 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Self-supervised Vision Transformers for Representation Learning
Jun 17, 2021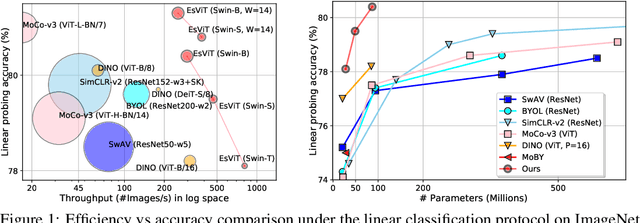
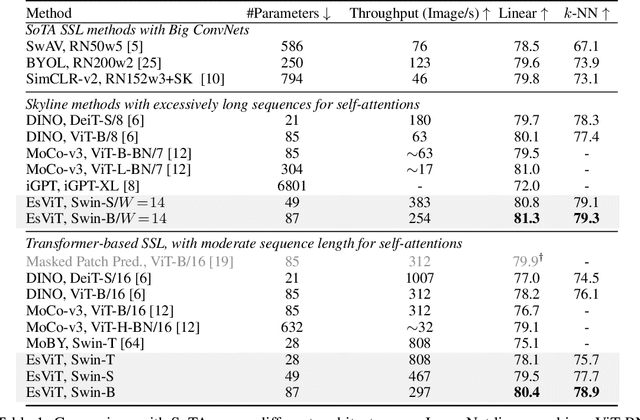
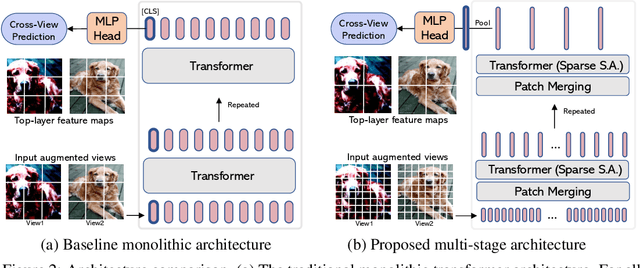

This paper investigates two techniques for developing efficient self-supervised vision transformers (EsViT) for visual representation learning. First, we show through a comprehensive empirical study that multi-stage architectures with sparse self-attentions can significantly reduce modeling complexity but with a cost of losing the ability to capture fine-grained correspondences between image regions. Second, we propose a new pre-training task of region matching which allows the model to capture fine-grained region dependencies and as a result significantly improves the quality of the learned vision representations. Our results show that combining the two techniques, EsViT achieves 81.3% top-1 on the ImageNet linear probe evaluation, outperforming prior arts with around an order magnitude of higher throughput. When transferring to downstream linear classification tasks, EsViT outperforms its supervised counterpart on 17 out of 18 datasets. The code and models will be publicly available.
3DB: A Framework for Debugging Computer Vision Models
Jun 07, 2021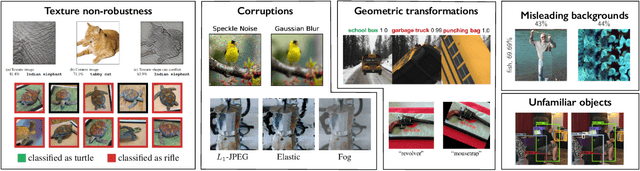
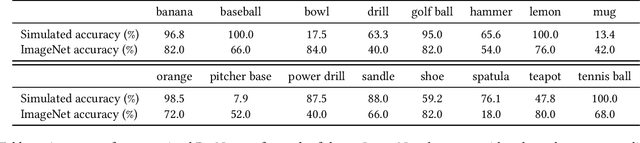

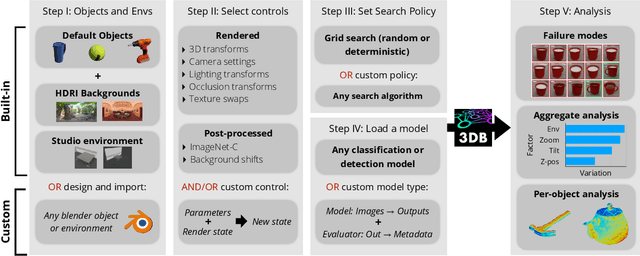
We introduce 3DB: an extendable, unified framework for testing and debugging vision models using photorealistic simulation. We demonstrate, through a wide range of use cases, that 3DB allows users to discover vulnerabilities in computer vision systems and gain insights into how models make decisions. 3DB captures and generalizes many robustness analyses from prior work, and enables one to study their interplay. Finally, we find that the insights generated by the system transfer to the physical world. We are releasing 3DB as a library (https://github.com/3db/3db) alongside a set of example analyses, guides, and documentation: https://3db.github.io/3db/ .
