 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCost-Effective, Low Latency Vector Search with Azure Cosmos DB
May 09, 2025Vector indexing enables semantic search over diverse corpora and has become an important interface to databases for both users and AI agents. Efficient vector search requires deep optimizations in database systems. This has motivated a new class of specialized vector databases that optimize for vector search quality and cost. Instead, we argue that a scalable, high-performance, and cost-efficient vector search system can be built inside a cloud-native operational database like Azure Cosmos DB while leveraging the benefits of a distributed database such as high availability, durability, and scale. We do this by deeply integrating DiskANN, a state-of-the-art vector indexing library, inside Azure Cosmos DB NoSQL. This system uses a single vector index per partition stored in existing index trees, and kept in sync with underlying data. It supports < 20ms query latency over an index spanning 10 million of vectors, has stable recall over updates, and offers nearly 15x and 41x lower query cost compared to Zilliz and Pinecone serverless enterprise products. It also scales out to billions of vectors via automatic partitioning. This convergent design presents a point in favor of integrating vector indices into operational databases in the context of recent debates on specialized vector databases, and offers a template for vector indexing in other databases.
Global Convergence and Rich Feature Learning in $L$-Layer Infinite-Width Neural Networks under $μ$P Parametrization
Mar 12, 2025



Despite deep neural networks' powerful representation learning capabilities, theoretical understanding of how networks can simultaneously achieve meaningful feature learning and global convergence remains elusive. Existing approaches like the neural tangent kernel (NTK) are limited because features stay close to their initialization in this parametrization, leaving open questions about feature properties during substantial evolution. In this paper, we investigate the training dynamics of infinitely wide, $L$-layer neural networks using the tensor program (TP) framework. Specifically, we show that, when trained with stochastic gradient descent (SGD) under the Maximal Update parametrization ($\mu$P) and mild conditions on the activation function, SGD enables these networks to learn linearly independent features that substantially deviate from their initial values. This rich feature space captures relevant data information and ensures that any convergent point of the training process is a global minimum. Our analysis leverages both the interactions among features across layers and the properties of Gaussian random variables, providing new insights into deep representation learning. We further validate our theoretical findings through experiments on real-world datasets.
A Spectral Condition for Feature Learning
Oct 26, 2023



The push to train ever larger neural networks has motivated the study of initialization and training at large network width. A key challenge is to scale training so that a network's internal representations evolve nontrivially at all widths, a process known as feature learning. Here, we show that feature learning is achieved by scaling the spectral norm of weight matrices and their updates like $\sqrt{\texttt{fan-out}/\texttt{fan-in}}$, in contrast to widely used but heuristic scalings based on Frobenius norm and entry size. Our spectral scaling analysis also leads to an elementary derivation of \emph{maximal update parametrization}. All in all, we aim to provide the reader with a solid conceptual understanding of feature learning in neural networks.
Tensor Programs VI: Feature Learning in Infinite-Depth Neural Networks
Oct 12, 2023



By classifying infinite-width neural networks and identifying the *optimal* limit, Tensor Programs IV and V demonstrated a universal way, called $\mu$P, for *widthwise hyperparameter transfer*, i.e., predicting optimal hyperparameters of wide neural networks from narrow ones. Here we investigate the analogous classification for *depthwise parametrizations* of deep residual networks (resnets). We classify depthwise parametrizations of block multiplier and learning rate by their infinite-width-then-depth limits. In resnets where each block has only one layer, we identify a unique optimal parametrization, called Depth-$\mu$P that extends $\mu$P and show empirically it admits depthwise hyperparameter transfer. We identify *feature diversity* as a crucial factor in deep networks, and Depth-$\mu$P can be characterized as maximizing both feature learning and feature diversity. Exploiting this, we find that absolute value, among all homogeneous nonlinearities, maximizes feature diversity and indeed empirically leads to significantly better performance. However, if each block is deeper (such as modern transformers), then we find fundamental limitations in all possible infinite-depth limits of such parametrizations, which we illustrate both theoretically and empirically on simple networks as well as Megatron transformer trained on Common Crawl.
Tensor Programs IVb: Adaptive Optimization in the Infinite-Width Limit
Aug 07, 2023



Going beyond stochastic gradient descent (SGD), what new phenomena emerge in wide neural networks trained by adaptive optimizers like Adam? Here we show: The same dichotomy between feature learning and kernel behaviors (as in SGD) holds for general optimizers as well, including Adam -- albeit with a nonlinear notion of "kernel." We derive the corresponding "neural tangent" and "maximal update" limits for any architecture. Two foundational advances underlie the above results: 1) A new Tensor Program language, NEXORT, that can express how adaptive optimizers process gradients into updates. 2) The introduction of bra-ket notation to drastically simplify expressions and calculations in Tensor Programs. This work summarizes and generalizes all previous results in the Tensor Programs series of papers.
Width and Depth Limits Commute in Residual Networks
Feb 01, 2023



