 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConformal Navigation Transformations with Application to Robot Navigation in Complex Workspaces
Aug 22, 2022
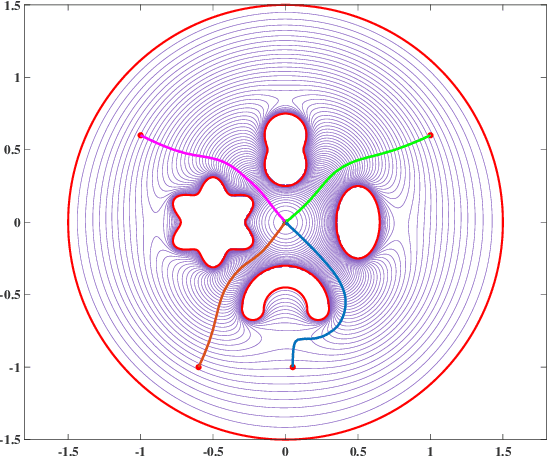
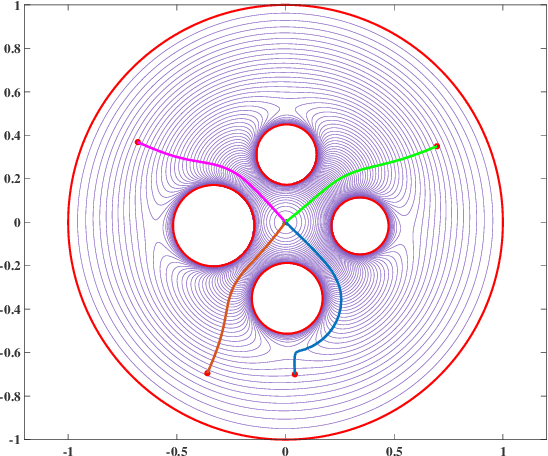
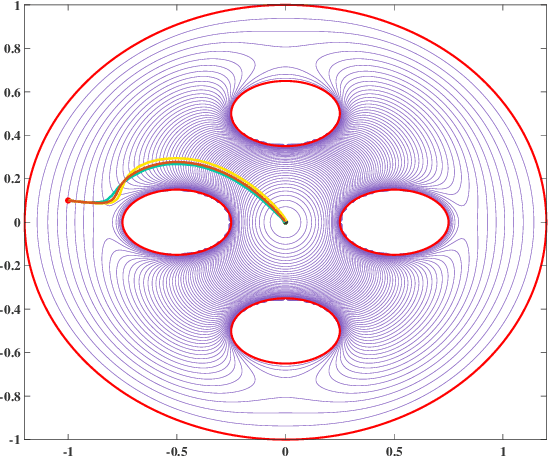
Navigation functions provide both path and motion planning, which can be used to ensure obstacle avoidance and convergence in the sphere world. When dealing with complex and realistic scenarios, constructing a transformation to the sphere world is essential and, at the same time, challenging. This work proposes a novel transformation termed the conformal navigation transformation to achieve collision-free navigation of a robot in a workspace populated with obstacles of arbitrary shapes. The properties of the conformal navigation transformation, including uniqueness, invariance of navigation properties, and no angular deformation, are investigated, which contribute to the solution of the robot navigation problem in complex environments. Based on navigation functions and the proposed transformation, feedback controllers are derived for the automatic guidance and motion control of kinematic and dynamic mobile robots. Moreover, an iterative method is proposed to construct the conformal navigation transformation in a multiply-connected workspace, which transforms the multiply-connected problem into multiple simply-connected problems to achieve fast convergence. In addition to the analytic guarantees, simulation studies verify the effectiveness of the proposed methodology in workspaces with non-trivial obstacles.