Multiscale Invertible Generative Networks for High-Dimensional Bayesian Inference
May 12, 2021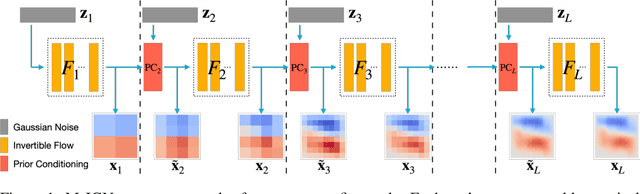
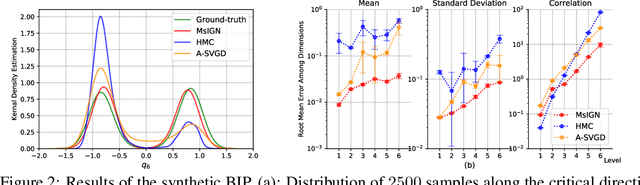
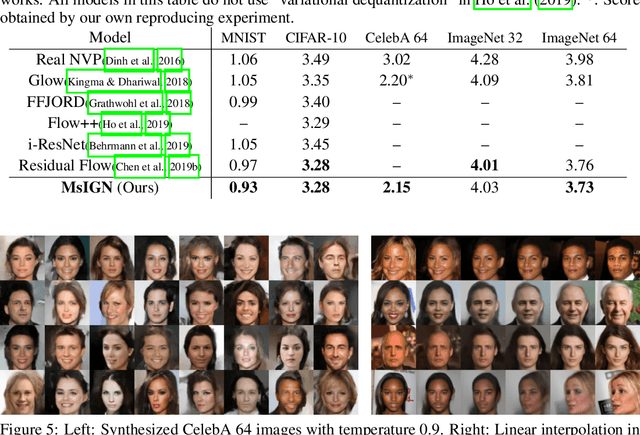
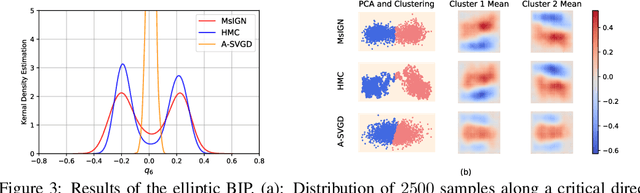
We propose a Multiscale Invertible Generative Network (MsIGN) and associated training algorithm that leverages multiscale structure to solve high-dimensional Bayesian inference. To address the curse of dimensionality, MsIGN exploits the low-dimensional nature of the posterior, and generates samples from coarse to fine scale (low to high dimension) by iteratively upsampling and refining samples. MsIGN is trained in a multi-stage manner to minimize the Jeffreys divergence, which avoids mode dropping in high-dimensional cases. On two high-dimensional Bayesian inverse problems, we show superior performance of MsIGN over previous approaches in posterior approximation and multiple mode capture. On the natural image synthesis task, MsIGN achieves superior performance in bits-per-dimension over baseline models and yields great interpret-ability of its neurons in intermediate layers.
