 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-grained Hierarchical Crop Type Classification from Integrated Hyperspectral EnMAP Data and Multispectral Sentinel-2 Time Series: A Large-scale Dataset and Dual-stream Transformer Method
Jun 09, 2025Fine-grained crop type classification serves as the fundamental basis for large-scale crop mapping and plays a vital role in ensuring food security. It requires simultaneous capture of both phenological dynamics (obtained from multi-temporal satellite data like Sentinel-2) and subtle spectral variations (demanding nanometer-scale spectral resolution from hyperspectral imagery). Research combining these two modalities remains scarce currently due to challenges in hyperspectral data acquisition and crop types annotation costs. To address these issues, we construct a hierarchical hyperspectral crop dataset (H2Crop) by integrating 30m-resolution EnMAP hyperspectral data with Sentinel-2 time series. With over one million annotated field parcels organized in a four-tier crop taxonomy, H2Crop establishes a vital benchmark for fine-grained agricultural crop classification and hyperspectral image processing. We propose a dual-stream Transformer architecture that synergistically processes these modalities. It coordinates two specialized pathways: a spectral-spatial Transformer extracts fine-grained signatures from hyperspectral EnMAP data, while a temporal Swin Transformer extracts crop growth patterns from Sentinel-2 time series. The designed hierarchical classification head with hierarchical fusion then simultaneously delivers multi-level crop type classification across all taxonomic tiers. Experiments demonstrate that adding hyperspectral EnMAP data to Sentinel-2 time series yields a 4.2% average F1-scores improvement (peaking at 6.3%). Extensive comparisons also confirm our method's higher accuracy over existing deep learning approaches for crop type classification and the consistent benefits of hyperspectral data across varying temporal windows and crop change scenarios. Codes and dataset are available at https://github.com/flyakon/H2Crop.
A Novel Large-scale Crop Dataset and Dual-stream Transformer Method for Fine-grained Hierarchical Crop Classification from Integrated Hyperspectral EnMAP Data and Multispectral Sentinel-2 Time Series
Jun 06, 2025Fine-grained crop classification is crucial for precision agriculture and food security monitoring. It requires simultaneous capture of both phenological dynamics (obtained from multi-temporal satellite data like Sentinel-2) and subtle spectral variations (demanding nanometer-scale spectral resolution from hyperspectral imagery). Research combining these two modalities remains scarce currently due to challenges in hyperspectral data acquisition and crop types annotation costs. To address these issues, we construct a hierarchical hyperspectral crop dataset (H2Crop) by integrating 30m-resolution EnMAP hyperspectral data with Sentinel-2 time series. With over one million annotated field parcels organized in a four-tier crop taxonomy, H2Crop establishes a vital benchmark for fine-grained agricultural crop classification and hyperspectral image processing. We propose a dual-stream Transformer architecture that synergistically processes these modalities. It coordinates two specialized pathways: a spectral-spatial Transformer extracts fine-grained signatures from hyperspectral EnMAP data, while a temporal Swin Transformer extracts crop growth patterns from Sentinel-2 time series. The designed hierarchy classification heads with hierarchical fusion then simultaneously delivers multi-level classification across all taxonomic tiers. Experiments demonstrate that adding hyperspectral EnMAP data to Sentinel-2 time series yields a 4.2% average F1-scores improvement (peaking at 6.3%). Extensive comparisons also confirming our method's higher accuracy over existing deep learning approaches for crop type classification and the consistent benefits of hyperspectral data across varying temporal windows and crop change scenarios. Codes and dataset will be available at https://github.com/flyakon/H2Crop and www.glass.hku.hk Keywords: Crop type classification, precision agriculture, remote sensing, deep learning, hyperspectral data, Sentinel-2 time series, fine-grained crops
AgriFM: A Multi-source Temporal Remote Sensing Foundation Model for Crop Mapping
May 28, 2025Accurate crop mapping fundamentally relies on modeling multi-scale spatiotemporal patterns, where spatial scales range from individual field textures to landscape-level context, and temporal scales capture both short-term phenological transitions and full growing-season dynamics. Transformer-based remote sensing foundation models (RSFMs) offer promising potential for crop mapping due to their innate ability for unified spatiotemporal processing. However, current RSFMs remain suboptimal for crop mapping: they either employ fixed spatiotemporal windows that ignore the multi-scale nature of crop systems or completely disregard temporal information by focusing solely on spatial patterns. To bridge these gaps, we present AgriFM, a multi-source remote sensing foundation model specifically designed for agricultural crop mapping. Our approach begins by establishing the necessity of simultaneous hierarchical spatiotemporal feature extraction, leading to the development of a modified Video Swin Transformer architecture where temporal down-sampling is synchronized with spatial scaling operations. This modified backbone enables efficient unified processing of long time-series satellite inputs. AgriFM leverages temporally rich data streams from three satellite sources including MODIS, Landsat-8/9 and Sentinel-2, and is pre-trained on a global representative dataset comprising over 25 million image samples supervised by land cover products. The resulting framework incorporates a versatile decoder architecture that dynamically fuses these learned spatiotemporal representations, supporting diverse downstream tasks. Comprehensive evaluations demonstrate AgriFM's superior performance over conventional deep learning approaches and state-of-the-art general-purpose RSFMs across all downstream tasks. Codes will be available at https://github.com/flyakon/AgriFM.
