 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSwarm-Inspired Generation of Collective Behaviors in Graph Dynamical Systems
Jun 23, 2026Collective behavior arises when locally interacting units produce coordinated global organization, from synchronization in dynamical systems to task-relevant information flow on graphs. The central challenge is not only to explain how collective behavior emerges, but to design local interaction rules that can produce desired global organization and generalize across graphs, dynamics and tasks.To address this challenge, we introduce the Swarm-Inspired Emergent Synchronizer (SIES), a graph-dynamical framework that learns generalizable local-interaction laws for controllable collective organization. Each node is an agent-like dynamical unit with a state and task cue, and signed source-target-conditioned attention acts as an adaptive coupling term inside an explicit evolution model. Therefore, SIES combines an explicit dynamical engine with local agent intelligence, similar to biological swarms. For synchronization control, SIES learns a generalizable coupling operator that produces prescribed synchronization patterns for CDSs across untrained network scales, target phase relations, and intrinsic node dynamics without retraining. The learned operator also reaches gait-related modes faster than three oscillator baselines and generalizes synchronization-driven locomotion to simulated multi-legged robots of different scales and a physical hexapod after leg disablement. For graph representation learning, SIES applies the same signed interaction principle to message passing and achieves the highest performance among the compared methods on heterophilous node-classification benchmarks. Together, these results position SIES as a generalizable and learnable graph-dynamical interaction framework with promise for synchronization control, adaptive robot coordination, and heterophilous graph representation learning.
Discriminative Representation Learning for Clinical Prediction
Mar 21, 2026Foundation models in healthcare have largely adopted self supervised pretraining objectives inherited from natural language processing and computer vision, emphasizing reconstruction and large scale representation learning prior to downstream adaptation. We revisit this paradigm in outcome centric clinical prediction settings and argue that, when high quality supervision is available, direct outcome alignment may provide a stronger inductive bias than generative pretraining. We propose a supervised deep learning framework that explicitly shapes representation geometry by maximizing inter class separation relative to within class variance, thereby concentrating model capacity along clinically meaningful axes. Across multiple longitudinal electronic health record tasks, including mortality and readmission prediction, our approach consistently outperforms masked, autoregressive, and contrastive pretraining baselines under matched model capacity. The proposed method improves discrimination, calibration, and sample efficiency, while simplifying the training pipeline to a single stage optimization. These findings suggest that in low entropy, outcome driven healthcare domains, supervision can act as the statistically optimal driver of representation learning, challenging the assumption that large scale self supervised pretraining is a prerequisite for strong clinical performance.
HierarchicalKV: A GPU Hash Table with Cache Semantics for Continuous Online Embedding Storage
Mar 17, 2026Traditional GPU hash tables preserve every inserted key -- a dictionary assumption that wastes scarce High Bandwidth Memory (HBM) when embedding tables routinely exceed single-GPU capacity. We challenge this assumption with cache semantics, where policy-driven eviction is a first-class operation. We introduce HierarchicalKV (HKV), the first general-purpose GPU hash table library whose normal full-capacity operating contract is cache-semantic: each full-bucket upsert (update-or-insert) is resolved in place by eviction or admission rejection rather than by rehashing or capacity-induced failure. HKV co-designs four core mechanisms -- cache-line-aligned buckets, in-line score-driven upsert, score-based dynamic dual-bucket selection, and triple-group concurrency -- and uses tiered key-value separation as a scaling enabler beyond HBM. On an NVIDIA H100 NVL GPU, HKV achieves up to 3.9 billion key-value pairs per second (B-KV/s) find throughput, stable across load factors 0.50-1.00 (<5% variation), and delivers 1.4x higher find throughput than WarpCore (the strongest dictionary-semantic GPU baseline at lambda=0.50) and up to 2.6-9.4x over indirection-based GPU baselines. Since its open-source release in October 2022, HKV has been integrated into multiple open-source recommendation frameworks.
A Hierarchical Quantized Tokenization Framework for Task-Adaptive Graph Representation Learning
Oct 14, 2025Recent progress in language and vision foundation models demonstrates the importance of discrete token interfaces that transform complex inputs into compact sequences for large-scale modeling. Extending this paradigm to graphs requires a tokenization scheme that handles non-Euclidean structures and multi-scale dependencies efficiently. Existing approaches to graph tokenization, linearized, continuous, and quantized, remain limited in adaptability and efficiency. In particular, most current quantization-based tokenizers organize hierarchical information in fixed or task-agnostic ways, which may either over-represent or under-utilize structural cues, and lack the ability to dynamically reweight contributions from different levels without retraining the encoder. This work presents a hierarchical quantization framework that introduces a self-weighted mechanism for task-adaptive aggregation across multiple scales. The proposed method maintains a frozen encoder while modulating information flow through a lightweight gating process, enabling parameter-efficient adaptation to diverse downstream tasks. Experiments on benchmark datasets for node classification and link prediction demonstrate consistent improvements over strong baselines under comparable computational budgets.
