 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeta-learning with an Adaptive Task Scheduler
Oct 26, 2021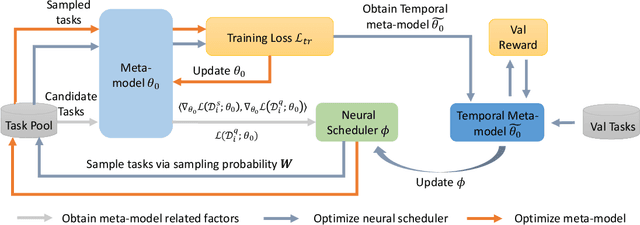
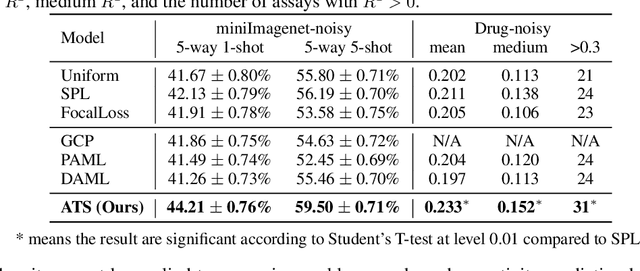
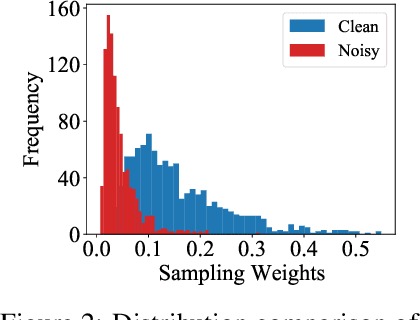
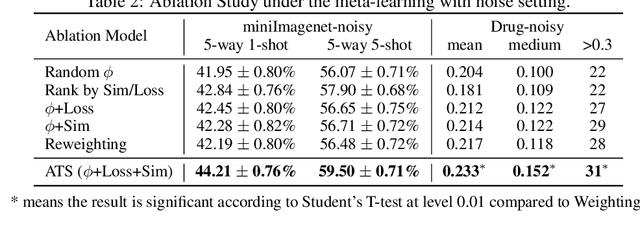
To benefit the learning of a new task, meta-learning has been proposed to transfer a well-generalized meta-model learned from various meta-training tasks. Existing meta-learning algorithms randomly sample meta-training tasks with a uniform probability, under the assumption that tasks are of equal importance. However, it is likely that tasks are detrimental with noise or imbalanced given a limited number of meta-training tasks. To prevent the meta-model from being corrupted by such detrimental tasks or dominated by tasks in the majority, in this paper, we propose an adaptive task scheduler (ATS) for the meta-training process. In ATS, for the first time, we design a neural scheduler to decide which meta-training tasks to use next by predicting the probability being sampled for each candidate task, and train the scheduler to optimize the generalization capacity of the meta-model to unseen tasks. We identify two meta-model-related factors as the input of the neural scheduler, which characterize the difficulty of a candidate task to the meta-model. Theoretically, we show that a scheduler taking the two factors into account improves the meta-training loss and also the optimization landscape. Under the setting of meta-learning with noise and limited budgets, ATS improves the performance on both miniImageNet and a real-world drug discovery benchmark by up to 13% and 18%, respectively, compared to state-of-the-art task schedulers.