VGSwarm: A Vision-based Gene Regulation Network for UAVs Swarm Behavior Emergence
Jun 17, 2022
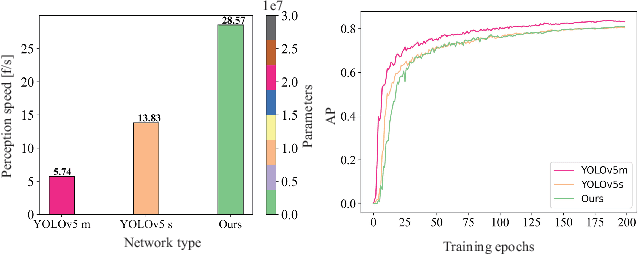
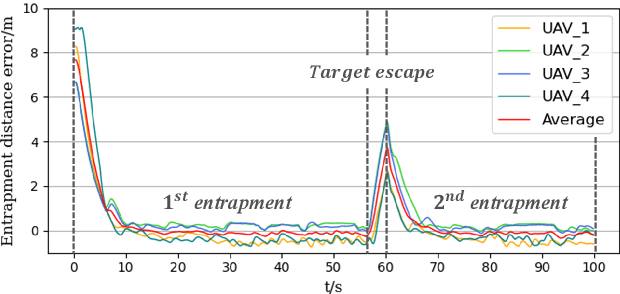

UAVs (Unmanned Aerial Vehicles) dynamic encirclement is an emerging field with great potential. Researchers often get inspirations from biological systems, either from macro-world like fish schools or bird flocks etc, or from micro-world like gene regulatory networks. However, most swarm control algorithms rely on centralized control, global information acquisition, or communication between neighboring agents. In this work, we propose a distributed swarm control method based purely on vision without any direct communications, in which swarm agents of e.g. UAVs can generate an entrapping pattern to encircle an escaping target of UAV based purly on their installed omnidirectional vision sensors. A finite-state-machine describing the behavior model of each individual drone is also designed so that a swarm of drones can accomplish searching and entrapping of the target collectively. We verify the effectiveness and efficiency of the proposed method in various simulation and real-world experiments.
Multimodal Learning with Transformers: A Survey
Jun 13, 2022
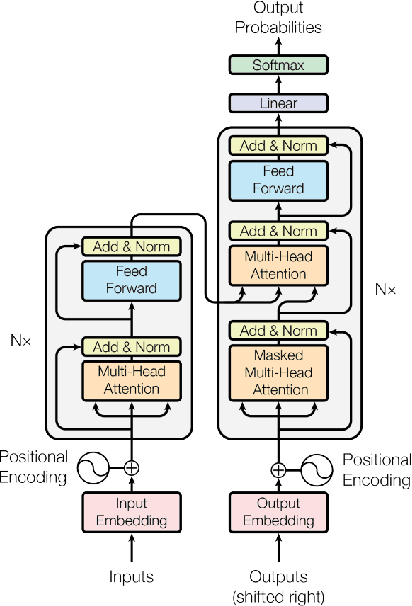
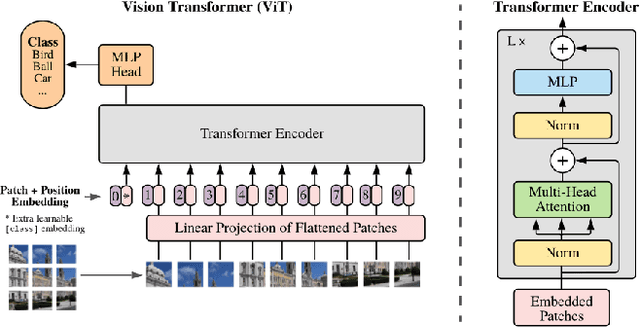
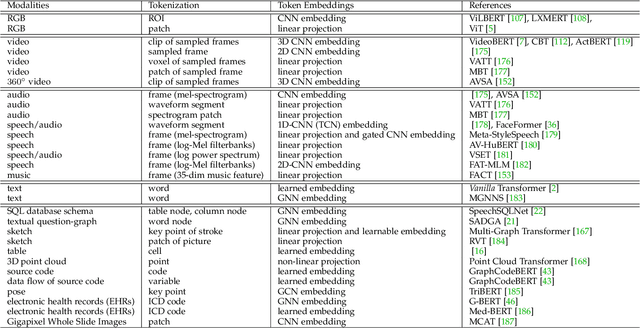
Transformer is a promising neural network learner, and has achieved great success in various machine learning tasks. Thanks to the recent prevalence of multimodal applications and big data, Transformer-based multimodal learning has become a hot topic in AI research. This paper presents a comprehensive survey of Transformer techniques oriented at multimodal data. The main contents of this survey include: (1) a background of multimodal learning, Transformer ecosystem, and the multimodal big data era, (2) a theoretical review of Vanilla Transformer, Vision Transformer, and multimodal Transformers, from a geometrically topological perspective, (3) a review of multimodal Transformer applications, via two important paradigms, i.e., for multimodal pretraining and for specific multimodal tasks, (4) a summary of the common challenges and designs shared by the multimodal Transformer models and applications, and (5) a discussion of open problems and potential research directions for the community.