Online Time-Informed Kinodynamic Motion Planning of Nonlinear Systems
Jul 03, 2024



Sampling-based kinodynamic motion planners (SKMPs) are powerful in finding collision-free trajectories for high-dimensional systems under differential constraints. Time-informed set (TIS) can provide the heuristic search domain to accelerate their convergence to the time-optimal solution. However, existing TIS approximation methods suffer from the curse of dimensionality, computational burden, and limited system applicable scope, e.g., linear and polynomial nonlinear systems. To overcome these problems, we propose a method by leveraging deep learning technology, Koopman operator theory, and random set theory. Specifically, we propose a Deep Invertible Koopman operator with control U model named DIKU to predict states forward and backward over a long horizon by modifying the auxiliary network with an invertible neural network. A sampling-based approach, ASKU, performing reachability analysis for the DIKU is developed to approximate the TIS of nonlinear control systems online. Furthermore, we design an online time-informed SKMP using a direct sampling technique to draw uniform random samples in the TIS. Simulation experiment results demonstrate that our method outperforms other existing works, approximating TIS in near real-time and achieving superior planning performance in several time-optimal kinodynamic motion planning problems.
LLM-Detector: Improving AI-Generated Chinese Text Detection with Open-Source LLM Instruction Tuning
Feb 02, 2024ChatGPT and other general large language models (LLMs) have achieved remarkable success, but they have also raised concerns about the misuse of AI-generated texts. Existing AI-generated text detection models, such as based on BERT and RoBERTa, are prone to in-domain over-fitting, leading to poor out-of-domain (OOD) detection performance. In this paper, we first collected Chinese text responses generated by human experts and 9 types of LLMs, for which to multiple domains questions, and further created a dataset that mixed human-written sentences and sentences polished by LLMs. We then proposed LLM-Detector, a novel method for both document-level and sentence-level text detection through Instruction Tuning of LLMs. Our method leverages the wealth of knowledge LLMs acquire during pre-training, enabling them to detect the text they generate. Instruction tuning aligns the model's responses with the user's expected text detection tasks. Experimental results show that previous methods struggle with sentence-level AI-generated text detection and OOD detection. In contrast, our proposed method not only significantly outperforms baseline methods in both sentence-level and document-level text detection but also demonstrates strong generalization capabilities. Furthermore, since LLM-Detector is trained based on open-source LLMs, it is easy to customize for deployment.
