 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast and Continual Knowledge Graph Embedding via Incremental LoRA
Jul 08, 2024



Continual Knowledge Graph Embedding (CKGE) aims to efficiently learn new knowledge and simultaneously preserve old knowledge. Dominant approaches primarily focus on alleviating catastrophic forgetting of old knowledge but neglect efficient learning for the emergence of new knowledge. However, in real-world scenarios, knowledge graphs (KGs) are continuously growing, which brings a significant challenge to fine-tuning KGE models efficiently. To address this issue, we propose a fast CKGE framework (\model), incorporating an incremental low-rank adapter (\mec) mechanism to efficiently acquire new knowledge while preserving old knowledge. Specifically, to mitigate catastrophic forgetting, \model\ isolates and allocates new knowledge to specific layers based on the fine-grained influence between old and new KGs. Subsequently, to accelerate fine-tuning, \model\ devises an efficient \mec\ mechanism, which embeds the specific layers into incremental low-rank adapters with fewer training parameters. Moreover, \mec\ introduces adaptive rank allocation, which makes the LoRA aware of the importance of entities and adjusts its rank scale adaptively. We conduct experiments on four public datasets and two new datasets with a larger initial scale. Experimental results demonstrate that \model\ can reduce training time by 34\%-49\% while still achieving competitive link prediction performance against state-of-the-art models on four public datasets (average MRR score of 21.0\% vs. 21.1\%).Meanwhile, on two newly constructed datasets, \model\ saves 51\%-68\% training time and improves link prediction performance by 1.5\%.
Robot Shape and Location Retention in Video Generation Using Diffusion Models
Jul 03, 2024



Diffusion models have marked a significant milestone in the enhancement of image and video generation technologies. However, generating videos that precisely retain the shape and location of moving objects such as robots remains a challenge. This paper presents diffusion models specifically tailored to generate videos that accurately maintain the shape and location of mobile robots. This development offers substantial benefits to those working on detecting dangerous interactions between humans and robots by facilitating the creation of training data for collision detection models, circumventing the need for collecting data from the real world, which often involves legal and ethical issues. Our models incorporate techniques such as embedding accessible robot pose information and applying semantic mask regulation within the ConvNext backbone network. These techniques are designed to refine intermediate outputs, therefore improving the retention performance of shape and location. Through extensive experimentation, our models have demonstrated notable improvements in maintaining the shape and location of different robots, as well as enhancing overall video generation quality, compared to the benchmark diffusion model. Codes will be opensourced at \href{https://github.com/PengPaulWang/diffusion-robots}{Github}.
BeNeRF: Neural Radiance Fields from a Single Blurry Image and Event Stream
Jul 03, 2024Neural implicit representation of visual scenes has attracted a lot of attention in recent research of computer vision and graphics. Most prior methods focus on how to reconstruct 3D scene representation from a set of images. In this work, we demonstrate the possibility to recover the neural radiance fields (NeRF) from a single blurry image and its corresponding event stream. We model the camera motion with a cubic B-Spline in SE(3) space. Both the blurry image and the brightness change within a time interval, can then be synthesized from the 3D scene representation given the 6-DoF poses interpolated from the cubic B-Spline. Our method can jointly learn both the implicit neural scene representation and recover the camera motion by minimizing the differences between the synthesized data and the real measurements without pre-computed camera poses from COLMAP. We evaluate the proposed method with both synthetic and real datasets. The experimental results demonstrate that we are able to render view-consistent latent sharp images from the learned NeRF and bring a blurry image alive in high quality. Code and data are available at https://github.com/WU-CVGL/BeNeRF.
CEB: Compositional Evaluation Benchmark for Fairness in Large Language Models
Jul 02, 2024As Large Language Models (LLMs) are increasingly deployed to handle various natural language processing (NLP) tasks, concerns regarding the potential negative societal impacts of LLM-generated content have also arisen. To evaluate the biases exhibited by LLMs, researchers have recently proposed a variety of datasets. However, existing bias evaluation efforts often focus on only a particular type of bias and employ inconsistent evaluation metrics, leading to difficulties in comparison across different datasets and LLMs. To address these limitations, we collect a variety of datasets designed for the bias evaluation of LLMs, and further propose CEB, a Compositional Evaluation Benchmark that covers different types of bias across different social groups and tasks. The curation of CEB is based on our newly proposed compositional taxonomy, which characterizes each dataset from three dimensions: bias types, social groups, and tasks. By combining the three dimensions, we develop a comprehensive evaluation strategy for the bias in LLMs. Our experiments demonstrate that the levels of bias vary across these dimensions, thereby providing guidance for the development of specific bias mitigation methods.
LLM Granularity for On-the-Fly Robot Control
Jun 20, 2024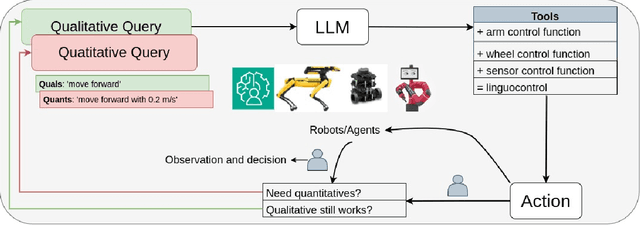
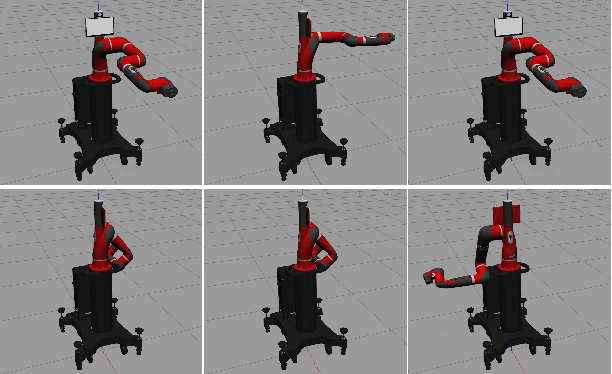

