 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePropagating Structural Guidance: Synthesizing Fluorescein Angiography from Fundus Images and Sparse OCT Scans
Jun 15, 2026Fundus fluorescein angiography (FFA) is critical for assessing retinal vascular abnormalities, but its acquisition is invasive and not always feasible. In contrast, color fundus photography (CFP) is non-invasive and widely accessible, which has motivated studies on CFP-to-FFA synthesis. However, prior works rely solely on CFP surface texture, fundamentally limiting the ability to reconstruct functional vascular information and subtle pathological changes. To address this, we propose a novel framework that synthesizes FFA from CFP with structural guidance provided by optical coherence tomography (OCT). We construct a multi-modal retinal imaging dataset with paired CFP, FFA, and OCT from 3,676 patient eyes--the first tri-modally aligned dataset in retinal imaging. To bridge the spatial gap between OCT and fundus modalities, we propose a Spatially Aligned Cross-Modal Fusion (SACMF) module that projects depth-resolved OCT features onto the fundus plane and injects them into the CFP encoder via adaptive layer normalization. Beyond feature fusion, we further introduce Token-wise Cross-Modality Alignment (TCMA), a token-level contrastive learning strategy that explicitly aligns CFP and FFA representations at corresponding spatial positions. Our method achieves superior synthesis performance compared to state-of-the-art methods. Moreover, extensive experiments demonstrate that the FFA images synthesized by our approach bring greater improvements in downstream disease diagnosis performance than existing methods, highlighting the clinical potential of our approach as a non-invasive decision-support tool in routine workflows. The code is available at https://github.com/while-plus/OCT-guide-FFA-Syn.
AdapShot: Adaptive Many-Shot In-Context Learning with Semantic-Aware KV Cache Reuse
May 05, 2026Many-Shot In-Context Learning (ICL) has emerged as a promising paradigm, leveraging extensive examples to unlock the reasoning potential of Large Language Models (LLMs). However, existing methods typically rely on a predetermined, fixed number of shots. This static approach often fails to adapt to the varying difficulty of different queries, leading to either insufficient context or interference from noise. Furthermore, the prohibitive computational and memory costs of long contexts severely limit Many-Shot's feasibility. To address the above limitations, we propose AdapShot, which dynamically optimizes shot counts and leverages KV cache reuse for efficient inference. Specifically, we design a probe-based evaluation mechanism that utilizes output entropy to determine the optimal number of shots. To bypass the redundant prefilling computation during both the probing and inference phases, we incorporate a semantics-aware KV cache reuse strategy. Within this reuse strategy, to address positional encoding incompatibilities, we introduce a decoupling and re-encoding method that enables the flexible reordering of cached key-value pairs. Extensive experiments demonstrate that AdapShot achieves an average performance gain of around 10% and a 4.64x speedup compared to state-of-the-art DBSA.
MedKCO: Medical Vision-Language Pretraining via Knowledge-Driven Cognitive Orchestration
Mar 10, 2026Medical vision-language pretraining (VLP) models have recently been investigated for their generalization to diverse downstream tasks. However, current medical VLP methods typically force the model to learn simple and complex concepts simultaneously. This anti-cognitive process leads to suboptimal feature representations, especially under distribution shift. To address this limitation, we propose a Knowledge-driven Cognitive Orchestration for Medical VLP (MedKCO) that involves both the ordering of the pretraining data and the learning objective of vision-language contrast. Specifically, we design a two level curriculum by incorporating diagnostic sensitivity and intra-class sample representativeness for the ordering of the pretraining data. Moreover, considering the inter-class similarity of medical images, we introduce a self-paced asymmetric contrastive loss to dynamically adjust the participation of the pretraining objective. We evaluate the proposed pretraining method on three medical imaging scenarios in multiple vision-language downstream tasks, and compare it with several curriculum learning methods. Extensive experiments show that our method significantly surpasses all baselines. https://github.com/Mr-Talon/MedKCO.
Infinite-World: Scaling Interactive World Models to 1000-Frame Horizons via Pose-Free Hierarchical Memory
Feb 03, 2026We propose Infinite-World, a robust interactive world model capable of maintaining coherent visual memory over 1000+ frames in complex real-world environments. While existing world models can be efficiently optimized on synthetic data with perfect ground-truth, they lack an effective training paradigm for real-world videos due to noisy pose estimations and the scarcity of viewpoint revisits. To bridge this gap, we first introduce a Hierarchical Pose-free Memory Compressor (HPMC) that recursively distills historical latents into a fixed-budget representation. By jointly optimizing the compressor with the generative backbone, HPMC enables the model to autonomously anchor generations in the distant past with bounded computational cost, eliminating the need for explicit geometric priors. Second, we propose an Uncertainty-aware Action Labeling module that discretizes continuous motion into a tri-state logic. This strategy maximizes the utilization of raw video data while shielding the deterministic action space from being corrupted by noisy trajectories, ensuring robust action-response learning. Furthermore, guided by insights from a pilot toy study, we employ a Revisit-Dense Finetuning Strategy using a compact, 30-minute dataset to efficiently activate the model's long-range loop-closure capabilities. Extensive experiments, including objective metrics and user studies, demonstrate that Infinite-World achieves superior performance in visual quality, action controllability, and spatial consistency.
