 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUGOD: Uncertainty-Guided Differentiable Opacity and Soft Dropout for Enhanced Sparse-View 3DGS
Aug 07, 20253D Gaussian Splatting (3DGS) has become a competitive approach for novel view synthesis (NVS) due to its advanced rendering efficiency through 3D Gaussian projection and blending. However, Gaussians are treated equally weighted for rendering in most 3DGS methods, making them prone to overfitting, which is particularly the case in sparse-view scenarios. To address this, we investigate how adaptive weighting of Gaussians affects rendering quality, which is characterised by learned uncertainties proposed. This learned uncertainty serves two key purposes: first, it guides the differentiable update of Gaussian opacity while preserving the 3DGS pipeline integrity; second, the uncertainty undergoes soft differentiable dropout regularisation, which strategically transforms the original uncertainty into continuous drop probabilities that govern the final Gaussian projection and blending process for rendering. Extensive experimental results over widely adopted datasets demonstrate that our method outperforms rivals in sparse-view 3D synthesis, achieving higher quality reconstruction with fewer Gaussians in most datasets compared to existing sparse-view approaches, e.g., compared to DropGaussian, our method achieves 3.27\% PSNR improvements on the MipNeRF 360 dataset.
Learning Personalised Human Internal Cognition from External Expressive Behaviours for Real Personality Recognition
Jul 31, 2025



Automatic real personality recognition (RPR) aims to evaluate human real personality traits from their expressive behaviours. However, most existing solutions generally act as external observers to infer observers' personality impressions based on target individuals' expressive behaviours, which significantly deviate from their real personalities and consistently lead to inferior recognition performance. Inspired by the association between real personality and human internal cognition underlying the generation of expressive behaviours, we propose a novel RPR approach that efficiently simulates personalised internal cognition from easy-accessible external short audio-visual behaviours expressed by the target individual. The simulated personalised cognition, represented as a set of network weights that enforce the personalised network to reproduce the individual-specific facial reactions, is further encoded as a novel graph containing two-dimensional node and edge feature matrices, with a novel 2D Graph Neural Network (2D-GNN) proposed for inferring real personality traits from it. To simulate real personality-related cognition, an end-to-end strategy is designed to jointly train our cognition simulation, 2D graph construction, and personality recognition modules.
A Spatial Relationship Aware Dataset for Robotics
Jun 14, 2025



Robotic task planning in real-world environments requires not only object recognition but also a nuanced understanding of spatial relationships between objects. We present a spatial-relationship-aware dataset of nearly 1,000 robot-acquired indoor images, annotated with object attributes, positions, and detailed spatial relationships. Captured using a Boston Dynamics Spot robot and labelled with a custom annotation tool, the dataset reflects complex scenarios with similar or identical objects and intricate spatial arrangements. We benchmark six state-of-the-art scene-graph generation models on this dataset, analysing their inference speed and relational accuracy. Our results highlight significant differences in model performance and demonstrate that integrating explicit spatial relationships into foundation models, such as ChatGPT 4o, substantially improves their ability to generate executable, spatially-aware plans for robotics. The dataset and annotation tool are publicly available at https://github.com/PengPaulWang/SpatialAwareRobotDataset, supporting further research in spatial reasoning for robotics.
GP-GS: Gaussian Processes for Enhanced Gaussian Splatting
Feb 05, 2025



3D Gaussian Splatting has emerged as an efficient photorealistic novel view synthesis method. However, its reliance on sparse Structure-from-Motion (SfM) point clouds consistently compromises the scene reconstruction quality. To address these limitations, this paper proposes a novel 3D reconstruction framework Gaussian Processes Gaussian Splatting (GP-GS), where a multi-output Gaussian Process model is developed to achieve adaptive and uncertainty-guided densification of sparse SfM point clouds. Specifically, we propose a dynamic sampling and filtering pipeline that adaptively expands the SfM point clouds by leveraging GP-based predictions to infer new candidate points from the input 2D pixels and depth maps. The pipeline utilizes uncertainty estimates to guide the pruning of high-variance predictions, ensuring geometric consistency and enabling the generation of dense point clouds. The densified point clouds provide high-quality initial 3D Gaussians to enhance reconstruction performance. Extensive experiments conducted on synthetic and real-world datasets across various scales validate the effectiveness and practicality of the proposed framework.
Robot Shape and Location Retention in Video Generation Using Diffusion Models
Jul 03, 2024