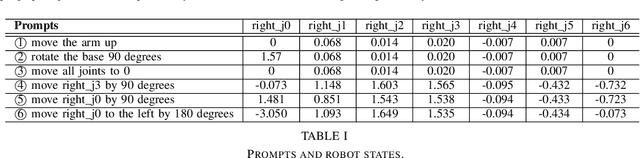
Assistive robots have attracted significant attention due to their potential to enhance the quality of life for vulnerable individuals like the elderly. The convergence of computer vision, large language models, and robotics has introduced the `visuolinguomotor' mode for assistive robots, where visuals and linguistics are incorporated into assistive robots to enable proactive and interactive assistance. This raises the question: \textit{In circumstances where visuals become unreliable or unavailable, can we rely solely on language to control robots, i.e., the viability of the `linguomotor` mode for assistive robots?} This work takes the initial steps to answer this question by: 1) evaluating the responses of assistive robots to language prompts of varying granularities; and 2) exploring the necessity and feasibility of controlling the robot on-the-fly. We have designed and conducted experiments on a Sawyer cobot to support our arguments. A Turtlebot robot case is designed to demonstrate the adaptation of the solution to scenarios where assistive robots need to maneuver to assist. Codes will be released on GitHub soon to benefit the community.
Enhancing Visible-Infrared Person Re-identification with Modality- and Instance-aware Visual Prompt Learning
Jun 18, 2024



The Visible-Infrared Person Re-identification (VI ReID) aims to match visible and infrared images of the same pedestrians across non-overlapped camera views. These two input modalities contain both invariant information, such as shape, and modality-specific details, such as color. An ideal model should utilize valuable information from both modalities during training for enhanced representational capability. However, the gap caused by modality-specific information poses substantial challenges for the VI ReID model to handle distinct modality inputs simultaneously. To address this, we introduce the Modality-aware and Instance-aware Visual Prompts (MIP) network in our work, designed to effectively utilize both invariant and specific information for identification. Specifically, our MIP model is built on the transformer architecture. In this model, we have designed a series of modality-specific prompts, which could enable our model to adapt to and make use of the specific information inherent in different modality inputs, thereby reducing the interference caused by the modality gap and achieving better identification. Besides, we also employ each pedestrian feature to construct a group of instance-specific prompts. These customized prompts are responsible for guiding our model to adapt to each pedestrian instance dynamically, thereby capturing identity-level discriminative clues for identification. Through extensive experiments on SYSU-MM01 and RegDB datasets, the effectiveness of both our designed modules is evaluated. Additionally, our proposed MIP performs better than most state-of-the-art methods.
* Accepyed by ACM International Conference on Multimedia Retrieval (ICMR'24)
Autoregressive Pretraining with Mamba in Vision
Jun 11, 2024