Value Penalized Q-Learning for Recommender Systems
Oct 15, 2021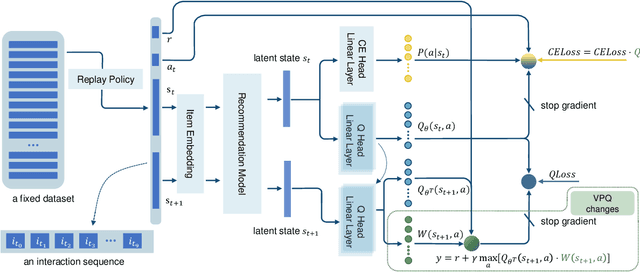
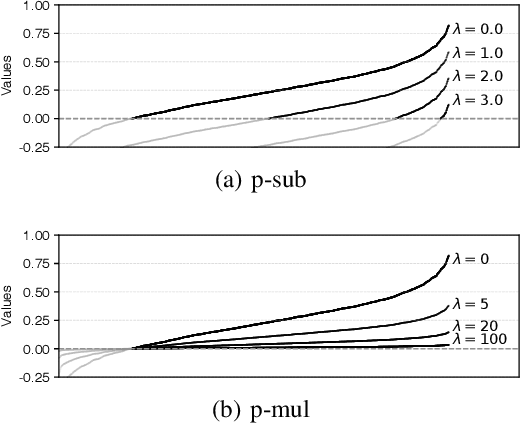
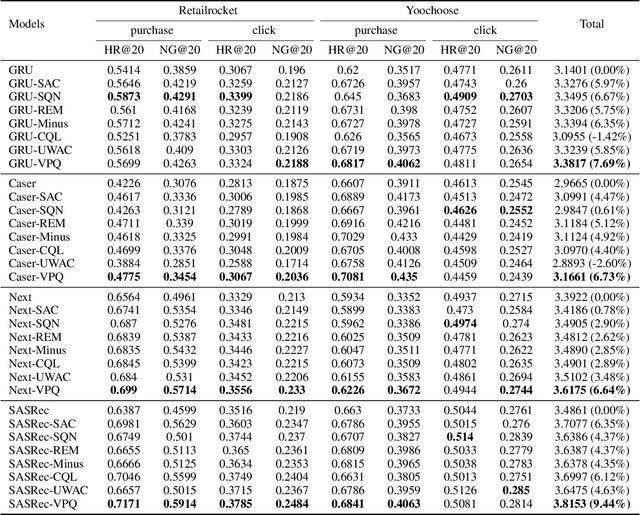
Scaling reinforcement learning (RL) to recommender systems (RS) is promising since maximizing the expected cumulative rewards for RL agents meets the objective of RS, i.e., improving customers' long-term satisfaction. A key approach to this goal is offline RL, which aims to learn policies from logged data. However, the high-dimensional action space and the non-stationary dynamics in commercial RS intensify distributional shift issues, making it challenging to apply offline RL methods to RS. To alleviate the action distribution shift problem in extracting RL policy from static trajectories, we propose Value Penalized Q-learning (VPQ), an uncertainty-based offline RL algorithm. It penalizes the unstable Q-values in the regression target by uncertainty-aware weights, without the need to estimate the behavior policy, suitable for RS with a large number of items. We derive the penalty weights from the variances across an ensemble of Q-functions. To alleviate distributional shift issues at test time, we further introduce the critic framework to integrate the proposed method with classic RS models. Extensive experiments conducted on two real-world datasets show that the proposed method could serve as a gain plugin for existing RS models.
Local Augmentation for Graph Neural Networks
Sep 08, 2021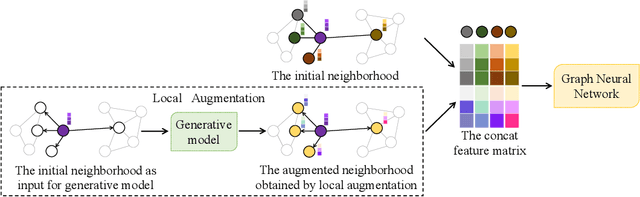
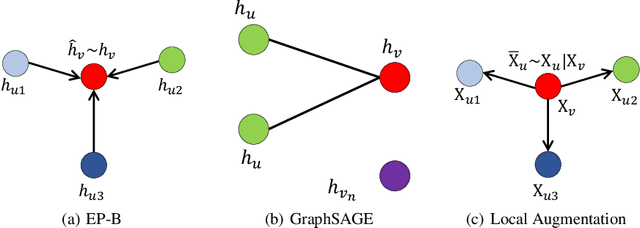

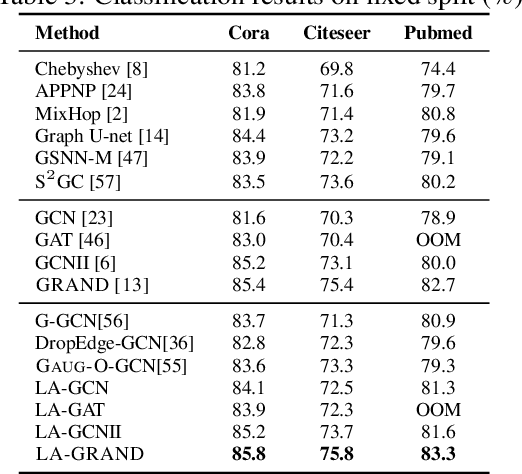
Data augmentation has been widely used in image data and linguistic data but remains under-explored on graph-structured data. Existing methods focus on augmenting the graph data from a global perspective and largely fall into two genres: structural manipulation and adversarial training with feature noise injection. However, the structural manipulation approach suffers information loss issues while the adversarial training approach may downgrade the feature quality by injecting noise. In this work, we introduce the local augmentation, which enhances node features by its local subgraph structures. Specifically, we model the data argumentation as a feature generation process. Given the central node's feature, our local augmentation approach learns the conditional distribution of its neighbors' features and generates the neighbors' optimal feature to boost the performance of downstream tasks. Based on the local augmentation, we further design a novel framework: LA-GNN, which can apply to any GNN models in a plug-and-play manner. Extensive experiments and analyses show that local augmentation consistently yields performance improvement for various GNN architectures across a diverse set of benchmarks. Code is available at https://github.com/Soughing0823/LAGNN.