Multi-Scale Vision Longformer: A New Vision Transformer for High-Resolution Image Encoding
Mar 29, 2021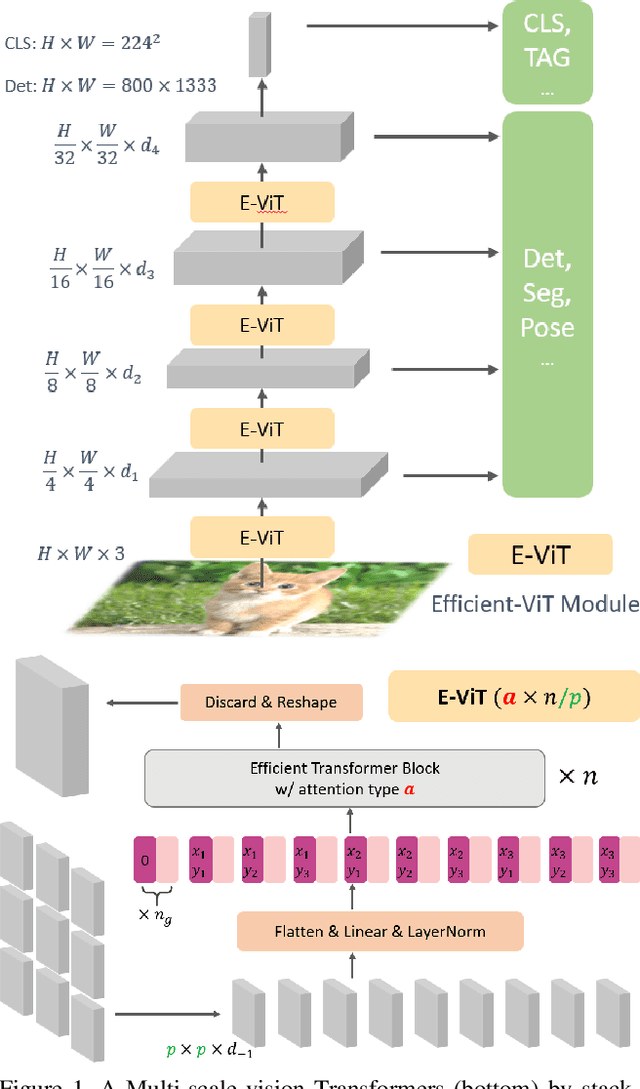
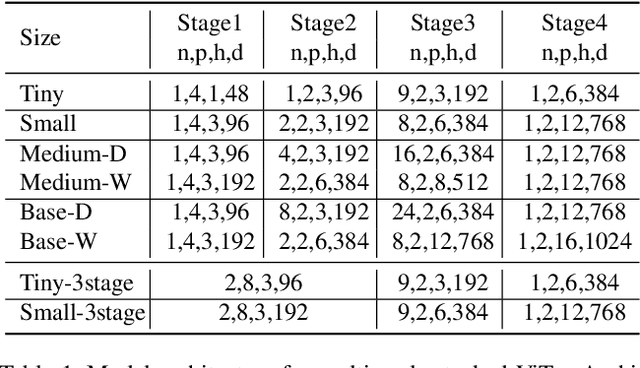
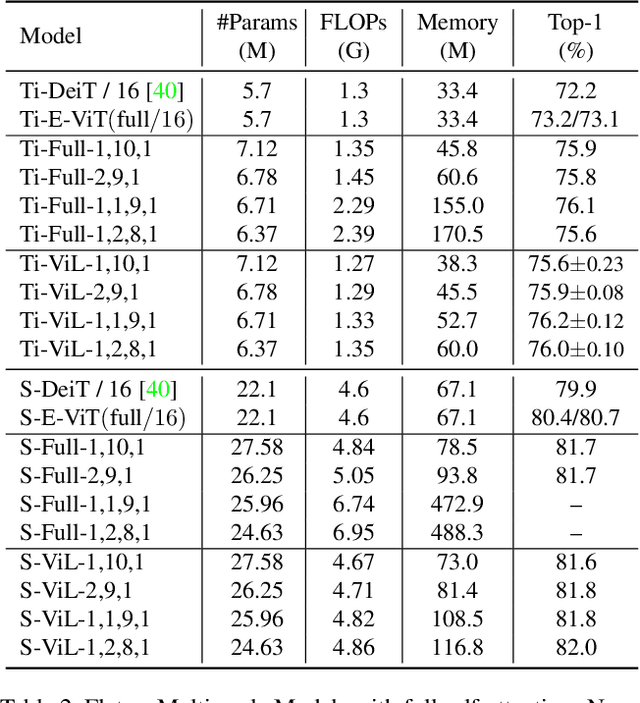
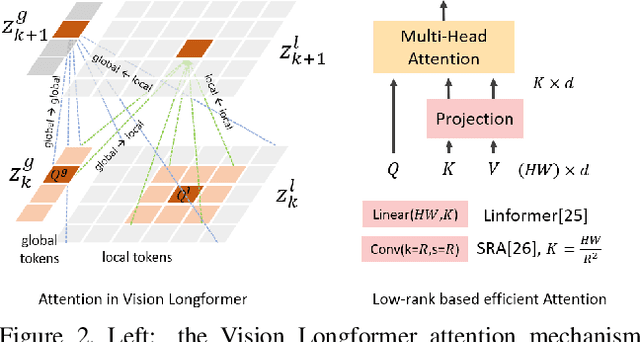
This paper presents a new Vision Transformer (ViT) architecture Multi-Scale Vision Longformer, which significantly enhances the ViT of \cite{dosovitskiy2020image} for encoding high-resolution images using two techniques. The first is the multi-scale model structure, which provides image encodings at multiple scales with manageable computational cost. The second is the attention mechanism of vision Longformer, which is a variant of Longformer \cite{beltagy2020longformer}, originally developed for natural language processing, and achieves a linear complexity w.r.t. the number of input tokens. A comprehensive empirical study shows that the new ViT significantly outperforms several strong baselines, including the existing ViT models and their ResNet counterparts, and the Pyramid Vision Transformer from a concurrent work \cite{wang2021pyramid}, on a range of vision tasks, including image classification, object detection, and segmentation. The models and source code used in this study will be released to public soon.
Out-of-distribution Prediction with Invariant Risk Minimization: The Limitation and An Effective Fix
