 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenAI GPT-5 System Card
Dec 19, 2025This is the system card published alongside the OpenAI GPT-5 launch, August 2025. GPT-5 is a unified system with a smart and fast model that answers most questions, a deeper reasoning model for harder problems, and a real-time router that quickly decides which model to use based on conversation type, complexity, tool needs, and explicit intent (for example, if you say 'think hard about this' in the prompt). The router is continuously trained on real signals, including when users switch models, preference rates for responses, and measured correctness, improving over time. Once usage limits are reached, a mini version of each model handles remaining queries. This system card focuses primarily on gpt-5-thinking and gpt-5-main, while evaluations for other models are available in the appendix. The GPT-5 system not only outperforms previous models on benchmarks and answers questions more quickly, but -- more importantly -- is more useful for real-world queries. We've made significant advances in reducing hallucinations, improving instruction following, and minimizing sycophancy, and have leveled up GPT-5's performance in three of ChatGPT's most common uses: writing, coding, and health. All of the GPT-5 models additionally feature safe-completions, our latest approach to safety training to prevent disallowed content. Similarly to ChatGPT agent, we have decided to treat gpt-5-thinking as High capability in the Biological and Chemical domain under our Preparedness Framework, activating the associated safeguards. While we do not have definitive evidence that this model could meaningfully help a novice to create severe biological harm -- our defined threshold for High capability -- we have chosen to take a precautionary approach.
OpenAI o1 System Card
Dec 21, 2024



The o1 model series is trained with large-scale reinforcement learning to reason using chain of thought. These advanced reasoning capabilities provide new avenues for improving the safety and robustness of our models. In particular, our models can reason about our safety policies in context when responding to potentially unsafe prompts, through deliberative alignment. This leads to state-of-the-art performance on certain benchmarks for risks such as generating illicit advice, choosing stereotyped responses, and succumbing to known jailbreaks. Training models to incorporate a chain of thought before answering has the potential to unlock substantial benefits, while also increasing potential risks that stem from heightened intelligence. Our results underscore the need for building robust alignment methods, extensively stress-testing their efficacy, and maintaining meticulous risk management protocols. This report outlines the safety work carried out for the OpenAI o1 and OpenAI o1-mini models, including safety evaluations, external red teaming, and Preparedness Framework evaluations.
Whose Opinions Do Language Models Reflect?
Mar 30, 2023



Language models (LMs) are increasingly being used in open-ended contexts, where the opinions reflected by LMs in response to subjective queries can have a profound impact, both on user satisfaction, as well as shaping the views of society at large. In this work, we put forth a quantitative framework to investigate the opinions reflected by LMs -- by leveraging high-quality public opinion polls and their associated human responses. Using this framework, we create OpinionsQA, a new dataset for evaluating the alignment of LM opinions with those of 60 US demographic groups over topics ranging from abortion to automation. Across topics, we find substantial misalignment between the views reflected by current LMs and those of US demographic groups: on par with the Democrat-Republican divide on climate change. Notably, this misalignment persists even after explicitly steering the LMs towards particular demographic groups. Our analysis not only confirms prior observations about the left-leaning tendencies of some human feedback-tuned LMs, but also surfaces groups whose opinions are poorly reflected by current LMs (e.g., 65+ and widowed individuals). Our code and data are available at https://github.com/tatsu-lab/opinions_qa.
Data Selection for Language Models via Importance Resampling
Feb 06, 2023



