 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeCap: Self-Calibrating and Adaptive Prompts for Cross-view Person Re-Identification in Aerial-Ground Networks
Mar 10, 2025



When discussing the Aerial-Ground Person Re-identification (AGPReID) task, we face the main challenge of the significant appearance variations caused by different viewpoints, making identity matching difficult. To address this issue, previous methods attempt to reduce the differences between viewpoints by critical attributes and decoupling the viewpoints. While these methods can mitigate viewpoint differences to some extent, they still face two main issues: (1) difficulty in handling viewpoint diversity and (2) neglect of the contribution of local features. To effectively address these challenges, we design and implement the Self-Calibrating and Adaptive Prompt (SeCap) method for the AGPReID task. The core of this framework relies on the Prompt Re-calibration Module (PRM), which adaptively re-calibrates prompts based on the input. Combined with the Local Feature Refinement Module (LFRM), SeCap can extract view-invariant features from local features for AGPReID. Meanwhile, given the current scarcity of datasets in the AGPReID field, we further contribute two real-world Large-scale Aerial-Ground Person Re-Identification datasets, LAGPeR and G2APS-ReID. The former is collected and annotated by us independently, covering $4,231$ unique identities and containing $63,841$ high-quality images; the latter is reconstructed from the person search dataset G2APS. Through extensive experiments on AGPReID datasets, we demonstrate that SeCap is a feasible and effective solution for the AGPReID task. The datasets and source code available on https://github.com/wangshining681/SeCap-AGPReID.
Dynamic Textual Prompt For Rehearsal-free Lifelong Person Re-identification
Nov 09, 2024



Lifelong person re-identification attempts to recognize people across cameras and integrate new knowledge from continuous data streams. Key challenges involve addressing catastrophic forgetting caused by parameter updating and domain shift, and maintaining performance in seen and unseen domains. Many previous works rely on data memories to retain prior samples. However, the amount of retained data increases linearly with the number of training domains, leading to continually increasing memory consumption. Additionally, these methods may suffer significant performance degradation when data preservation is prohibited due to privacy concerns. To address these limitations, we propose using textual descriptions as guidance to encourage the ReID model to learn cross-domain invariant features without retaining samples. The key insight is that natural language can describe pedestrian instances with an invariant style, suggesting a shared textual space for any pedestrian images. By leveraging this shared textual space as an anchor, we can prompt the ReID model to embed images from various domains into a unified semantic space, thereby alleviating catastrophic forgetting caused by domain shifts. To achieve this, we introduce a task-driven dynamic textual prompt framework in this paper. This model features a dynamic prompt fusion module, which adaptively constructs and fuses two different textual prompts as anchors. This effectively guides the ReID model to embed images into a unified semantic space. Additionally, we design a text-visual feature alignment module to learn a more precise mapping between fine-grained visual and textual features. We also developed a learnable knowledge distillation module that allows our model to dynamically balance retaining existing knowledge with acquiring new knowledge. Extensive experiments demonstrate that our method outperforms SOTAs under various settings.
Enhancing Visible-Infrared Person Re-identification with Modality- and Instance-aware Visual Prompt Learning
Jun 18, 2024



The Visible-Infrared Person Re-identification (VI ReID) aims to match visible and infrared images of the same pedestrians across non-overlapped camera views. These two input modalities contain both invariant information, such as shape, and modality-specific details, such as color. An ideal model should utilize valuable information from both modalities during training for enhanced representational capability. However, the gap caused by modality-specific information poses substantial challenges for the VI ReID model to handle distinct modality inputs simultaneously. To address this, we introduce the Modality-aware and Instance-aware Visual Prompts (MIP) network in our work, designed to effectively utilize both invariant and specific information for identification. Specifically, our MIP model is built on the transformer architecture. In this model, we have designed a series of modality-specific prompts, which could enable our model to adapt to and make use of the specific information inherent in different modality inputs, thereby reducing the interference caused by the modality gap and achieving better identification. Besides, we also employ each pedestrian feature to construct a group of instance-specific prompts. These customized prompts are responsible for guiding our model to adapt to each pedestrian instance dynamically, thereby capturing identity-level discriminative clues for identification. Through extensive experiments on SYSU-MM01 and RegDB datasets, the effectiveness of both our designed modules is evaluated. Additionally, our proposed MIP performs better than most state-of-the-art methods.
* Accepyed by ACM International Conference on Multimedia Retrieval (ICMR'24)
Dual-Modal Prompting for Sketch-Based Image Retrieval
Apr 29, 2024