Aurora:Activating Chinese chat capability for Mixtral-8x7B sparse Mixture-of-Experts through Instruction-Tuning
Jan 01, 2024



Existing research has demonstrated that refining large language models (LLMs) through the utilization of machine-generated instruction-following data empowers these models to exhibit impressive zero-shot capabilities for novel tasks, without requiring human-authored instructions. In this paper, we systematically investigate, preprocess, and integrate three Chinese instruction-following datasets with the aim of enhancing the Chinese conversational capabilities of Mixtral-8x7B sparse Mixture-of-Experts model. Through instruction fine-tuning on this carefully processed dataset, we successfully construct the Mixtral-8x7B sparse Mixture-of-Experts model named "Aurora." To assess the performance of Aurora, we utilize three widely recognized benchmark tests: C-Eval, MMLU, and CMMLU. Empirical studies validate the effectiveness of instruction fine-tuning applied to Mixtral-8x7B sparse Mixture-of-Experts model. This work is pioneering in the execution of instruction fine-tuning on a sparse expert-mixed model, marking a significant breakthrough in enhancing the capabilities of this model architecture. Our code, data and model are publicly available at https://github.com/WangRongsheng/Aurora
Discrepancy-based Active Learning for Weakly Supervised Bleeding Segmentation in Wireless Capsule Endoscopy Images
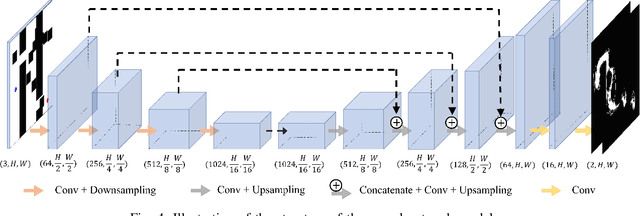
Aug 09, 2023Weakly supervised methods, such as class activation maps (CAM) based, have been applied to achieve bleeding segmentation with low annotation efforts in Wireless Capsule Endoscopy (WCE) images. However, the CAM labels tend to be extremely noisy, and there is an irreparable gap between CAM labels and ground truths for medical images. This paper proposes a new Discrepancy-basEd Active Learning (DEAL) approach to bridge the gap between CAMs and ground truths with a few annotations. Specifically, to liberate labor, we design a novel discrepancy decoder model and a CAMPUS (CAM, Pseudo-label and groUnd-truth Selection) criterion to replace the noisy CAMs with accurate model predictions and a few human labels. The discrepancy decoder model is trained with a unique scheme to generate standard, coarse and fine predictions. And the CAMPUS criterion is proposed to predict the gaps between CAMs and ground truths based on model divergence and CAM divergence. We evaluate our method on the WCE dataset and results show that our method outperforms the state-of-the-art active learning methods and reaches comparable performance to those trained with full annotated datasets with only 10% of the training data labeled.
NR-RRT: Neural Risk-Aware Near-Optimal Path Planning in Uncertain Nonconvex Environments
May 14, 2022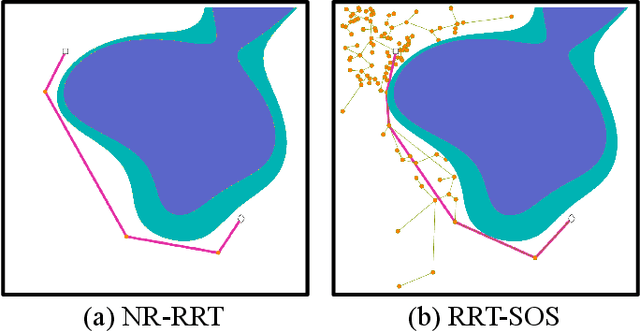
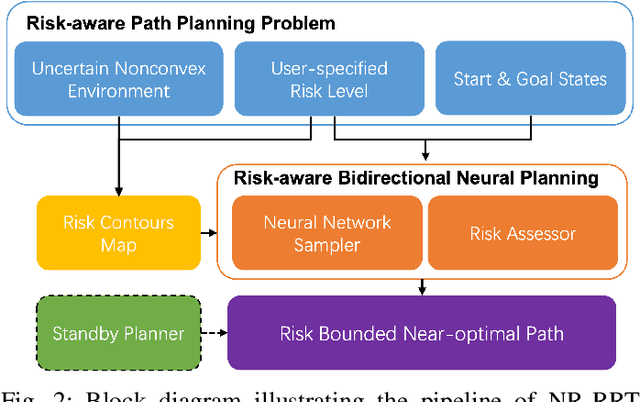
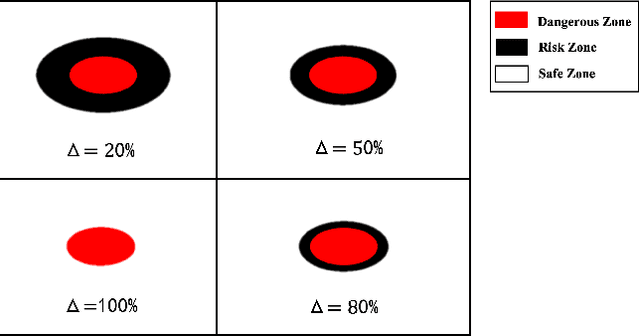
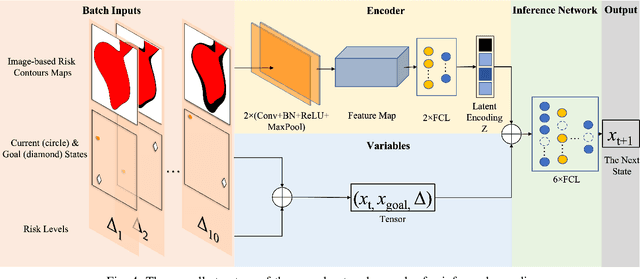