AdaXpert: Adapting Neural Architecture for Growing Data
Jul 01, 2021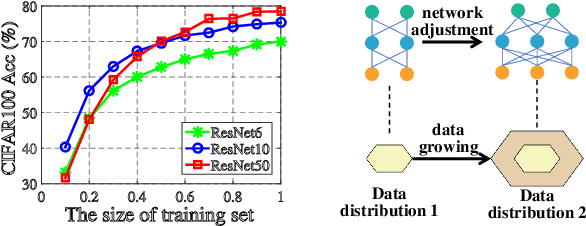
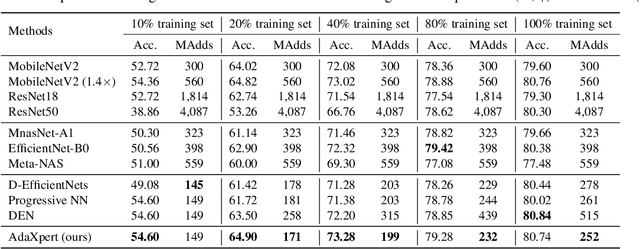
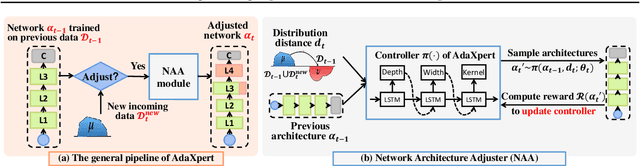
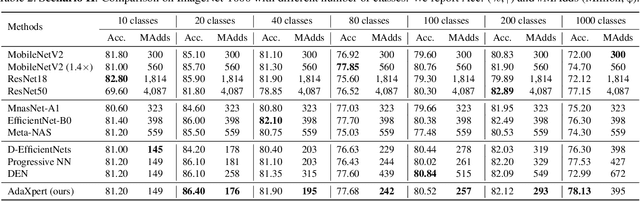
In real-world applications, data often come in a growing manner, where the data volume and the number of classes may increase dynamically. This will bring a critical challenge for learning: given the increasing data volume or the number of classes, one has to instantaneously adjust the neural model capacity to obtain promising performance. Existing methods either ignore the growing nature of data or seek to independently search an optimal architecture for a given dataset, and thus are incapable of promptly adjusting the architectures for the changed data. To address this, we present a neural architecture adaptation method, namely Adaptation eXpert (AdaXpert), to efficiently adjust previous architectures on the growing data. Specifically, we introduce an architecture adjuster to generate a suitable architecture for each data snapshot, based on the previous architecture and the different extent between current and previous data distributions. Furthermore, we propose an adaptation condition to determine the necessity of adjustment, thereby avoiding unnecessary and time-consuming adjustments. Extensive experiments on two growth scenarios (increasing data volume and number of classes) demonstrate the effectiveness of the proposed method.