Factuality Enhanced Language Models for Open-Ended Text Generation
Jun 09, 2022
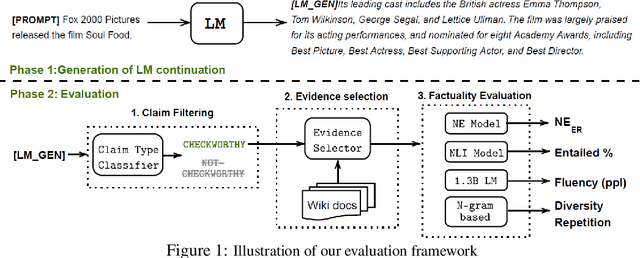
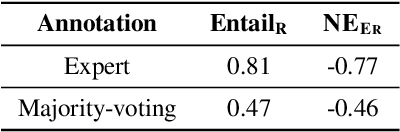
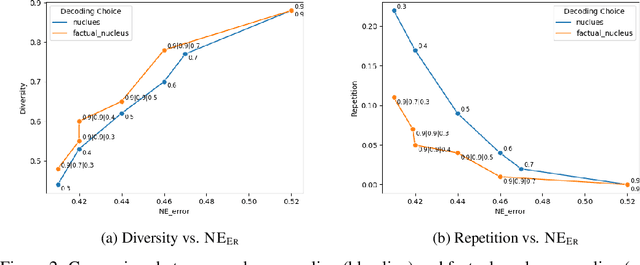
Pretrained language models (LMs) are susceptible to generate text with nonfactual information. In this work, we measure and improve the factual accuracy of large-scale LMs for open-ended text generation. We design the FactualityPrompts test set and metrics to measure the factuality of LM generations. Based on that, we study the factual accuracy of LMs with parameter sizes ranging from 126M to 530B. Interestingly, we find that larger LMs are more factual than smaller ones, although a previous study suggests that larger LMs can be less truthful in terms of misconceptions. In addition, popular sampling algorithms (e.g., top-p) in open-ended text generation can harm the factuality due to the "uniform randomness" introduced at every sampling step. We propose the factual-nucleus sampling algorithm that dynamically adapts the randomness to improve the factuality of generation while maintaining quality. Furthermore, we analyze the inefficiencies of the standard training method in learning correct associations between entities from factual text corpus (e.g., Wikipedia). We propose a factuality-enhanced training method that uses TopicPrefix for better awareness of facts and sentence completion as the training objective, which can vastly reduce the factual errors.