Selecting a suitable training dataset is crucial for both general-domain (e.g., GPT-3) and domain-specific (e.g., Codex) language models (LMs). We formalize this data selection problem as selecting a subset of a large raw unlabeled dataset to match a desired target distribution, given some unlabeled target samples. Due to the large scale and dimensionality of the raw text data, existing methods use simple heuristics to select data that are similar to a high-quality reference corpus (e.g., Wikipedia), or leverage experts to manually curate data. Instead, we extend the classic importance resampling approach used in low-dimensions for LM data selection. Crucially, we work in a reduced feature space to make importance weight estimation tractable over the space of text. To determine an appropriate feature space, we first show that KL reduction, a data metric that measures the proximity between selected data and the target in a feature space, has high correlation with average accuracy on 8 downstream tasks (r=0.89) when computed with simple n-gram features. From this observation, we present Data Selection with Importance Resampling (DSIR), an efficient and scalable algorithm that estimates importance weights in a reduced feature space (e.g., n-gram features in our instantiation) and selects data with importance resampling according to these weights. When training general-domain models (target is Wikipedia + books), DSIR improves over random selection and heuristic filtering baselines by 2--2.5% on the GLUE benchmark. When performing continued pretraining towards a specific domain, DSIR performs comparably to expert curated data across 8 target distributions.
Holistic Evaluation of Language Models
Nov 16, 2022



Language models (LMs) are becoming the foundation for almost all major language technologies, but their capabilities, limitations, and risks are not well understood. We present Holistic Evaluation of Language Models (HELM) to improve the transparency of language models. First, we taxonomize the vast space of potential scenarios (i.e. use cases) and metrics (i.e. desiderata) that are of interest for LMs. Then we select a broad subset based on coverage and feasibility, noting what's missing or underrepresented (e.g. question answering for neglected English dialects, metrics for trustworthiness). Second, we adopt a multi-metric approach: We measure 7 metrics (accuracy, calibration, robustness, fairness, bias, toxicity, and efficiency) for each of 16 core scenarios when possible (87.5% of the time). This ensures metrics beyond accuracy don't fall to the wayside, and that trade-offs are clearly exposed. We also perform 7 targeted evaluations, based on 26 targeted scenarios, to analyze specific aspects (e.g. reasoning, disinformation). Third, we conduct a large-scale evaluation of 30 prominent language models (spanning open, limited-access, and closed models) on all 42 scenarios, 21 of which were not previously used in mainstream LM evaluation. Prior to HELM, models on average were evaluated on just 17.9% of the core HELM scenarios, with some prominent models not sharing a single scenario in common. We improve this to 96.0%: now all 30 models have been densely benchmarked on the same core scenarios and metrics under standardized conditions. Our evaluation surfaces 25 top-level findings. For full transparency, we release all raw model prompts and completions publicly for further analysis, as well as a general modular toolkit. We intend for HELM to be a living benchmark for the community, continuously updated with new scenarios, metrics, and models.
Is a Caption Worth a Thousand Images? A Controlled Study for Representation Learning
Jul 15, 2022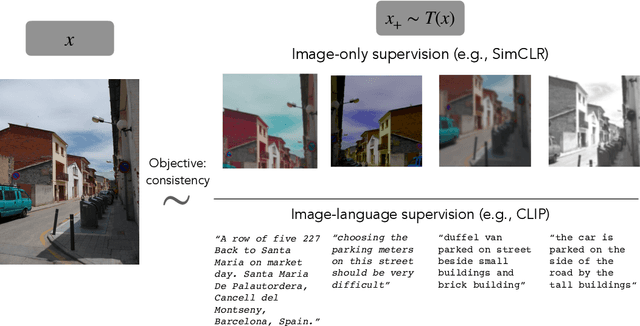
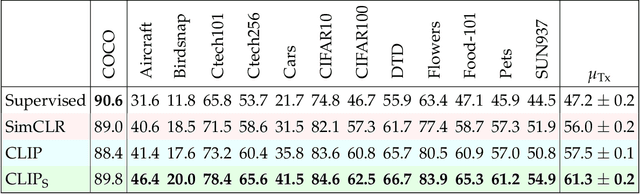