Learning Graphon Autoencoders for Generative Graph Modeling
May 29, 2021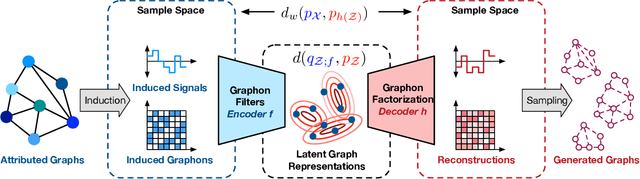
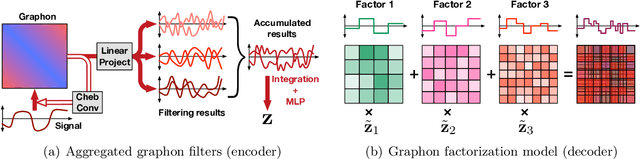

Graphon is a nonparametric model that generates graphs with arbitrary sizes and can be induced from graphs easily. Based on this model, we propose a novel algorithmic framework called \textit{graphon autoencoder} to build an interpretable and scalable graph generative model. This framework treats observed graphs as induced graphons in functional space and derives their latent representations by an encoder that aggregates Chebshev graphon filters. A linear graphon factorization model works as a decoder, leveraging the latent representations to reconstruct the induced graphons (and the corresponding observed graphs). We develop an efficient learning algorithm to learn the encoder and the decoder, minimizing the Wasserstein distance between the model and data distributions. This algorithm takes the KL divergence of the graph distributions conditioned on different graphons as the underlying distance and leads to a reward-augmented maximum likelihood estimation. The graphon autoencoder provides a new paradigm to represent and generate graphs, which has good generalizability and transferability.
Exploring Robustness of Unsupervised Domain Adaptation in Semantic Segmentation
May 23, 2021
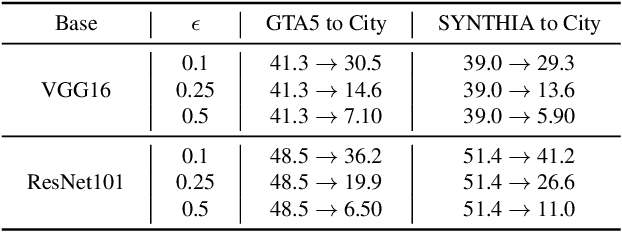
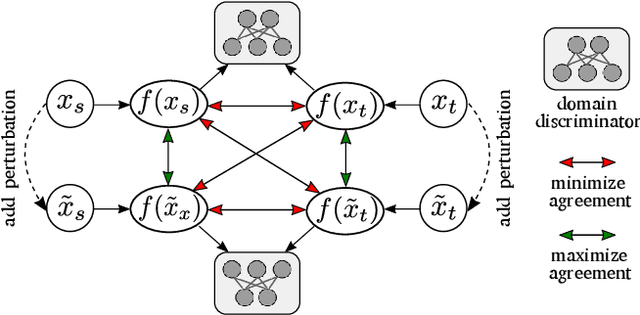
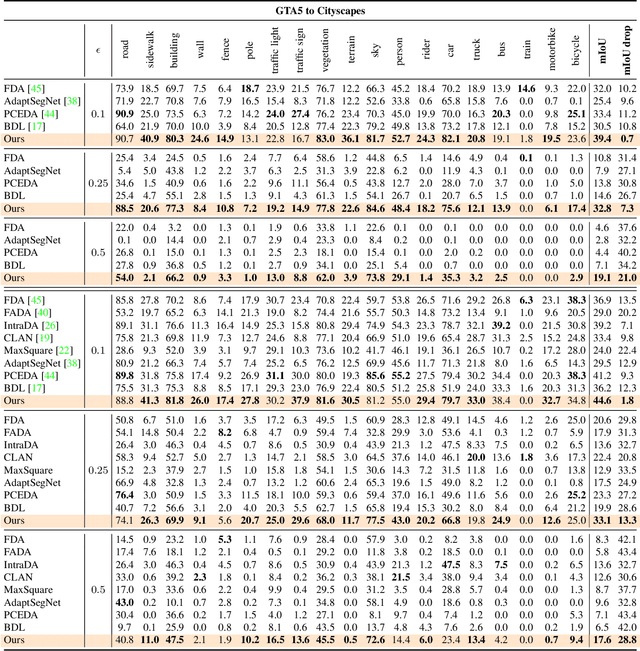
Recent studies imply that deep neural networks are vulnerable to adversarial examples -- inputs with a slight but intentional perturbation are incorrectly classified by the network. Such vulnerability makes it risky for some security-related applications (e.g., semantic segmentation in autonomous cars) and triggers tremendous concerns on the model reliability. For the first time, we comprehensively evaluate the robustness of existing UDA methods and propose a robust UDA approach. It is rooted in two observations: (i) the robustness of UDA methods in semantic segmentation remains unexplored, which pose a security concern in this field; and (ii) although commonly used self-supervision (e.g., rotation and jigsaw) benefits image tasks such as classification and recognition, they fail to provide the critical supervision signals that could learn discriminative representation for segmentation tasks. These observations motivate us to propose adversarial self-supervision UDA (or ASSUDA) that maximizes the agreement between clean images and their adversarial examples by a contrastive loss in the output space. Extensive empirical studies on commonly used benchmarks demonstrate that ASSUDA is resistant to adversarial attacks.