Jan 16, 2021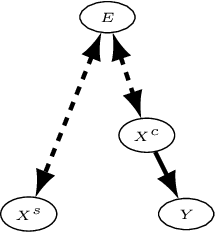
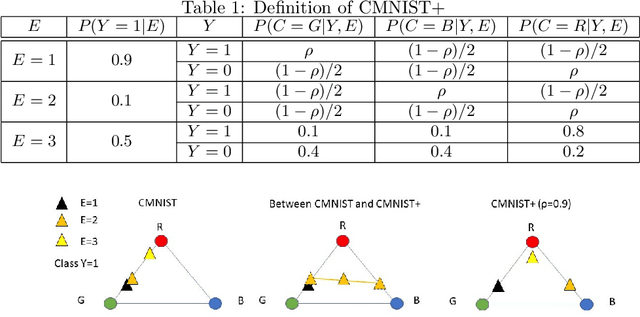

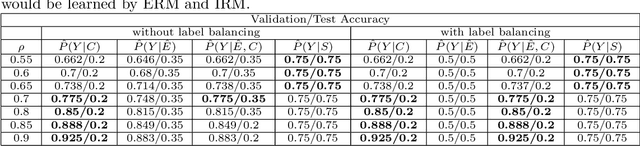
This work considers the out-of-distribution (OOD) prediction problem where (1)~the training data are from multiple domains and (2)~the test domain is unseen in the training. DNNs fail in OOD prediction because they are prone to pick up spurious correlations. Recently, Invariant Risk Minimization (IRM) is proposed to address this issue. Its effectiveness has been demonstrated in the colored MNIST experiment. Nevertheless, we find that the performance of IRM can be dramatically degraded under \emph{strong $\Lambda$ spuriousness} -- when the spurious correlation between the spurious features and the class label is strong due to the strong causal influence of their common cause, the domain label, on both of them (see Fig. 1). In this work, we try to answer the questions: why does IRM fail in the aforementioned setting? Why does IRM work for the original colored MNIST dataset? How can we fix this problem of IRM? Then, we propose a simple and effective approach to fix the problem of IRM. We combine IRM with conditional distribution matching to avoid a specific type of spurious correlation under strong $\Lambda$ spuriousness. Empirically, we design a series of semi synthetic datasets -- the colored MNIST plus, which exposes the problems of IRM and demonstrates the efficacy of the proposed method.