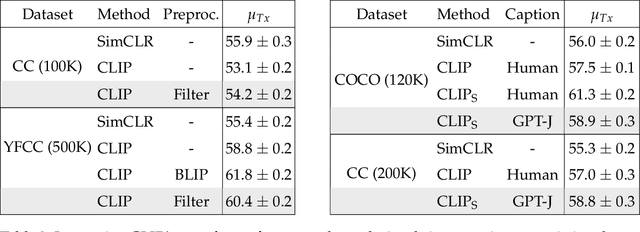
The development of CLIP [Radford et al., 2021] has sparked a debate on whether language supervision can result in vision models with more transferable representations than traditional image-only methods. Our work studies this question through a carefully controlled comparison of two approaches in terms of their ability to learn representations that generalize to downstream classification tasks. We find that when the pre-training dataset meets certain criteria -- it is sufficiently large and contains descriptive captions with low variability -- image-only methods do not match CLIP's transfer performance, even when they are trained with more image data. However, contrary to what one might expect, there are practical settings in which these criteria are not met, wherein added supervision through captions is actually detrimental. Motivated by our findings, we devise simple prescriptions to enable CLIP to better leverage the language information present in existing pre-training datasets.
Editing a classifier by rewriting its prediction rules
Dec 02, 2021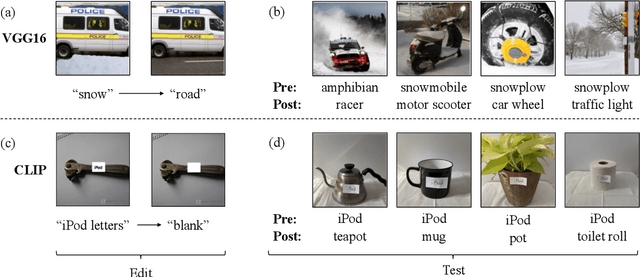

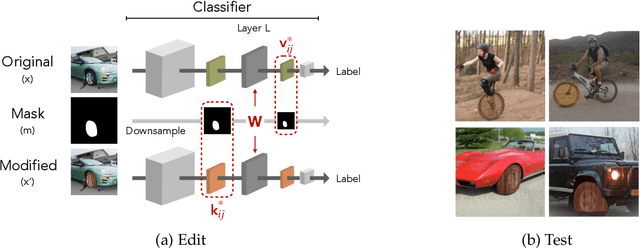
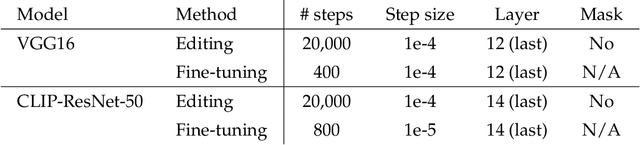
We present a methodology for modifying the behavior of a classifier by directly rewriting its prediction rules. Our approach requires virtually no additional data collection and can be applied to a variety of settings, including adapting a model to new environments, and modifying it to ignore spurious features. Our code is available at https://github.com/MadryLab/EditingClassifiers .
3DB: A Framework for Debugging Computer Vision Models
Jun 07, 2021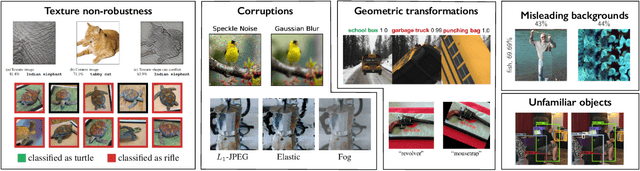
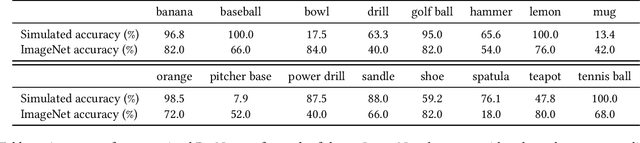