We show that taking the width and depth to infinity in a deep neural network with skip connections, when branches are scaled by $1/\sqrt{depth}$ (the only nontrivial scaling), result in the same covariance structure no matter how that limit is taken. This explains why the standard infinite-width-then-depth approach provides practical insights even for networks with depth of the same order as width. We also demonstrate that the pre-activations, in this case, have Gaussian distributions which has direct applications in Bayesian deep learning. We conduct extensive simulations that show an excellent match with our theoretical findings.
High-dimensional Asymptotics of Feature Learning: How One Gradient Step Improves the Representation
May 03, 2022
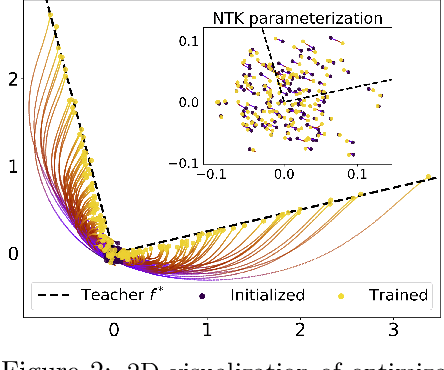
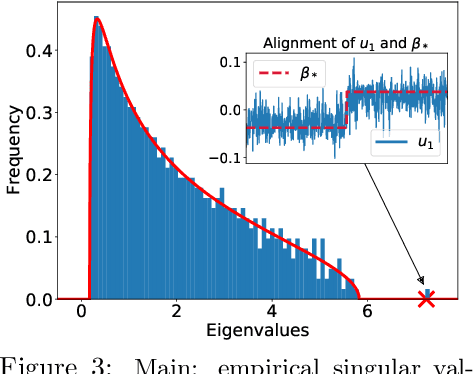
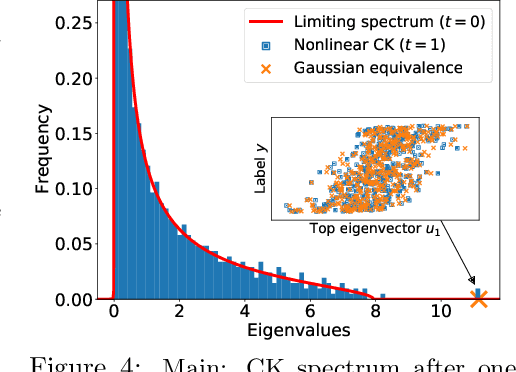
We study the first gradient descent step on the first-layer parameters $\boldsymbol{W}$ in a two-layer neural network: $f(\boldsymbol{x}) = \frac{1}{\sqrt{N}}\boldsymbol{a}^\top\sigma(\boldsymbol{W}^\top\boldsymbol{x})$, where $\boldsymbol{W}\in\mathbb{R}^{d\times N}, \boldsymbol{a}\in\mathbb{R}^{N}$ are randomly initialized, and the training objective is the empirical MSE loss: $\frac{1}{n}\sum_{i=1}^n (f(\boldsymbol{x}_i)-y_i)^2$. In the proportional asymptotic limit where $n,d,N\to\infty$ at the same rate, and an idealized student-teacher setting, we show that the first gradient update contains a rank-1 "spike", which results in an alignment between the first-layer weights and the linear component of the teacher model $f^*$. To characterize the impact of this alignment, we compute the prediction risk of ridge regression on the conjugate kernel after one gradient step on $\boldsymbol{W}$ with learning rate $\eta$, when $f^*$ is a single-index model. We consider two scalings of the first step learning rate $\eta$. For small $\eta$, we establish a Gaussian equivalence property for the trained feature map, and prove that the learned kernel improves upon the initial random features model, but cannot defeat the best linear model on the input. Whereas for sufficiently large $\eta$, we prove that for certain $f^*$, the same ridge estimator on trained features can go beyond this "linear regime" and outperform a wide range of random features and rotationally invariant kernels. Our results demonstrate that even one gradient step can lead to a considerable advantage over random features, and highlight the role of learning rate scaling in the initial phase of training.
Tensor Programs V: Tuning Large Neural Networks via Zero-Shot Hyperparameter Transfer
Mar 28, 2022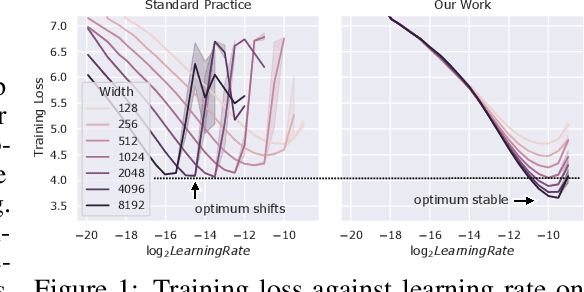

