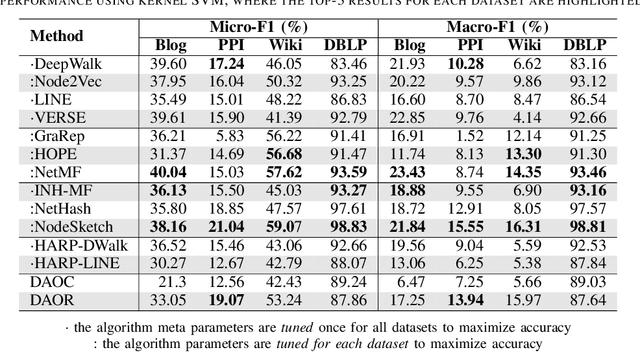
Graph embedding has become a key component of many data mining and analysis systems. Current graph embedding approaches either sample a large number of node pairs from a graph to learn node embeddings via stochastic optimization or factorize a high-order proximity/adjacency matrix of the graph via computationally expensive matrix factorization techniques. These approaches typically require significant resources for the learning process and rely on multiple parameters, which limits their applicability in practice. Moreover, most of the existing graph embedding techniques operate effectively in one specific metric space only (e.g., the one produced with cosine similarity), do not preserve higher-order structural features of the input graph and cannot automatically determine a meaningful number of embedding dimensions. Typically, the produced embeddings are not easily interpretable, which complicates further analyses and limits their applicability. To address these issues, we propose DAOR, a highly efficient and parameter-free graph embedding technique producing metric space-robust, compact and interpretable embeddings without any manual tuning. Compared to a dozen state-of-the-art graph embedding algorithms, DAOR yields competitive results on both node classification (which benefits form high-order proximity) and link prediction (which relies on low-order proximity mostly). Unlike existing techniques, however, DAOR does not require any parameter tuning and improves the embeddings generation speed by several orders of magnitude. Our approach has hence the ambition to greatly simplify and speed up data analysis tasks involving graph representation learning.