VinVL: Making Visual Representations Matter in Vision-Language Models
Jan 02, 2021


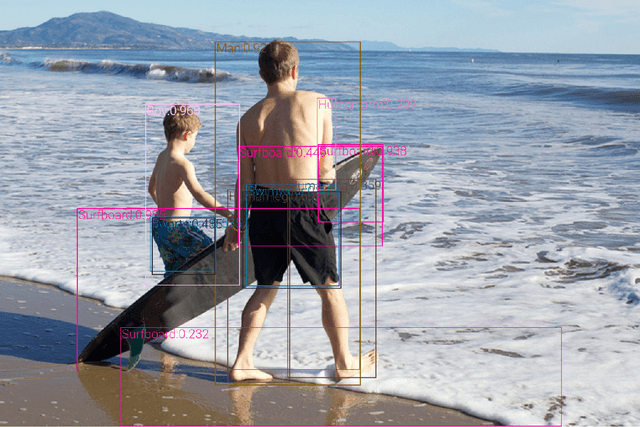
This paper presents a detailed study of improving visual representations for vision language (VL) tasks and develops an improved object detection model to provide object-centric representations of images. Compared to the most widely used \emph{bottom-up and top-down} model \cite{anderson2018bottom}, the new model is bigger, better-designed for VL tasks, and pre-trained on much larger training corpora that combine multiple public annotated object detection datasets. Therefore, it can generate representations of a richer collection of visual objects and concepts. While previous VL research focuses mainly on improving the vision-language fusion model and leaves the object detection model improvement untouched, we show that visual features matter significantly in VL models. In our experiments we feed the visual features generated by the new object detection model into a Transformer-based VL fusion model \oscar \cite{li2020oscar}, and utilize an improved approach \short\ to pre-train the VL model and fine-tune it on a wide range of downstream VL tasks. Our results show that the new visual features significantly improve the performance across all VL tasks, creating new state-of-the-art results on seven public benchmarks. We will release the new object detection model to public.
MiniVLM: A Smaller and Faster Vision-Language Model
Dec 13, 2020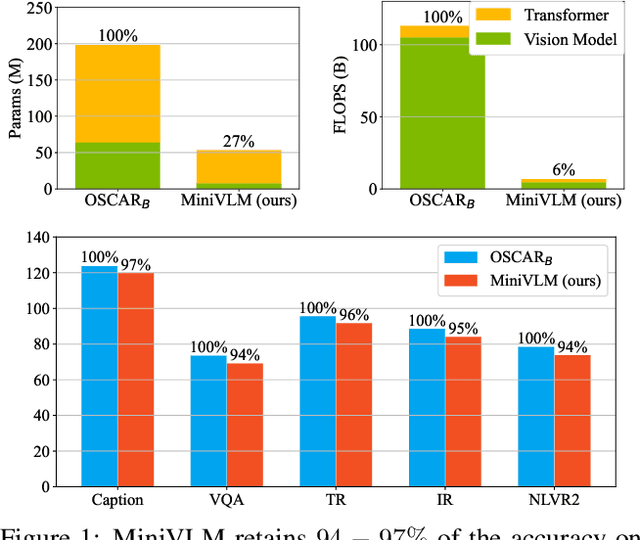
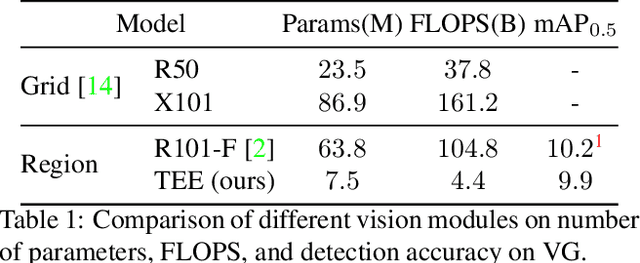
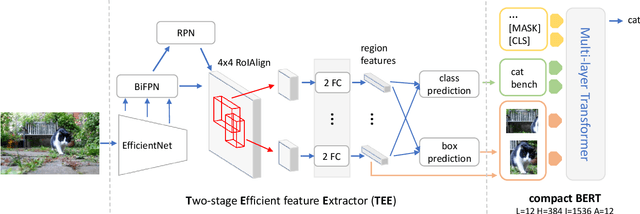
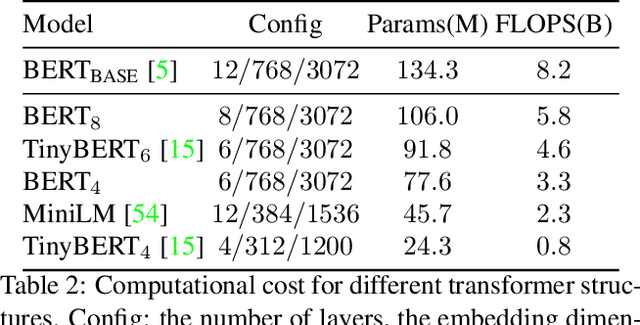
Recent vision-language (VL) studies have shown remarkable progress by learning generic representations from massive image-text pairs with transformer models and then fine-tuning on downstream VL tasks. While existing research has been focused on achieving high accuracy with large pre-trained models, building a lightweight model is of great value in practice but is less explored. In this paper, we propose a smaller and faster VL model, MiniVLM, which can be finetuned with good performance on various downstream tasks like its larger counterpart. MiniVLM consists of two modules, a