Sparse online relative similarity learning
Apr 15, 2021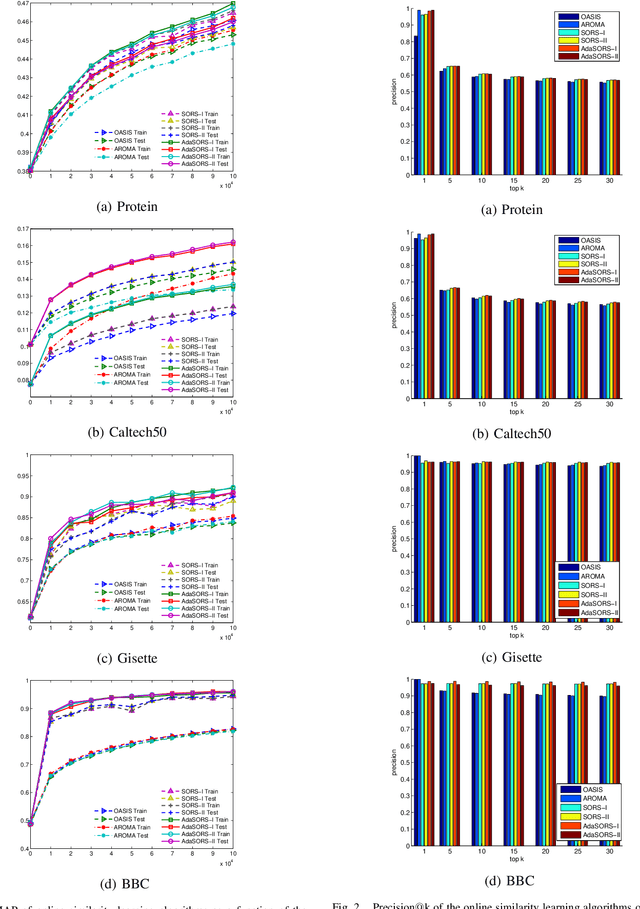
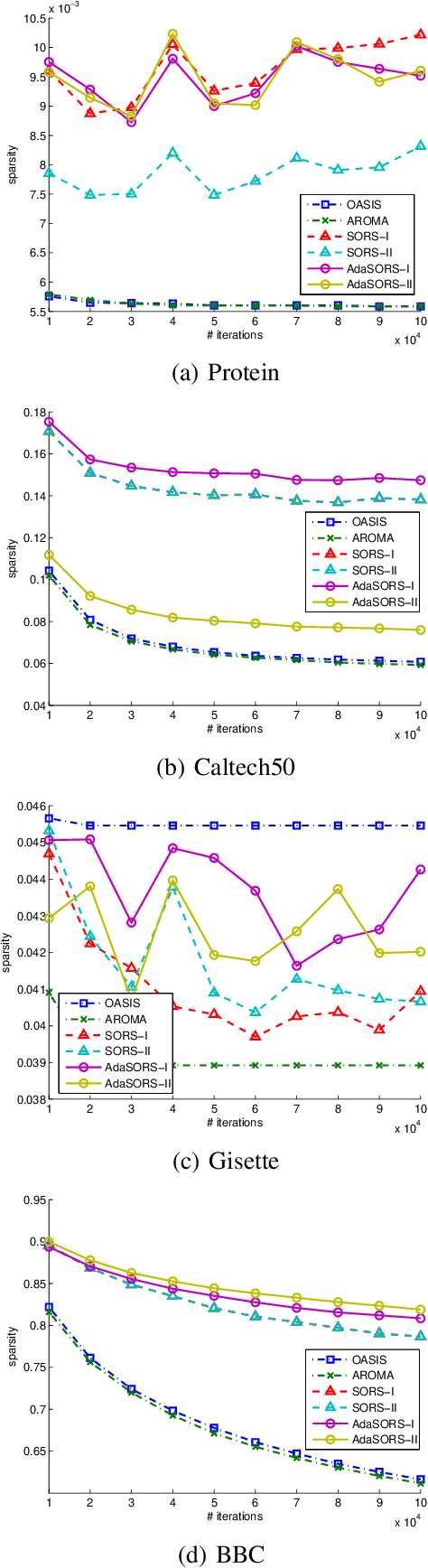
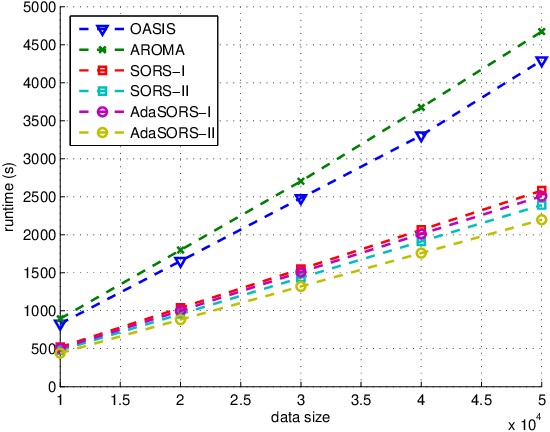
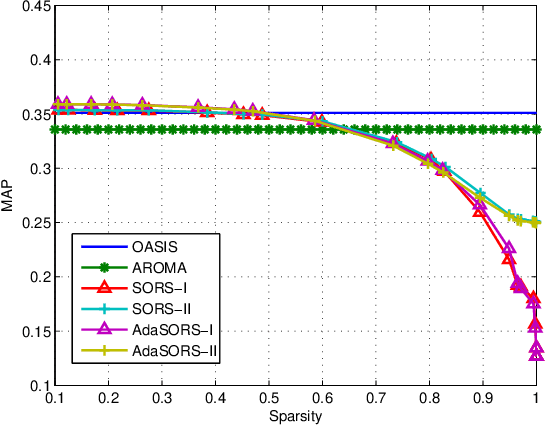
For many data mining and machine learning tasks, the quality of a similarity measure is the key for their performance. To automatically find a good similarity measure from datasets, metric learning and similarity learning are proposed and studied extensively. Metric learning will learn a Mahalanobis distance based on positive semi-definite (PSD) matrix, to measure the distances between objectives, while similarity learning aims to directly learn a similarity function without PSD constraint so that it is more attractive. Most of the existing similarity learning algorithms are online similarity learning method, since online learning is more scalable than offline learning. However, most existing online similarity learning algorithms learn a full matrix with d 2 parameters, where d is the dimension of the instances. This is clearly inefficient for high dimensional tasks due to its high memory and computational complexity. To solve this issue, we introduce several Sparse Online Relative Similarity (SORS) learning algorithms, which learn a sparse model during the learning process, so that the memory and computational cost can be significantly reduced. We theoretically analyze the proposed algorithms, and evaluate them on some real-world high dimensional datasets. Encouraging empirical results demonstrate the advantages of our approach in terms of efficiency and efficacy.