Balancing the trade-off between safety and efficiency is of significant importance for path planning under uncertainty. Many risk-aware path planners have been developed to explicitly limit the probability of collision to an acceptable bound in uncertain environments. However, convex obstacles or Gaussian uncertainties are usually assumed to make the problem tractable in the existing method. These assumptions limit the generalization and application of path planners in real-world implementations. In this article, we propose to apply deep learning methods to the sampling-based planner, developing a novel risk bounded near-optimal path planning algorithm named neural risk-aware RRT (NR-RRT). Specifically, a deterministic risk contours map is maintained by perceiving the probabilistic nonconvex obstacles, and a neural network sampler is proposed to predict the next most-promising safe state. Furthermore, the recursive divide-and-conquer planning and bidirectional search strategies are used to accelerate the convergence to a near-optimal solution with guaranteed bounded risk. Worst-case theoretical guarantees can also be proven owing to a standby safety guaranteed planner utilizing a uniform sampling distribution. Simulation experiments demonstrate that the proposed algorithm outperforms the state-of-the-art remarkably for finding risk bounded low-cost paths in seen and unseen environments with uncertainty and nonconvex constraints.
BiAIT*: Symmetrical Bidirectional Optimal Path Planning with Adaptive Heuristic
May 14, 2022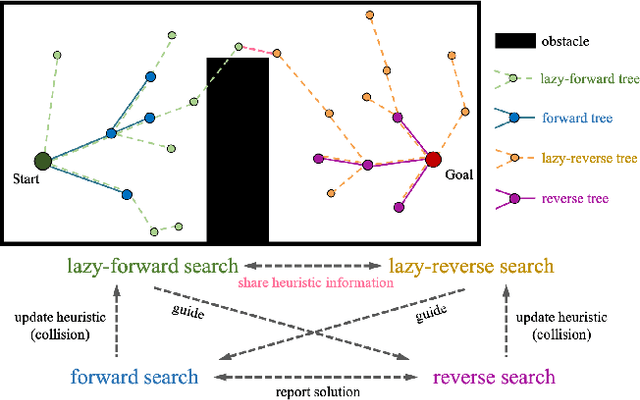
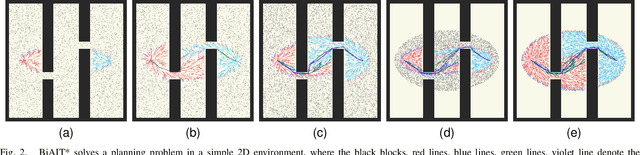
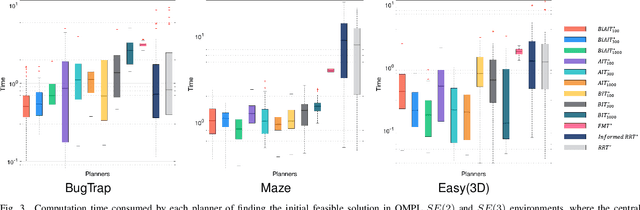

Adaptively Informed Trees (AIT*) develops the problem-specific heuristic under the current topological abstraction of the state space with a lazy-reverse tree that is constructed without collision checking. AIT* can avoid unnecessary searching with the heuristic, which significantly improves the algorithm performance, especially when collision checking is expensive. However, the heuristic estimation in AIT* consumes lots of computation resources, and its asymmetric bidirectional searching strategy cannot fully exploit the potential of the bidirectional method. In this article, we extend AIT* from the asymmetric bidirectional search to the symmetrical bidirectional search, namely BiAIT*. Both the heuristic and space searching in BiAIT* are calculated bidirectionally. The path planner can find the initial solution faster with our proposed method. In addition, when a collision happens, BiAIT* can update the heuristic with less computation. Simulations are carried out to evaluate the performance of the proposed algorithm, and the results show that our algorithm can find the solution faster than the state of the arts. We also analyze the reason for different performances between BiAIT* and AIT*. Furthermore, we discuss two simple but effective modifications to fully exploit the potential of the adaptively heuristic method.