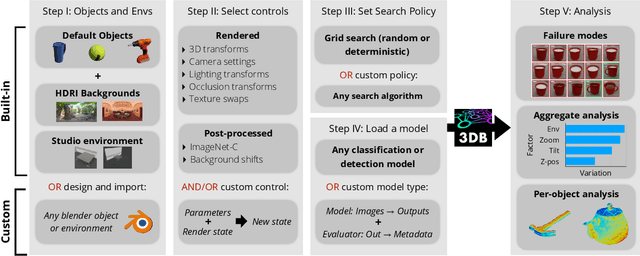
We introduce 3DB: an extendable, unified framework for testing and debugging vision models using photorealistic simulation. We demonstrate, through a wide range of use cases, that 3DB allows users to discover vulnerabilities in computer vision systems and gain insights into how models make decisions. 3DB captures and generalizes many robustness analyses from prior work, and enables one to study their interplay. Finally, we find that the insights generated by the system transfer to the physical world. We are releasing 3DB as a library (https://github.com/3db/3db) alongside a set of example analyses, guides, and documentation: https://3db.github.io/3db/ .
Leveraging Sparse Linear Layers for Debuggable Deep Networks
May 11, 2021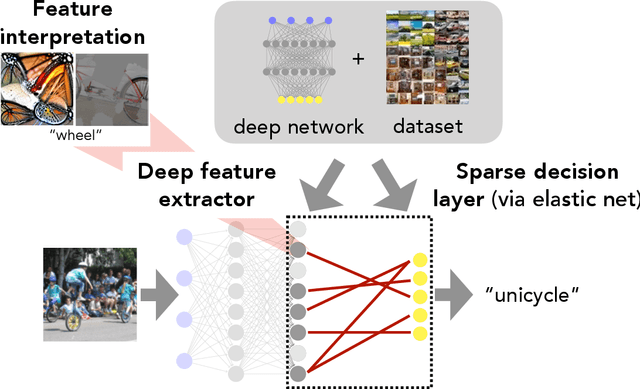

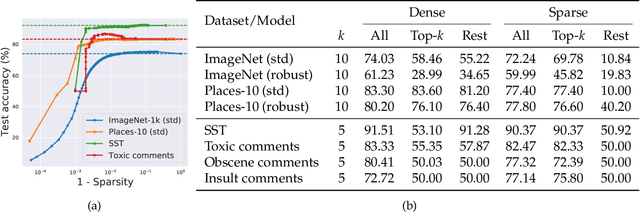

We show how fitting sparse linear models over learned deep feature representations can lead to more debuggable neural networks. These networks remain highly accurate while also being more amenable to human interpretation, as we demonstrate quantiatively via numerical and human experiments. We further illustrate how the resulting sparse explanations can help to identify spurious correlations, explain misclassifications, and diagnose model biases in vision and language tasks. The code for our toolkit can be found at https://github.com/madrylab/debuggabledeepnetworks.
BREEDS: Benchmarks for Subpopulation Shift
Aug 11, 2020


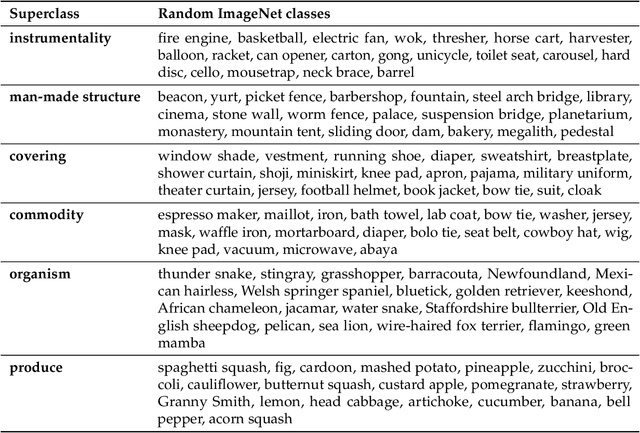
We develop a methodology for assessing the robustness of models to subpopulation shift---specifically, their ability to generalize to novel data subpopulations that were not observed during training. Our approach leverages the class structure underlying existing datasets to control the data subpopulations that comprise the training and test distributions. This enables us to synthesize realistic distribution shifts whose sources can be precisely controlled and characterized, within existing large-scale datasets. Applying this methodology to the ImageNet dataset, we create a suite of subpopulation shift benchmarks of varying granularity. We then validate that the corresponding shifts are tractable by obtaining human baselines for them. Finally, we utilize these benchmarks to measure the sensitivity of standard model architectures as well as the effectiveness of off-the-shelf train-time robustness interventions. Code and data available at https://github.com/MadryLab/BREEDS-Benchmarks .