Entailment Tree Explanations via Iterative Retrieval-Generation Reasoner
May 18, 2022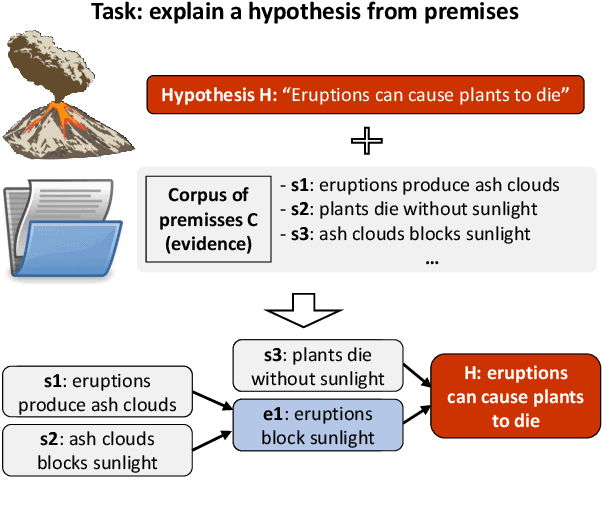
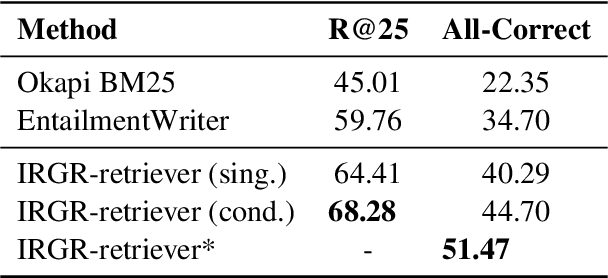
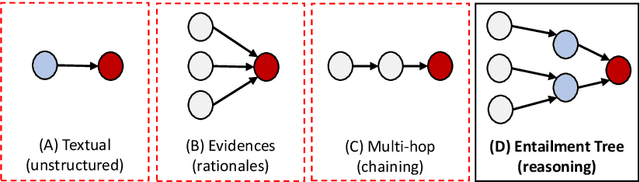
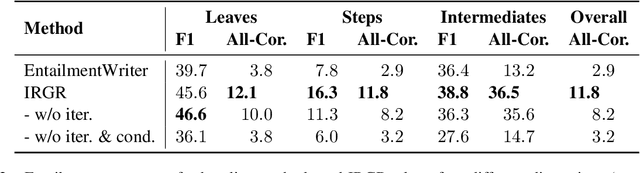
Large language models have achieved high performance on various question answering (QA) benchmarks, but the explainability of their output remains elusive. Structured explanations, called entailment trees, were recently suggested as a way to explain and inspect a QA system's answer. In order to better generate such entailment trees, we propose an architecture called Iterative Retrieval-Generation Reasoner (IRGR). Our model is able to explain a given hypothesis by systematically generating a step-by-step explanation from textual premises. The IRGR model iteratively searches for suitable premises, constructing a single entailment step at a time. Contrary to previous approaches, our method combines generation steps and retrieval of premises, allowing the model to leverage intermediate conclusions, and mitigating the input size limit of baseline encoder-decoder models. We conduct experiments using the EntailmentBank dataset, where we outperform existing benchmarks on premise retrieval and entailment tree generation, with around 300% gain in overall correctness.