vision feature extractor and a transformer-based vision-language fusion module. We design a Two-stage Efficient feature Extractor (TEE), inspired by the one-stage EfficientDet network, to significantly reduce the time cost of visual feature extraction by $95\%$, compared to a baseline model. We adopt the MiniLM structure to reduce the computation cost of the transformer module after comparing different compact BERT models. In addition, we improve the MiniVLM pre-training by adding $7M$ Open Images data, which are pseudo-labeled by a state-of-the-art captioning model. We also pre-train with high-quality image tags obtained from a strong tagging model to enhance cross-modality alignment. The large models are used offline without adding any overhead in fine-tuning and inference. With the above design choices, our MiniVLM reduces the model size by $73\%$ and the inference time cost by $94\%$ while being able to retain $94-97\%$ of the accuracy on multiple VL tasks. We hope that MiniVLM helps ease the use of the state-of-the-art VL research for on-the-edge applications.
MagGAN: High-Resolution Face Attribute Editing with Mask-Guided Generative Adversarial Network
Oct 03, 2020
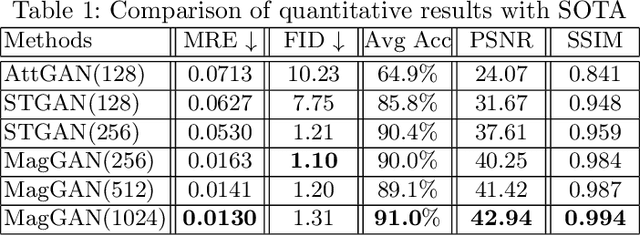

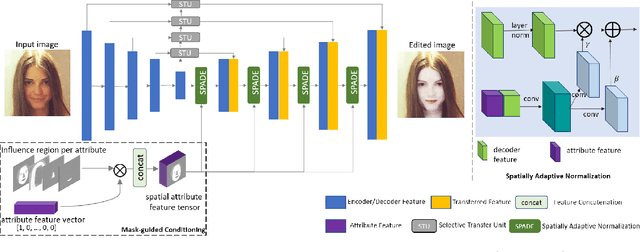
We present Mask-guided Generative Adversarial Network (MagGAN) for high-resolution face attribute editing, in which semantic facial masks from a pre-trained face parser are used to guide the fine-grained image editing process. With the introduction of a mask-guided reconstruction loss, MagGAN learns to only edit the facial parts that are relevant to the desired attribute changes, while preserving the attribute-irrelevant regions (e.g., hat, scarf for modification `To Bald'). Further, a novel mask-guided conditioning strategy is introduced to incorporate the influence region of each attribute change into the generator. In addition, a multi-level patch-wise discriminator structure is proposed to scale our model for high-resolution ($1024 \times 1024$) face editing. Experiments on the CelebA benchmark show that the proposed method significantly outperforms prior state-of-the-art approaches in terms of both image quality and editing performance.