Diffusion models have marked a significant milestone in the enhancement of image and video generation technologies. However, generating videos that precisely retain the shape and location of moving objects such as robots remains a challenge. This paper presents diffusion models specifically tailored to generate videos that accurately maintain the shape and location of mobile robots. This development offers substantial benefits to those working on detecting dangerous interactions between humans and robots by facilitating the creation of training data for collision detection models, circumventing the need for collecting data from the real world, which often involves legal and ethical issues. Our models incorporate techniques such as embedding accessible robot pose information and applying semantic mask regulation within the ConvNext backbone network. These techniques are designed to refine intermediate outputs, therefore improving the retention performance of shape and location. Through extensive experimentation, our models have demonstrated notable improvements in maintaining the shape and location of different robots, as well as enhancing overall video generation quality, compared to the benchmark diffusion model. Codes will be opensourced at \href{https://github.com/PengPaulWang/diffusion-robots}{Github}.
LLM Granularity for On-the-Fly Robot Control
Jun 20, 2024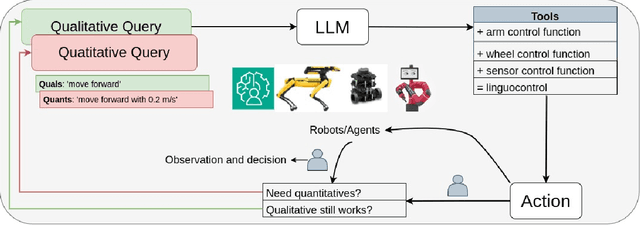
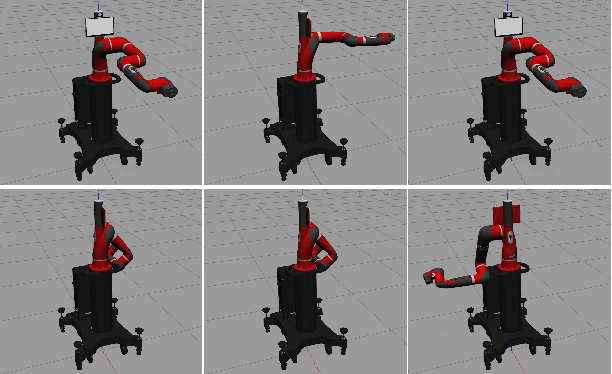

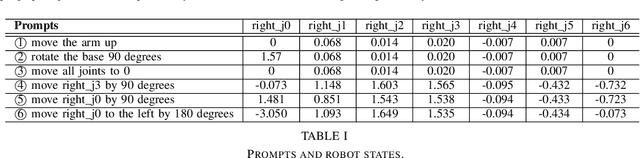
Assistive robots have attracted significant attention due to their potential to enhance the quality of life for vulnerable individuals like the elderly. The convergence of computer vision, large language models, and robotics has introduced the `visuolinguomotor' mode for assistive robots, where visuals and linguistics are incorporated into assistive robots to enable proactive and interactive assistance. This raises the question: \textit{In circumstances where visuals become unreliable or unavailable, can we rely solely on language to control robots, i.e., the viability of the `linguomotor` mode for assistive robots?} This work takes the initial steps to answer this question by: 1) evaluating the responses of assistive robots to language prompts of varying granularities; and 2) exploring the necessity and feasibility of controlling the robot on-the-fly. We have designed and conducted experiments on a Sawyer cobot to support our arguments. A Turtlebot robot case is designed to demonstrate the adaptation of the solution to scenarios where assistive robots need to maneuver to assist. Codes will be released on GitHub soon to benefit the community.
Depth Priors in Removal Neural Radiance Fields
May 01, 2024
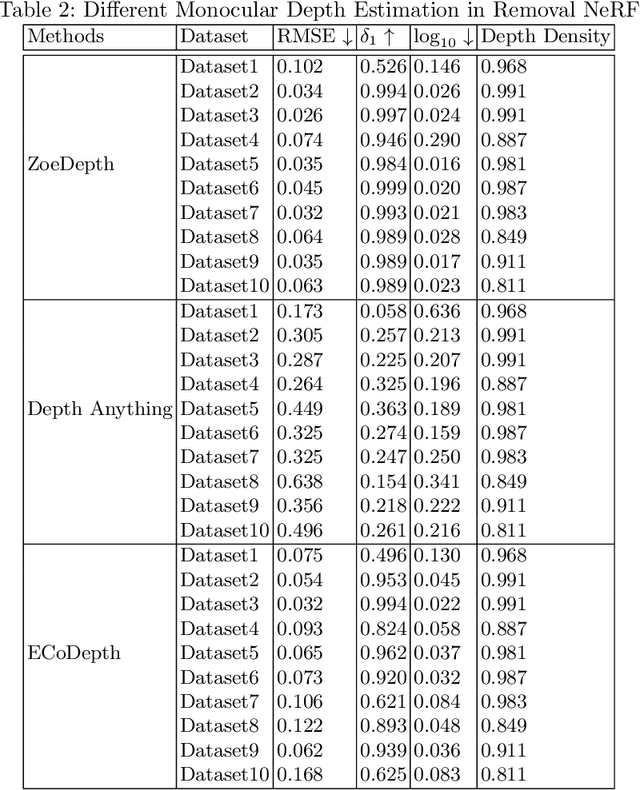