FedGraphNN: A Federated Learning System and Benchmark for Graph Neural Networks
Apr 14, 2021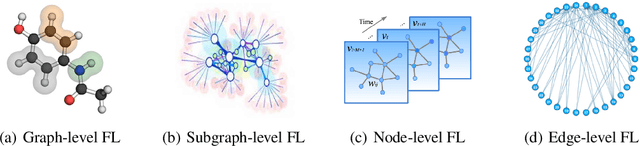
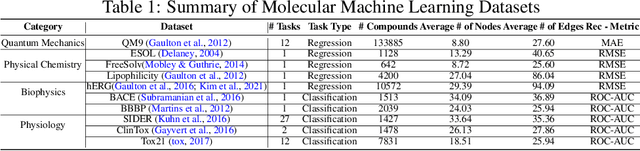
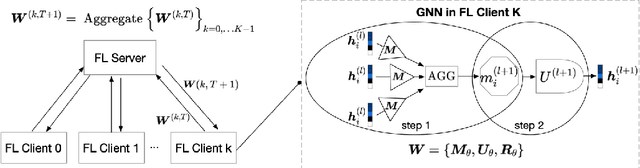
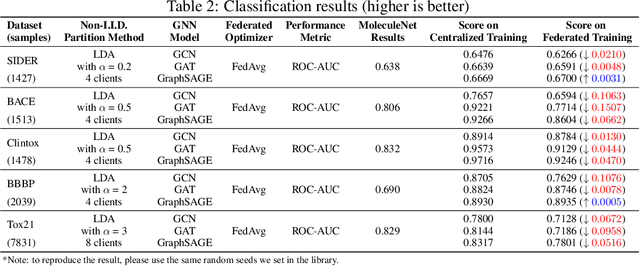
Graph Neural Network (GNN) research is rapidly growing thanks to the capacity of GNNs to learn representations from graph-structured data. However, centralizing a massive amount of real-world graph data for GNN training is prohibitive due to user-side privacy concerns, regulation restrictions, and commercial competition. Federated learning (FL), a trending distributed learning paradigm, aims to solve this challenge while preserving privacy. Despite recent advances in vision and language domains, there is no suitable platform for the federated training of GNNs. To this end, we introduce FedGraphNN, an open research federated learning system and a benchmark to facilitate GNN-based FL research. FedGraphNN is built on a unified formulation of federated GNNs and supports commonly used datasets, GNN models, FL algorithms, and flexible APIs. We also contribute a new molecular dataset, hERG, to promote research exploration. Our experimental results present significant challenges in federated GNN training: federated GNNs perform worse in most datasets with a non-I.I.D split than centralized GNNs; the GNN model that attains the best result in the centralized setting may not hold its advantage in the federated setting. These results imply that more research efforts are needed to unravel the mystery behind federated GNN training. Moreover, our system performance analysis demonstrates that the FedGraphNN system is computationally affordable to most research labs with limited GPUs. We maintain the source code at https://github.com/FedML-AI/FedGraphNN.
Pareto-Frontier-aware Neural Architecture Generation for Diverse Budgets
Feb 27, 2021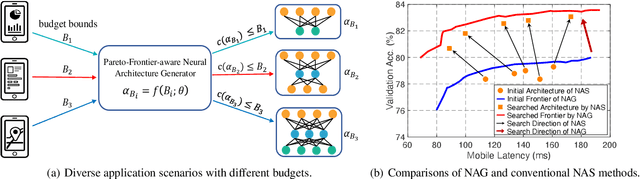
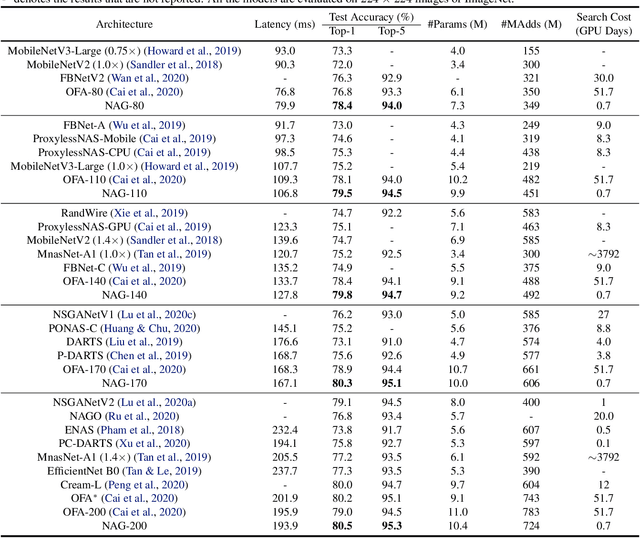
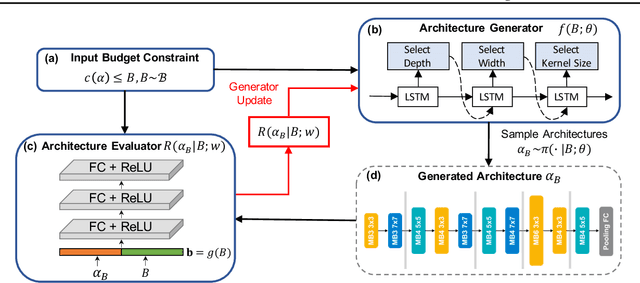

Designing feasible and effective architectures under diverse computation budgets incurred by different applications/devices is essential for deploying deep models in practice. Existing methods often perform an independent architecture search for each target budget, which is very inefficient yet unnecessary. Moreover, the repeated independent search manner would inevitably ignore the common knowledge among different search processes and hamper the search performance. To address these issues, we seek to train a general architecture generator that automatically produces effective architectures for an arbitrary budget merely via model inference. To this end, we propose a Pareto-Frontier-aware Neural Architecture Generator (NAG) which takes an arbitrary budget as input and produces the Pareto optimal architecture for the target budget. We train NAG by learning the Pareto frontier (i.e., the set of Pareto optimal architectures) over model performance and computational cost (e.g., latency). Extensive experiments on three platforms (i.e., mobile, CPU, and GPU) show the superiority of the proposed method over existing NAS methods.