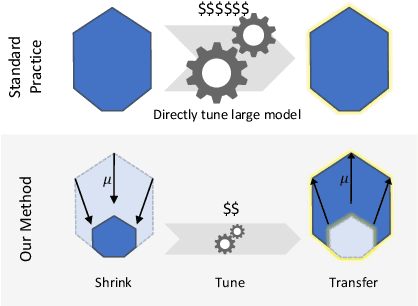

Hyperparameter (HP) tuning in deep learning is an expensive process, prohibitively so for neural networks (NNs) with billions of parameters. We show that, in the recently discovered Maximal Update Parametrization (muP), many optimal HPs remain stable even as model size changes. This leads to a new HP tuning paradigm we call muTransfer: parametrize the target model in muP, tune the HP indirectly on a smaller model, and zero-shot transfer them to the full-sized model, i.e., without directly tuning the latter at all. We verify muTransfer on Transformer and ResNet. For example, 1) by transferring pretraining HPs from a model of 13M parameters, we outperform published numbers of BERT-large (350M parameters), with a total tuning cost equivalent to pretraining BERT-large once; 2) by transferring from 40M parameters, we outperform published numbers of the 6.7B GPT-3 model, with tuning cost only 7% of total pretraining cost. A Pytorch implementation of our technique can be found at github.com/microsoft/mup and installable via `pip install mup`.
CLUES: Few-Shot Learning Evaluation in Natural Language Understanding
Nov 04, 2021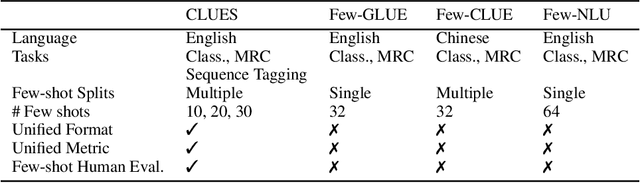
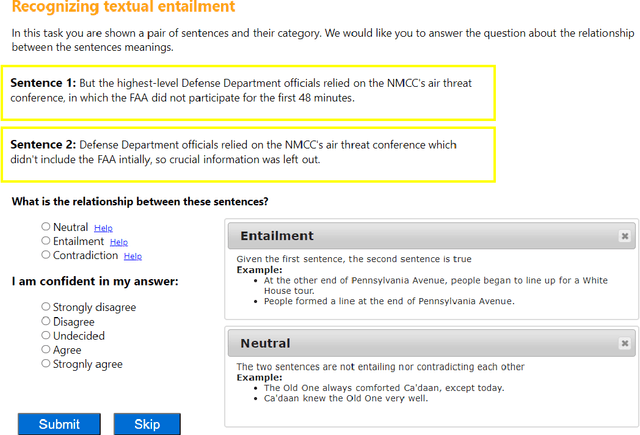