Neural Radiance Fields (NeRF) have shown impressive results in 3D reconstruction and generating novel views. A key challenge within NeRF is the editing of reconstructed scenes, such as object removal, which requires maintaining consistency across multiple views and ensuring high-quality synthesised perspectives. Previous studies have incorporated depth priors, typically from LiDAR or sparse depth measurements provided by COLMAP, to improve the performance of object removal in NeRF. However, these methods are either costly or time-consuming. In this paper, we propose a novel approach that integrates monocular depth estimates with NeRF-based object removal models to significantly reduce time consumption and enhance the robustness and quality of scene generation and object removal. We conducted a thorough evaluation of COLMAP's dense depth reconstruction on the KITTI dataset to verify its accuracy in depth map generation. Our findings suggest that COLMAP can serve as an effective alternative to a ground truth depth map where such information is missing or costly to obtain. Additionally, we integrated various monocular depth estimation methods into the removal NeRF model, i.e., SpinNeRF, to assess their capacity to improve object removal performance. Our experimental results highlight the potential of monocular depth estimation to substantially improve NeRF applications.
Enhancing Visual Document Understanding with Contrastive Learning in Large Visual-Language Models
Feb 29, 2024



Recently, the advent of Large Visual-Language Models (LVLMs) has received increasing attention across various domains, particularly in the field of visual document understanding (VDU). Different from conventional vision-language tasks, VDU is specifically concerned with text-rich scenarios containing abundant document elements. Nevertheless, the importance of fine-grained features remains largely unexplored within the community of LVLMs, leading to suboptimal performance in text-rich scenarios. In this paper, we abbreviate it as the fine-grained feature collapse issue. With the aim of filling this gap, we propose a contrastive learning framework, termed Document Object COntrastive learning (DoCo), specifically tailored for the downstream tasks of VDU. DoCo leverages an auxiliary multimodal encoder to obtain the features of document objects and align them to the visual features generated by the vision encoder of LVLM, which enhances visual representation in text-rich scenarios. It can represent that the contrastive learning between the visual holistic representations and the multimodal fine-grained features of document objects can assist the vision encoder in acquiring more effective visual cues, thereby enhancing the comprehension of text-rich documents in LVLMs. We also demonstrate that the proposed DoCo serves as a plug-and-play pre-training method, which can be employed in the pre-training of various LVLMs without inducing any increase in computational complexity during the inference process. Extensive experimental results on multiple benchmarks of VDU reveal that LVLMs equipped with our proposed DoCo can achieve superior performance and mitigate the gap between VDU and generic vision-language tasks.
The NPU-Elevoc Personalized Speech Enhancement System for ICASSP2023 DNS Challenge
Mar 15, 2023

This paper describes our NPU-Elevoc personalized speech enhancement system (NAPSE) for the 5th Deep Noise Suppression Challenge at ICASSP 2023. Based on the superior two-stage model TEA-PSE 2.0, our system particularly explores better strategy for speaker embedding fusion, optimizes the model training pipeline, and leverages adversarial training and multi-scale loss. According to the results, our system is tied for the 1st place in the headset track (track 1) and ranked 2nd in the speakerphone track (track 2).
TaylorAECNet: A Taylor Style Neural Network for Full-Band Echo Cancellation
Mar 11, 2023



This paper describes aecX team's entry to the ICASSP 2023 acoustic echo cancellation (AEC) challenge. Our system consists of an adaptive filter and a proposed full-band Taylor-style acoustic echo cancellation neural network (TaylorAECNet) as a post-filter. Specifically, we leverage the recent advances in Taylor expansion based decoupling-style interpretable speech enhancement and explore its feasibility in the AEC task. Our TaylorAECNet based approach achieves an overall mean opinion score (MOS) of 4.241, a word accuracy (WAcc) ratio of 0.767, and ranks 5th in the non-personalized track (track 1).