Active Intelligence in Video Avatars via Closed-loop World Modeling
Dec 23, 2025Current video avatar generation methods excel at identity preservation and motion alignment but lack genuine agency, they cannot autonomously pursue long-term goals through adaptive environmental interaction. We address this by introducing L-IVA (Long-horizon Interactive Visual Avatar), a task and benchmark for evaluating goal-directed planning in stochastic generative environments, and ORCA (Online Reasoning and Cognitive Architecture), the first framework enabling active intelligence in video avatars. ORCA embodies Internal World Model (IWM) capabilities through two key innovations: (1) a closed-loop OTAR cycle (Observe-Think-Act-Reflect) that maintains robust state tracking under generative uncertainty by continuously verifying predicted outcomes against actual generations, and (2) a hierarchical dual-system architecture where System 2 performs strategic reasoning with state prediction while System 1 translates abstract plans into precise, model-specific action captions. By formulating avatar control as a POMDP and implementing continuous belief updating with outcome verification, ORCA enables autonomous multi-step task completion in open-domain scenarios. Extensive experiments demonstrate that ORCA significantly outperforms open-loop and non-reflective baselines in task success rate and behavioral coherence, validating our IWM-inspired design for advancing video avatar intelligence from passive animation to active, goal-oriented behavior.
Astraea: A State-Aware Scheduling Engine for LLM-Powered Agents
Dec 16, 2025



Large Language Models (LLMs) are increasingly being deployed as intelligent agents. Their multi-stage workflows, which alternate between local computation and calls to external network services like Web APIs, introduce a mismatch in their execution pattern and the scheduling granularity of existing inference systems such as vLLM. Existing systems typically focus on per-segment optimization which prevents them from minimizing the end-to-end latency of the complete agentic workflow, i.e., the global Job Completion Time (JCT) over the entire request lifecycle. To address this limitation, we propose Astraea, a service engine designed to shift the optimization from local segments to the global request lifecycle. Astraea employs a state-aware, hierarchical scheduling algorithm that integrates a request's historical state with future predictions. It dynamically classifies requests by their I/O and compute intensive nature and uses an enhanced HRRN policy to balance efficiency and fairness. Astraea also implements an adaptive KV cache manager that intelligently handles the agent state during I/O waits based on the system memory pressure. Extensive experiments show that Astraea reduces average JCT by up to 25.5\% compared to baseline methods. Moreover, our approach demonstrates strong robustness and stability under high load across various model scales.
Continual Retinal Vision-Language Pre-training upon Incremental Imaging Modalities
Jun 24, 2025Traditional fundus image analysis models focus on single-modal tasks, ignoring fundus modality complementarity, which limits their versatility. Recently, retinal foundation models have emerged, but most still remain modality-specific. Integrating multiple fundus imaging modalities into a single foundation model is valuable. However, in dynamic environments, data from different modalities often arrive incrementally, necessitating continual pre-training. To address this, we propose RetCoP, the first continual vision-language pre-training framework in the fundus domain, which incrementally integrates image and text features from different imaging modalities into a single unified foundation model. To mitigate catastrophic forgetting in continual pre-training, we introduce a rehearsal strategy utilizing representative image-text pairs and an off-diagonal information distillation approach. The former allows the model to revisit knowledge from previous stages, while the latter explicitly preserves the alignment between image and text representations. Experiments show that RetCoP outperforms all the compared methods, achieving the best generalization and lowest forgetting rate. The code can be found at https://github.com/Yuang-Yao/RetCoP.