Sketch-based image retrieval (SBIR) associates hand-drawn sketches with their corresponding realistic images. In this study, we aim to tackle two major challenges of this task simultaneously: i) zero-shot, dealing with unseen categories, and ii) fine-grained, referring to intra-category instance-level retrieval. Our key innovation lies in the realization that solely addressing this cross-category and fine-grained recognition task from the generalization perspective may be inadequate since the knowledge accumulated from limited seen categories might not be fully valuable or transferable to unseen target categories. Inspired by this, in this work, we propose a dual-modal prompting CLIP (DP-CLIP) network, in which an adaptive prompting strategy is designed. Specifically, to facilitate the adaptation of our DP-CLIP toward unpredictable target categories, we employ a set of images within the target category and the textual category label to respectively construct a set of category-adaptive prompt tokens and channel scales. By integrating the generated guidance, DP-CLIP could gain valuable category-centric insights, efficiently adapting to novel categories and capturing unique discriminative clues for effective retrieval within each target category. With these designs, our DP-CLIP outperforms the state-of-the-art fine-grained zero-shot SBIR method by 7.3% in Acc.@1 on the Sketchy dataset. Meanwhile, in the other two category-level zero-shot SBIR benchmarks, our method also achieves promising performance.
Generalizable Person Re-Identification via Viewpoint Alignment and Fusion
Dec 05, 2022



In the current person Re-identification (ReID) methods, most domain generalization works focus on dealing with style differences between domains while largely ignoring unpredictable camera view change, which we identify as another major factor leading to a poor generalization of ReID methods. To tackle the viewpoint change, this work proposes to use a 3D dense pose estimation model and a texture mapping module to map the pedestrian images to canonical view images. Due to the imperfection of the texture mapping module, the canonical view images may lose the discriminative detail clues from the original images, and thus directly using them for ReID will inevitably result in poor performance. To handle this issue, we propose to fuse the original image and canonical view image via a transformer-based module. The key insight of this design is that the cross-attention mechanism in the transformer could be an ideal solution to align the discriminative texture clues from the original image with the canonical view image, which could compensate for the low-quality texture information of the canonical view image. Through extensive experiments, we show that our method can lead to superior performance over the existing approaches in various evaluation settings.
Instance and Pair-Aware Dynamic Networks for Re-Identification
Mar 29, 2021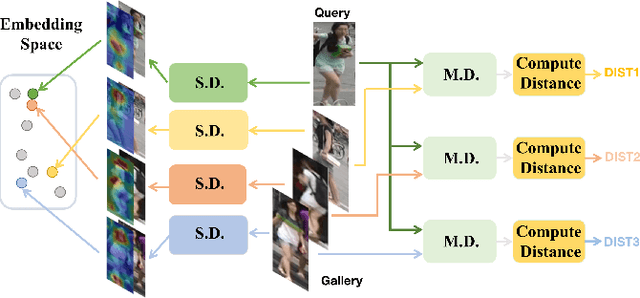
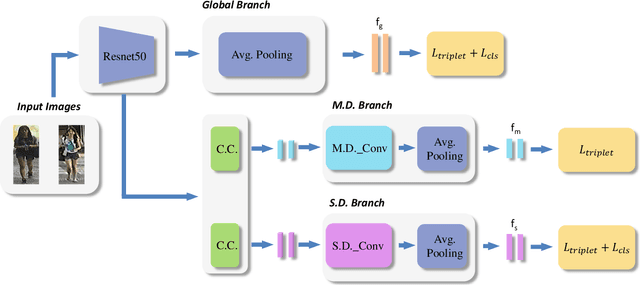
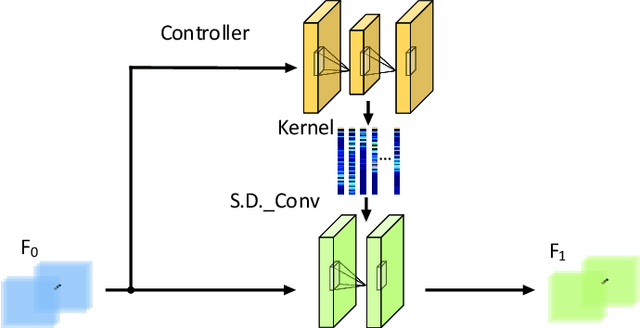