Enhance Connectivity of Promising Regions for Sampling-based Path Planning
Dec 15, 2021
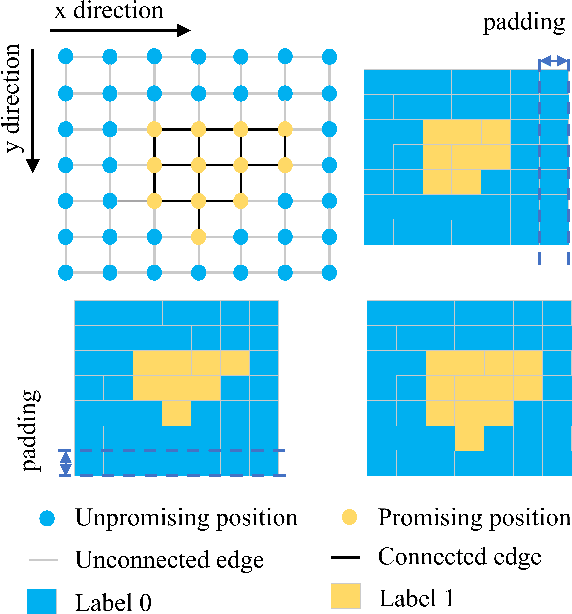
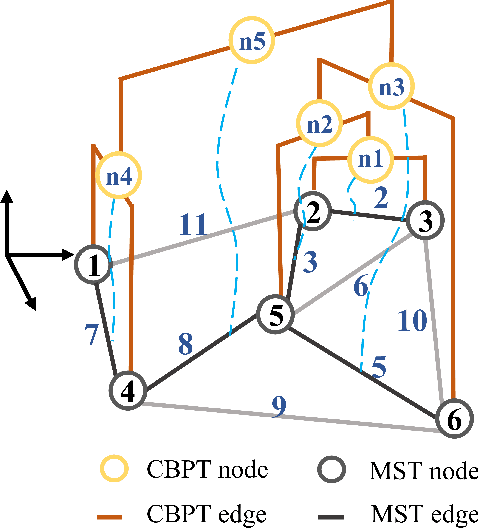
Sampling-based path planning algorithms usually implement uniform sampling methods to search the state space. However, uniform sampling may lead to unnecessary exploration in many scenarios, such as the environment with a few dead ends. Our previous work proposes to use the promising region to guide the sampling process to address the issue. However, the predicted promising regions are often disconnected, which means they cannot connect the start and goal state, resulting in a lack of probabilistic completeness. This work focuses on enhancing the connectivity of predicted promising regions. Our proposed method regresses the connectivity probability of the edges in the x and y directions. In addition, it calculates the weight of the promising edges in loss to guide the neural network to pay more attention to the connectivity of the promising regions. We conduct a series of simulation experiments, and the results show that the connectivity of promising regions improves significantly. Furthermore, we analyze the effect of connectivity on sampling-based path planning algorithms and conclude that connectivity plays an essential role in maintaining algorithm performance.