Towards Accurate and Compact Architectures via Neural Architecture Transformer
Feb 20, 2021
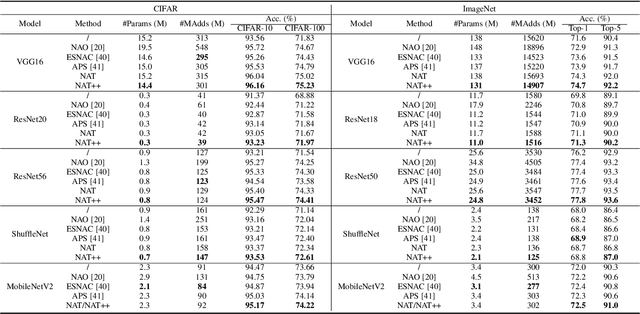
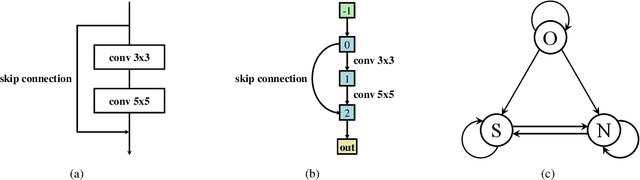
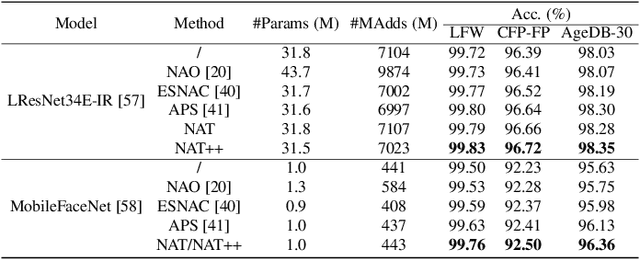
Designing effective architectures is one of the key factors behind the success of deep neural networks. Existing deep architectures are either manually designed or automatically searched by some Neural Architecture Search (NAS) methods. However, even a well-designed/searched architecture may still contain many nonsignificant or redundant modules/operations. Thus, it is necessary to optimize the operations inside an architecture to improve the performance without introducing extra computational cost. To this end, we have proposed a Neural Architecture Transformer (NAT) method which casts the optimization problem into a Markov Decision Process (MDP) and seeks to replace the redundant operations with more efficient operations, such as skip or null connection. Note that NAT only considers a small number of possible transitions and thus comes with a limited search/transition space. As a result, such a small search space may hamper the performance of architecture optimization. To address this issue, we propose a Neural Architecture Transformer++ (NAT++) method which further enlarges the set of candidate transitions to improve the performance of architecture optimization. Specifically, we present a two-level transition rule to obtain valid transitions, i.e., allowing operations to have more efficient types (e.g., convolution->separable convolution) or smaller kernel sizes (e.g., 5x5->3x3). Note that different operations may have different valid transitions. We further propose a Binary-Masked Softmax (BMSoftmax) layer to omit the possible invalid transitions. Extensive experiments on several benchmark datasets show that the transformed architecture significantly outperforms both its original counterpart and the architectures optimized by existing methods.