DIPO: Dual-State Images Controlled Articulated Object Generation Powered by Diverse Data
May 28, 2025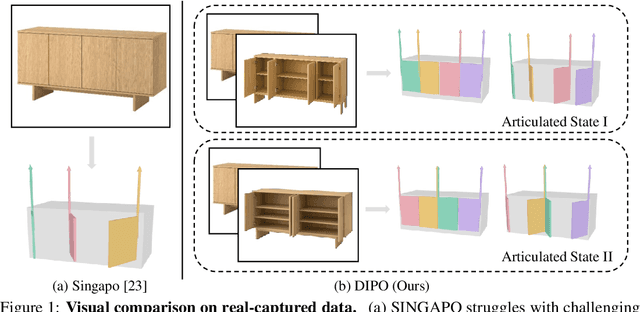
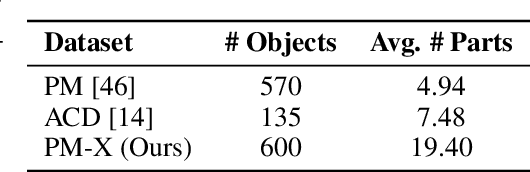
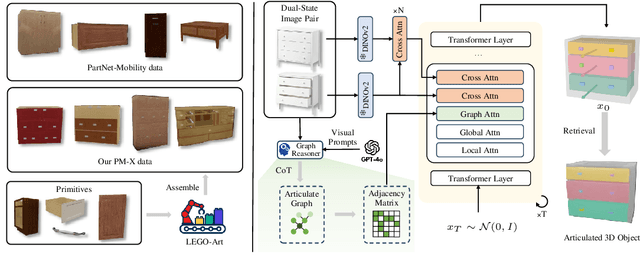
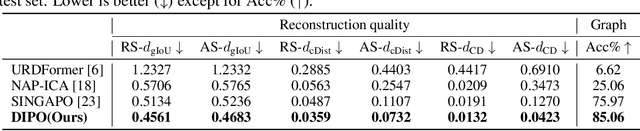
We present DIPO, a novel framework for the controllable generation of articulated 3D objects from a pair of images: one depicting the object in a resting state and the other in an articulated state. Compared to the single-image approach, our dual-image input imposes only a modest overhead for data collection, but at the same time provides important motion information, which is a reliable guide for predicting kinematic relationships between parts. Specifically, we propose a dual-image diffusion model that captures relationships between the image pair to generate part layouts and joint parameters. In addition, we introduce a Chain-of-Thought (CoT) based graph reasoner that explicitly infers part connectivity relationships. To further improve robustness and generalization on complex articulated objects, we develop a fully automated dataset expansion pipeline, name LEGO-Art, that enriches the diversity and complexity of PartNet-Mobility dataset. We propose PM-X, a large-scale dataset of complex articulated 3D objects, accompanied by rendered images, URDF annotations, and textual descriptions. Extensive experiments demonstrate that DIPO significantly outperforms existing baselines in both the resting state and the articulated state, while the proposed PM-X dataset further enhances generalization to diverse and structurally complex articulated objects. Our code and dataset will be released to the community upon publication.
Iterative Predictor-Critic Code Decoding for Real-World Image Dehazing
Mar 17, 2025



We propose a novel Iterative Predictor-Critic Code Decoding framework for real-world image dehazing, abbreviated as IPC-Dehaze, which leverages the high-quality codebook prior encapsulated in a pre-trained VQGAN. Apart from previous codebook-based methods that rely on one-shot decoding, our method utilizes high-quality codes obtained in the previous iteration to guide the prediction of the Code-Predictor in the subsequent iteration, improving code prediction accuracy and ensuring stable dehazing performance. Our idea stems from the observations that 1) the degradation of hazy images varies with haze density and scene depth, and 2) clear regions play crucial cues in restoring dense haze regions. However, it is non-trivial to progressively refine the obtained codes in subsequent iterations, owing to the difficulty in determining which codes should be retained or replaced at each iteration. Another key insight of our study is to propose Code-Critic to capture interrelations among codes. The Code-Critic is used to evaluate code correlations and then resample a set of codes with the highest mask scores, i.e., a higher score indicates that the code is more likely to be rejected, which helps retain more accurate codes and predict difficult ones. Extensive experiments demonstrate the superiority of our method over state-of-the-art methods in real-world dehazing.
SeCap: Self-Calibrating and Adaptive Prompts for Cross-view Person Re-Identification in Aerial-Ground Networks
Mar 10, 2025



When discussing the Aerial-Ground Person Re-identification (AGPReID) task, we face the main challenge of the significant appearance variations caused by different viewpoints, making identity matching difficult. To address this issue, previous methods attempt to reduce the differences between viewpoints by critical attributes and decoupling the viewpoints. While these methods can mitigate viewpoint differences to some extent, they still face two main issues: (1) difficulty in handling viewpoint diversity and (2) neglect of the contribution of local features. To effectively address these challenges, we design and implement the Self-Calibrating and Adaptive Prompt (SeCap) method for the AGPReID task. The core of this framework relies on the Prompt Re-calibration Module (PRM), which adaptively re-calibrates prompts based on the input. Combined with the Local Feature Refinement Module (LFRM), SeCap can extract view-invariant features from local features for AGPReID. Meanwhile, given the current scarcity of datasets in the AGPReID field, we further contribute two real-world Large-scale Aerial-Ground Person Re-Identification datasets, LAGPeR and G2APS-ReID. The former is collected and annotated by us independently, covering $4,231$ unique identities and containing $63,841$ high-quality images; the latter is reconstructed from the person search dataset G2APS. Through extensive experiments on AGPReID datasets, we demonstrate that SeCap is a feasible and effective solution for the AGPReID task. The datasets and source code available on https://github.com/wangshining681/SeCap-AGPReID.