Learning to Reorient Objects with Stable Placements Afforded by Extrinsic Supports
May 14, 2022
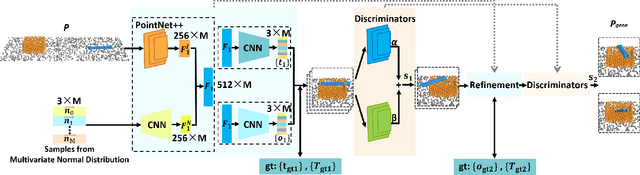
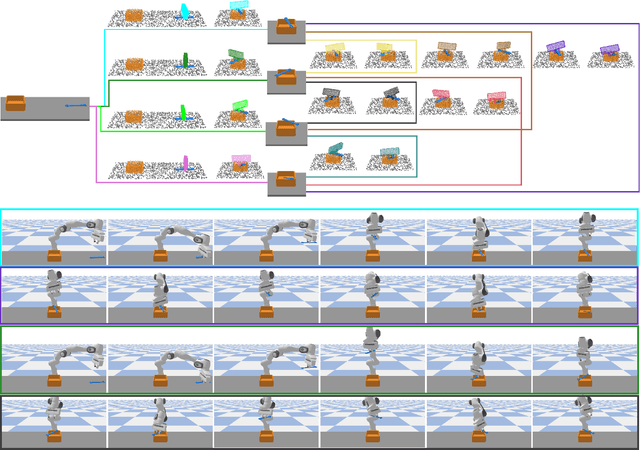
Reorienting objects using extrinsic supporting items on the working platform is a meaningful nonetheless challenging manipulation task, considering the elaborate geometry of objects and the robot's motion planning. In this work, the robot learns to reorient objects through sequential pick-and-place operations according to sensing results from the RGBD camera. We propose generative models to predict objects' stable placements afforded by supporting items from observed point clouds. Then, we build manipulation graphs which enclose shared grasp configurations to connect objects' stable placements for pose transformation. We show in experiments that our method is effective and efficient. Simulation experiments demonstrate that the models can generalize to previously unseen pairs of objects started with random poses on the table. The calculated manipulation graphs are conducive to provide collision-free motions to reorient objects. We employ a robot in the real-world experiments to perform sequential pick-and-place operations, indicating our method is capable of transferring objects' placement poses in real scenes.
BiAIT*: Symmetrical Bidirectional Optimal Path Planning with Adaptive Heuristic
May 14, 2022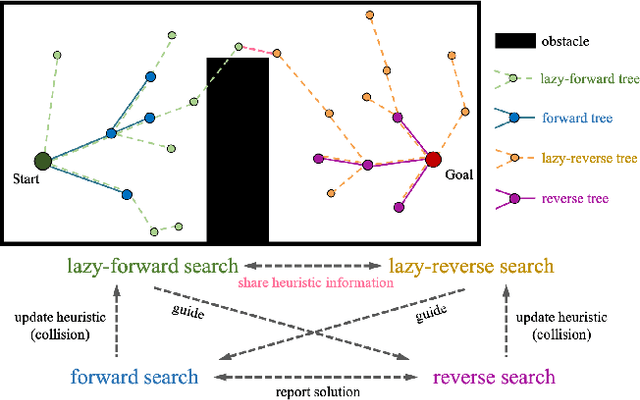
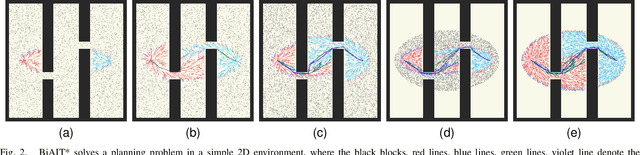
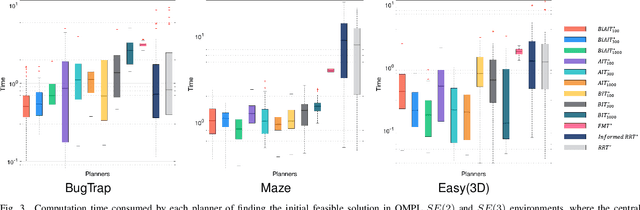

Adaptively Informed Trees (AIT*) develops the problem-specific heuristic under the current topological abstraction of the state space with a lazy-reverse tree that is constructed without collision checking. AIT* can avoid unnecessary searching with the heuristic, which significantly improves the algorithm performance, especially when collision checking is expensive. However, the heuristic estimation in AIT* consumes lots of computation resources, and its asymmetric bidirectional searching strategy cannot fully exploit the potential of the bidirectional method. In this article, we extend AIT* from the asymmetric bidirectional search to the symmetrical bidirectional search, namely BiAIT*. Both the heuristic and space searching in BiAIT* are calculated bidirectionally. The path planner can find the initial solution faster with our proposed method. In addition, when a collision happens, BiAIT* can update the heuristic with less computation. Simulations are carried out to evaluate the performance of the proposed algorithm, and the results show that our algorithm can find the solution faster than the state of the arts. We also analyze the reason for different performances between BiAIT* and AIT*. Furthermore, we discuss two simple but effective modifications to fully exploit the potential of the adaptively heuristic method.