The vision community has started to build with the recently developed state space model, Mamba, as the new backbone for a range of tasks. This paper shows that Mamba's visual capability can be significantly enhanced through autoregressive pretraining, a direction not previously explored. Efficiency-wise, the autoregressive nature can well capitalize on the Mamba's unidirectional recurrent structure, enabling faster overall training speed compared to other training strategies like mask modeling. Performance-wise, autoregressive pretraining equips the Mamba architecture with markedly higher accuracy over its supervised-trained counterparts and, more importantly, successfully unlocks its scaling potential to large and even huge model sizes. For example, with autoregressive pretraining, a base-size Mamba attains 83.2\% ImageNet accuracy, outperforming its supervised counterpart by 2.0\%; our huge-size Mamba, the largest Vision Mamba to date, attains 85.0\% ImageNet accuracy (85.5\% when finetuned with $384\times384$ inputs), notably surpassing all other Mamba variants in vision. The code is available at \url{https://github.com/OliverRensu/ARM}.
Visual Prompt Tuning in Null Space for Continual Learning
Jun 11, 2024



Existing prompt-tuning methods have demonstrated impressive performances in continual learning (CL), by selecting and updating relevant prompts in the vision-transformer models. On the contrary, this paper aims to learn each task by tuning the prompts in the direction orthogonal to the subspace spanned by previous tasks' features, so as to ensure no interference on tasks that have been learned to overcome catastrophic forgetting in CL. However, different from the orthogonal projection in the traditional CNN architecture, the prompt gradient orthogonal projection in the ViT architecture shows completely different and greater challenges, i.e., 1) the high-order and non-linear self-attention operation; 2) the drift of prompt distribution brought by the LayerNorm in the transformer block. Theoretically, we have finally deduced two consistency conditions to achieve the prompt gradient orthogonal projection, which provide a theoretical guarantee of eliminating interference on previously learned knowledge via the self-attention mechanism in visual prompt tuning. In practice, an effective null-space-based approximation solution has been proposed to implement the prompt gradient orthogonal projection. Extensive experimental results demonstrate the effectiveness of anti-forgetting on four class-incremental benchmarks with diverse pre-trained baseline models, and our approach achieves superior performances to state-of-the-art methods. Our code is available at https://github.com/zugexiaodui/VPTinNSforCL.
Symmetric Matrix Completion with ReLU Sampling
Jun 09, 2024We study the problem of symmetric positive semi-definite low-rank matrix completion (MC) with deterministic entry-dependent sampling. In particular, we consider rectified linear unit (ReLU) sampling, where only positive entries are observed, as well as a generalization to threshold-based sampling. We first empirically demonstrate that the landscape of this MC problem is not globally benign: Gradient descent (GD) with random initialization will generally converge to stationary points that are not globally optimal. Nevertheless, we prove that when the matrix factor with a small rank satisfies mild assumptions, the nonconvex objective function is geodesically strongly convex on the quotient manifold in a neighborhood of a planted low-rank matrix. Moreover, we show that our assumptions are satisfied by a matrix factor with i.i.d. Gaussian entries. Finally, we develop a tailor-designed initialization for GD to solve our studied formulation, which empirically always achieves convergence to the global minima. We also conduct extensive experiments and compare MC methods, investigating convergence and completion performance with respect to initialization, noise level, dimension, and rank.
Compressible Dynamics in Deep Overparameterized Low-Rank Learning & Adaptation
Jun 06, 2024While overparameterization in machine learning models offers great benefits in terms of optimization and generalization, it also leads to increased computational requirements as model sizes grow. In this work, we show that by leveraging the inherent low-dimensional structures of data and compressible dynamics within the model parameters, we can reap the benefits of overparameterization without the computational burdens. In practice, we demonstrate the effectiveness of this approach for deep low-rank matrix completion as well as fine-tuning language models. Our approach is grounded in theoretical findings for deep overparameterized low-rank matrix recovery, where we show that the learning dynamics of each weight matrix are confined to an invariant low-dimensional subspace. Consequently, we can construct and train compact, highly compressed factorizations possessing the same benefits as their overparameterized counterparts. In the context of deep matrix completion, our technique substantially improves training efficiency while retaining the advantages of overparameterization. For language model fine-tuning, we propose a method called "Deep LoRA", which improves the existing low-rank adaptation (LoRA) technique, leading to reduced overfitting and a simplified hyperparameter setup, while maintaining comparable efficiency. We validate the effectiveness of Deep LoRA on natural language tasks, particularly when fine-tuning with limited data.