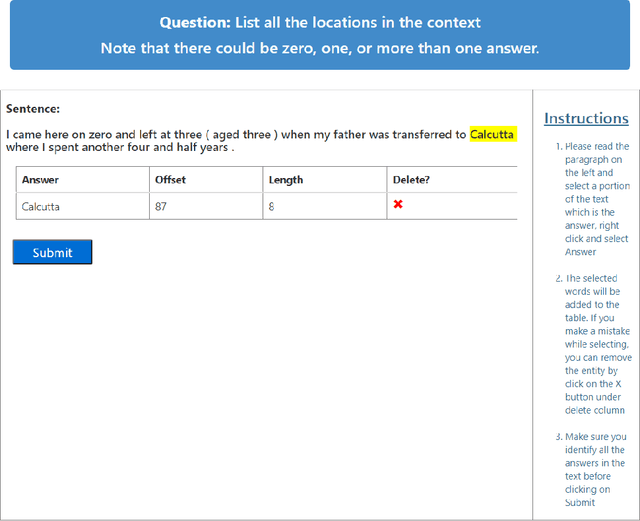
Most recent progress in natural language understanding (NLU) has been driven, in part, by benchmarks such as GLUE, SuperGLUE, SQuAD, etc. In fact, many NLU models have now matched or exceeded "human-level" performance on many tasks in these benchmarks. Most of these benchmarks, however, give models access to relatively large amounts of labeled data for training. As such, the models are provided far more data than required by humans to achieve strong performance. That has motivated a line of work that focuses on improving few-shot learning performance of NLU models. However, there is a lack of standardized evaluation benchmarks for few-shot NLU resulting in different experimental settings in different papers. To help accelerate this line of work, we introduce CLUES (Constrained Language Understanding Evaluation Standard), a benchmark for evaluating the few-shot learning capabilities of NLU models. We demonstrate that while recent models reach human performance when they have access to large amounts of labeled data, there is a huge gap in performance in the few-shot setting for most tasks. We also demonstrate differences between alternative model families and adaptation techniques in the few shot setting. Finally, we discuss several principles and choices in designing the experimental settings for evaluating the true few-shot learning performance and suggest a unified standardized approach to few-shot learning evaluation. We aim to encourage research on NLU models that can generalize to new tasks with a small number of examples. Code and data for CLUES are available at https://github.com/microsoft/CLUES.
Implicit Acceleration and Feature Learning in Infinitely Wide Neural Networks with Bottlenecks
Jul 02, 2021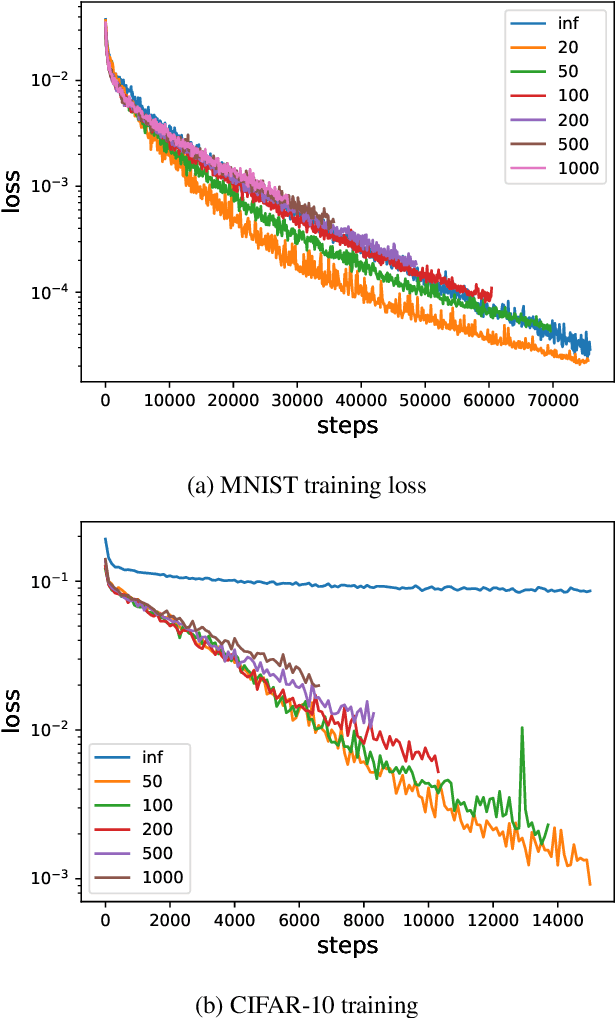
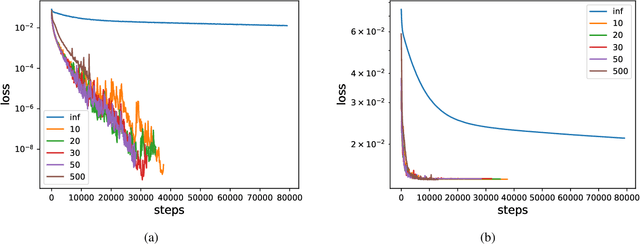
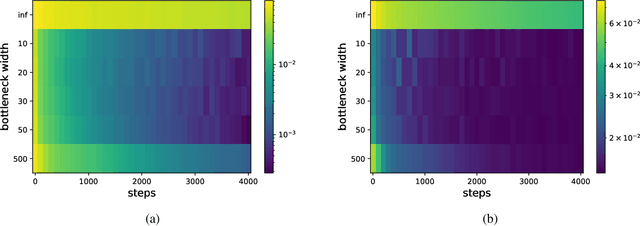
We analyze the learning dynamics of infinitely wide neural networks with a finite sized bottle-neck. Unlike the neural tangent kernel limit, a bottleneck in an otherwise infinite width network al-lows data dependent feature learning in its bottle-neck representation. We empirically show that a single bottleneck in infinite networks dramatically accelerates training when compared to purely in-finite networks, with an improved overall performance. We discuss the acceleration phenomena by drawing similarities to infinitely wide deep linear models, where the acceleration effect of a bottleneck can be understood theoretically.