Uncertainty-Aware Semantic Decoding for LLM-Based Sequential Recommendation
Aug 10, 2025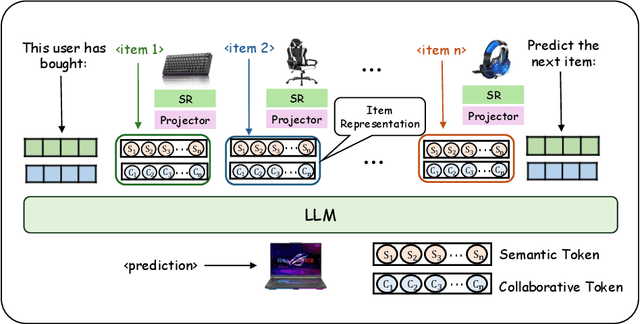
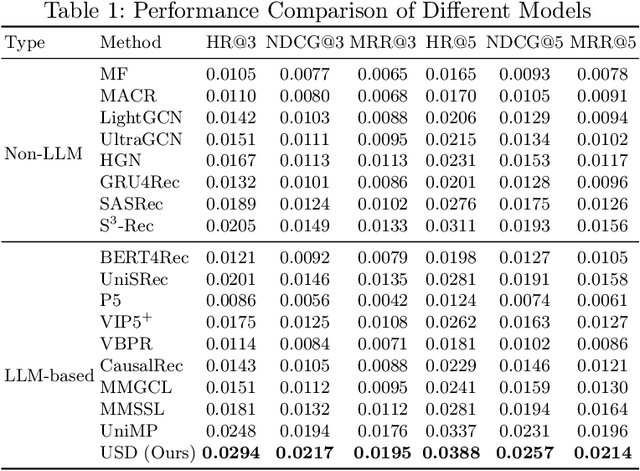
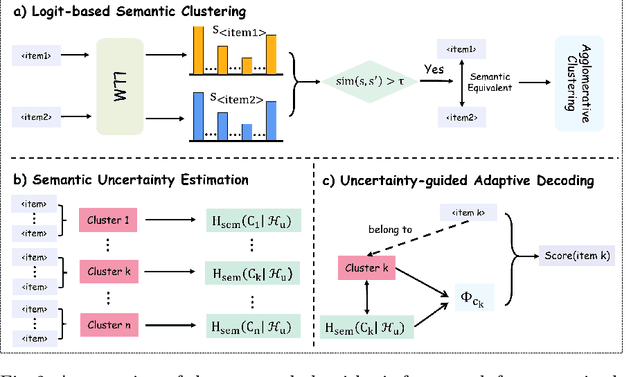

Large language models have been widely applied to sequential recommendation tasks, yet during inference, they continue to rely on decoding strategies developed for natural language processing. This creates a mismatch between text-generation objectives and recommendation next item selection objectives. This paper addresses this limitation by proposing an Uncertainty-aware Semantic Decoding (USD) framework that combines logit-based clustering with adaptive scoring to improve next-item predictions. Our approach clusters items with similar logit vectors into semantic equivalence groups, then redistributes probability mass within these clusters and computes entropy across them to control item scoring and sampling temperature during recommendation inference. Experiments on Amazon Product datasets (six domains) gains of 18.5\% in HR@3, 11.9\% in NDCG@3, and 10.8\% in MRR@3 compared to state-of-the-art baselines. Hyperparameter analysis confirms the optimal parameters among various settings, and experiments on H\&M, and Netflix datasets indicate that the framework can adapt to differing recommendation domains. The experimental results confirm that integrating semantic clustering and uncertainty assessment yields more reliable and accurate recommendations.
Beyond Terabit/s Integrated Neuromorphic Photonic Processor for DSP-Free Optical Interconnects
Apr 21, 2025The rapid expansion of generative AI drives unprecedented demands for high-performance computing. Training large-scale AI models now requires vast interconnected GPU clusters across multiple data centers. Multi-scale AI training and inference demand uniform, ultra-low latency, and energy-efficient links to enable massive GPUs to function as a single cohesive unit. However, traditional electrical and optical interconnects, relying on conventional digital signal processors (DSPs) for signal distortion compensation, increasingly fail to meet these stringent requirements. To overcome these limitations, we present an integrated neuromorphic optical signal processor (OSP) that leverages deep reservoir computing and achieves DSP-free, all-optical, real-time processing. Experimentally, our OSP achieves a 100 Gbaud PAM4 per lane, 1.6 Tbit/s data center interconnect over a 5 km optical fiber in the C-band (equivalent to over 80 km in the O-band), far exceeding the reach of state-of-the-art DSP solutions, which are fundamentally constrained by chromatic dispersion in IMDD systems. Simultaneously, it reduces processing latency by four orders of magnitude and energy consumption by three orders of magnitude. Unlike DSPs, which introduce increased latency at high data rates, our OSP maintains consistent, ultra-low latency regardless of data rate scaling, making it ideal for future optical interconnects. Moreover, the OSP retains full optical field information for better impairment compensation and adapts to various modulation formats, data rates, and wavelengths. Fabricated using a mature silicon photonic process, the OSP can be monolithically integrated with silicon photonic transceivers, enhancing the compactness and reliability of all-optical interconnects. This research provides a highly scalable, energy-efficient, and high-speed solution, paving the way for next-generation AI infrastructure.