Novel Human-Object Interaction Detection via Adversarial Domain Generalization
May 22, 2020
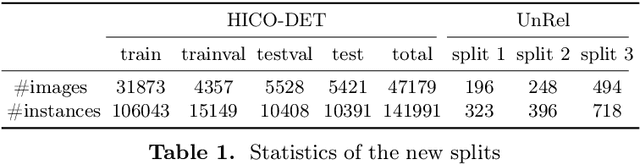
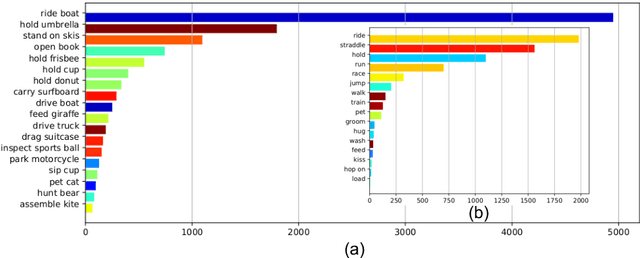
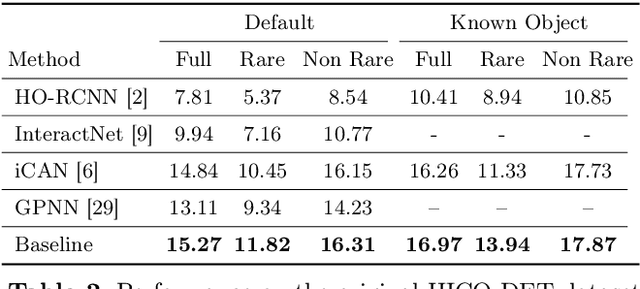
We study in this paper the problem of novel human-object interaction (HOI) detection, aiming at improving the generalization ability of the model to unseen scenarios. The challenge mainly stems from the large compositional space of objects and predicates, which leads to the lack of sufficient training data for all the object-predicate combinations. As a result, most existing HOI methods heavily rely on object priors and can hardly generalize to unseen combinations. To tackle this problem, we propose a unified framework of adversarial domain generalization to learn object-invariant features for predicate prediction. To measure the performance improvement, we create a new split of the HICO-DET dataset, where the HOIs in the test set are all unseen triplet categories in the training set. Our experiments show that the proposed framework significantly increases the performance by up to 50% on the new split of HICO-DET dataset and up to 125% on the UnRel dataset for auxiliary evaluation in detecting novel HOIs.
Oscar: Object-Semantics Aligned Pre-training for Vision-Language Tasks
May 18, 2020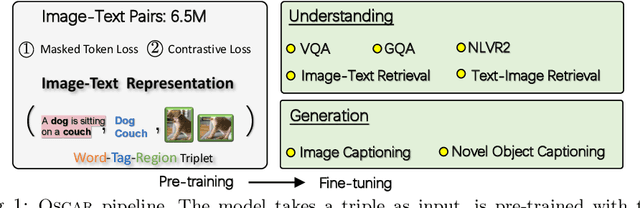

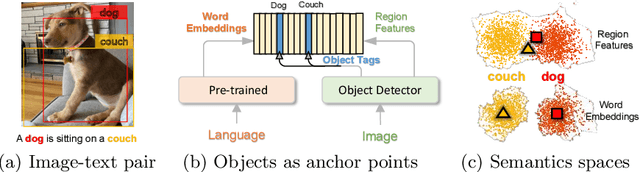
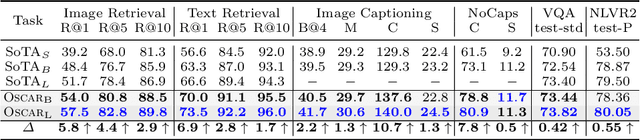
Large-scale pre-training methods of learning cross-modal representations on image-text pairs are becoming popular for vision-language tasks. While existing methods simply concatenate image region features and text features as input to the model to be pre-trained and use self-attention to learn image-text semantic alignments in a brute force manner, in this paper, we propose a new learning method Oscar (Object-Semantics Aligned Pre-training), which uses object tags detected in images as anchor points to significantly ease the learning of alignments. Our method is motivated by the observation that the salient objects in an image can be accurately detected, and are often mentioned in the paired text. We pre-train an Oscar model on the public corpus of 6.5 million text-image pairs, and fine-tune it on downstream tasks, creating new state-of-the-arts on six well-established vision-language understanding and generation tasks.