Re-identification (ReID) is to identify the same instance across different cameras. Existing ReID methods mostly utilize alignment-based or attention-based strategies to generate effective feature representations. However, most of these methods only extract general feature by employing single input image itself, overlooking the exploration of relevance between comparing images. To fill this gap, we propose a novel end-to-end trainable dynamic convolution framework named Instance and Pair-Aware Dynamic Networks in this paper. The proposed model is composed of three main branches where a self-guided dynamic branch is constructed to strengthen instance-specific features, focusing on every single image. Furthermore, we also design a mutual-guided dynamic branch to generate pair-aware features for each pair of images to be compared. Extensive experiments are conducted in order to verify the effectiveness of our proposed algorithm. We evaluate our algorithm in several mainstream person and vehicle ReID datasets including CUHK03, DukeMTMCreID, Market-1501, VeRi776 and VehicleID. In some datasets our algorithm outperforms state-of-the-art methods and in others, our algorithm achieves a comparable performance.
Person Re-identification in Aerial Imagery
Aug 14, 2019



Nowadays, with the rapid development of consumer Unmanned Aerial Vehicles (UAVs), visual surveillance by utilizing the UAV platform has been very attractive. Most of the research works for UAV captured visual data are mainly focused on the tasks of object detection and tracking. However, limited attention has been paid to the task of person Re-identification (ReID) which has been widely studied in ordinary surveillance cameras with fixed emplacements. In this paper, to facilitate the research of person ReID in aerial imagery, we collect a large scale airborne person ReID dataset named as Person ReID for Aerial Imagery (PRAI-1581), which consists of 39,461 images of 1581 person identities. The images of the dataset are captured by two DJI consumer UAVs flying at an altitude ranging from 20 to 60 meters above the ground, which covers most of the real UAV surveillance scenarios. In addition, we propose to utilize subspace pooling with SVD of convolution feature maps to represent the input person images. The proposed method can learn a discriminative and compact feature descriptor for ReID in aerial imagery and can be trained via an end-to-end fashion efficiently. We conduct extensive experiments on our dataset and the experimental results demonstrate that the proposed method achieves state-of-the-art performance.
Vehicle Re-identification in Aerial Imagery: Dataset and Approach
Apr 02, 2019
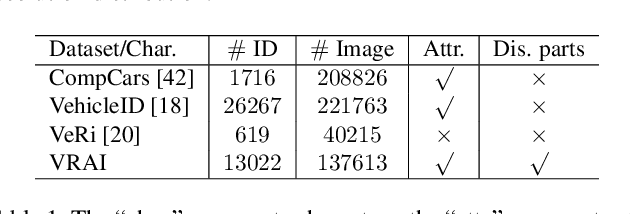

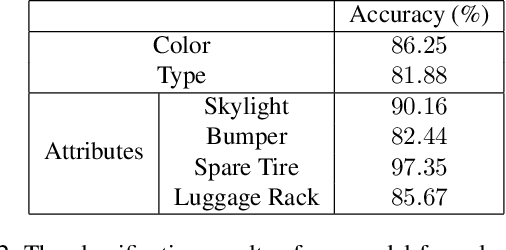
In this work, we construct a large-scale dataset for vehicle re-identification (ReID), which contains 137k images of 13k vehicle instances captured by UAV-mounted cameras. To our knowledge, it is the largest UAV-based vehicle ReID dataset. To increase intra-class variation, each vehicle is captured by at least two UAVs at different locations, with diverse view-angles and flight-altitudes. We manually label a variety of vehicle attributes, including vehicle type, color, skylight, bumper, spare tire and luggage rack. Furthermore, for each vehicle image, the annotator is also required to mark the discriminative parts that helps them to distinguish this particular vehicle from others. Besides the dataset, we also design a specific vehicle ReID algorithm to make full use of the rich annotation information. It is capable of explicitly detecting discriminative parts for each specific vehicle and significantly outperforms the evaluated baselines and state-of-the-art vehicle ReID approaches.