Transformer-based Wireless Symbol Detection Over Fading Channels
Mar 20, 2025Pre-trained Transformers, through in-context learning (ICL), have demonstrated exceptional capabilities to adapt to new tasks using example prompts without model update. Transformer-based wireless receivers, where prompts consist of the pilot data in the form of transmitted and received signal pairs, have shown high detection accuracy when pilot data are abundant. However, pilot information is often costly and limited in practice. In this work, we propose the DEcision Feedback INcontExt Detection (DEFINED) solution as a new wireless receiver design, which bypasses channel estimation and directly performs symbol detection using the (sometimes extremely) limited pilot data. The key innovation in DEFINED is the proposed decision feedback mechanism in ICL, where we sequentially incorporate the detected symbols into the prompts as pseudo-labels to improve the detection for subsequent symbols. Furthermore, we proposed another detection method where we combine ICL with Semi-Supervised Learning (SSL) to extract information from both labeled and unlabeled data during inference, thus avoiding the errors propagated during the decision feedback process of the original DEFINED. Extensive experiments across a broad range of wireless communication settings demonstrate that a small Transformer trained with DEFINED or IC-SSL achieves significant performance improvements over conventional methods, in some cases only needing a single pilot pair to achieve similar performance of the latter with more than 4 pilot pairs.
Exploiting Epistemic Uncertainty in Cold-Start Recommendation Systems
Feb 22, 2025


The cold-start problem remains a significant challenge in recommendation systems based on generative models. Current methods primarily focus on enriching embeddings or inputs by gathering more data, often overlooking the effectiveness of how existing training knowledge is utilized. This inefficiency can lead to missed opportunities for improving cold-start recommendations. To address this, we propose the use of epistemic uncertainty, which reflects a lack of certainty about the optimal model, as a tool to measure and enhance the efficiency with which a recommendation system leverages available knowledge. By considering epistemic uncertainty as a reducible component of overall uncertainty, we introduce a new approach to refine model performance. The effectiveness of this approach is validated through extensive offline experiments on publicly available datasets, demonstrating its superior performance and robustness in tackling the cold-start problem.
Perfecting Imperfect Physical Neural Networks with Transferable Robustness using Sharpness-Aware Training
Nov 19, 2024



AI models are essential in science and engineering, but recent advances are pushing the limits of traditional digital hardware. To address these limitations, physical neural networks (PNNs), which use physical substrates for computation, have gained increasing attention. However, developing effective training methods for PNNs remains a significant challenge. Current approaches, regardless of offline and online training, suffer from significant accuracy loss. Offline training is hindered by imprecise modeling, while online training yields device-specific models that can't be transferred to other devices due to manufacturing variances. Both methods face challenges from perturbations after deployment, such as thermal drift or alignment errors, which make trained models invalid and require retraining. Here, we address the challenges with both offline and online training through a novel technique called Sharpness-Aware Training (SAT), where we innovatively leverage the geometry of the loss landscape to tackle the problems in training physical systems. SAT enables accurate training using efficient backpropagation algorithms, even with imprecise models. PNNs trained by SAT offline even outperform those trained online, despite modeling and fabrication errors. SAT also overcomes online training limitations by enabling reliable transfer of models between devices. Finally, SAT is highly resilient to perturbations after deployment, allowing PNNs to continuously operate accurately under perturbations without retraining. We demonstrate SAT across three types of PNNs, showing it is universally applicable, regardless of whether the models are explicitly known. This work offers a transformative, efficient approach to training PNNs, addressing critical challenges in analog computing and enabling real-world deployment.
Decision Feedback In-Context Symbol Detection over Block-Fading Channels
Nov 12, 2024


Pre-trained Transformers, through in-context learning (ICL), have demonstrated exceptional capabilities to adapt to new tasks using example prompts \textit{without model update}. Transformer-based wireless receivers, where prompts consist of the pilot data in the form of transmitted and received signal pairs, have shown high estimation accuracy when pilot data are abundant. However, pilot information is often costly and limited in practice. In this work, we propose the \underline{DE}cision \underline{F}eedback \underline{IN}-Cont\underline{E}xt \underline{D}etection (DEFINED) solution as a new wireless receiver design, which bypasses channel estimation and directly performs symbol detection using the (sometimes extremely) limited pilot data. The key innovation in DEFINED is the proposed decision feedback mechanism in ICL, where we sequentially incorporate the detected symbols into the prompts to improve the detections for subsequent symbols. Extensive experiments across a broad range of wireless communication settings demonstrate that DEFINED achieves significant performance improvements, in some cases only needing a single pilot pair.