Attention Mechanism based Cognition-level Scene Understanding
Apr 19, 2022
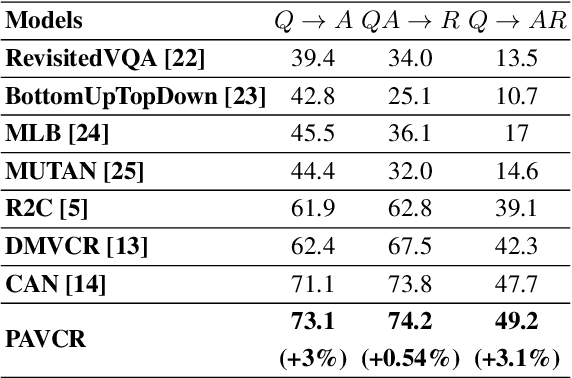
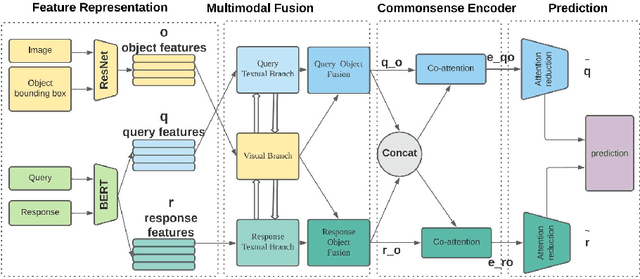

Given a question-image input, the Visual Commonsense Reasoning (VCR) model can predict an answer with the corresponding rationale, which requires inference ability from the real world. The VCR task, which calls for exploiting the multi-source information as well as learning different levels of understanding and extensive commonsense knowledge, is a cognition-level scene understanding task. The VCR task has aroused researchers' interest due to its wide range of applications, including visual question answering, automated vehicle systems, and clinical decision support. Previous approaches to solving the VCR task generally rely on pre-training or exploiting memory with long dependency relationship encoded models. However, these approaches suffer from a lack of generalizability and losing information in long sequences. In this paper, we propose a parallel attention-based cognitive VCR network PAVCR, which fuses visual-textual information efficiently and encodes semantic information in parallel to enable the model to capture rich information for cognition-level inference. Extensive experiments show that the proposed model yields significant improvements over existing methods on the benchmark VCR dataset. Moreover, the proposed model provides intuitive interpretation into visual commonsense reasoning.
TOD-CNN: An Effective Convolutional Neural Network for Tiny Object Detection in Sperm Videos
Apr 18, 2022

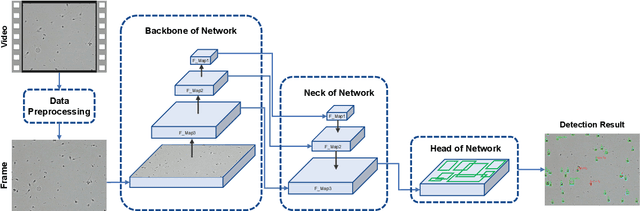
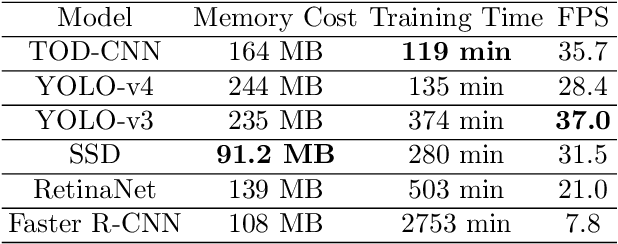
The detection of tiny objects in microscopic videos is a problematic point, especially in large-scale experiments. For tiny objects (such as sperms) in microscopic videos, current detection methods face challenges in fuzzy, irregular, and precise positioning of objects. In contrast, we present a convolutional neural network for tiny object detection (TOD-CNN) with an underlying data set of high-quality sperm microscopic videos (111 videos, $>$ 278,000 annotated objects), and a graphical user interface (GUI) is designed to employ and test the proposed model effectively. TOD-CNN is highly accurate, achieving $85.60\%$ AP$_{50}$ in the task of real-time sperm detection in microscopic videos. To demonstrate the importance of sperm detection technology in sperm quality analysis, we carry out relevant sperm quality evaluation metrics and compare them with the diagnosis results from medical doctors.
Do As I Can, Not As I Say: Grounding Language in Robotic Affordances
Apr 04, 2022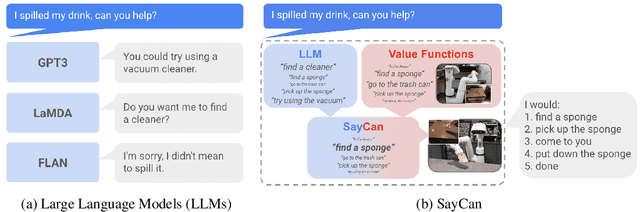
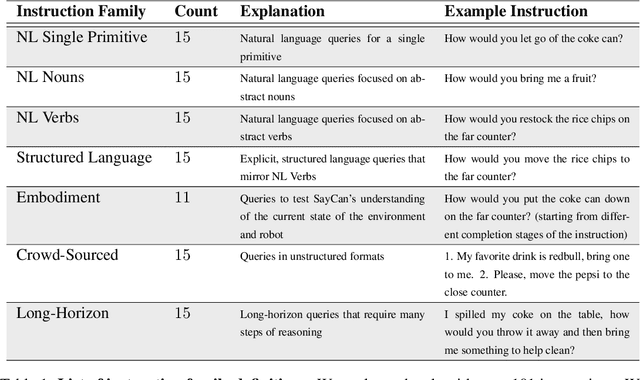
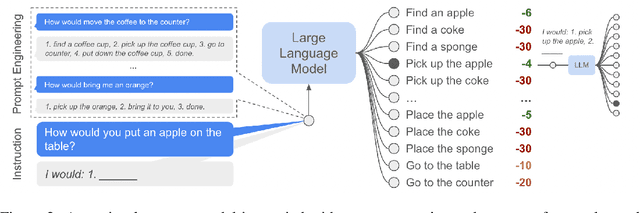
Large language models can encode a wealth of semantic knowledge about the world. Such knowledge could be extremely useful to robots aiming to act upon high-level, temporally extended instructions expressed in natural language. However, a significant weakness of language models is that they lack real-world experience, which makes it difficult to leverage them for decision making within a given embodiment. For example, asking a language model to describe how to clean a spill might result in a reasonable narrative, but it may not be applicable to a particular agent, such as a robot, that needs to perform this task in a particular environment. We propose to provide real-world grounding by means of pretrained skills, which are used to constrain the model to propose natural language actions that are both feasible and contextually appropriate. The robot can act as the language model's "hands and eyes," while the language model supplies high-level semantic knowledge about the task. We show how low-level skills can be combined with large language models so that the language model provides high-level knowledge about the procedures for performing complex and temporally-extended instructions, while value functions associated with these skills provide the grounding necessary to connect this knowledge to a particular physical environment. We evaluate our method on a number of real-world robotic tasks, where we show the need for real-world grounding and that this approach is capable of completing long-horizon, abstract, natural language instructions on a mobile manipulator. The project's website and the video can be found at https://say-can.github.io/