 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSource-free Domain Adaptation via Avatar Prototype Generation and Adaptation
Jun 18, 2021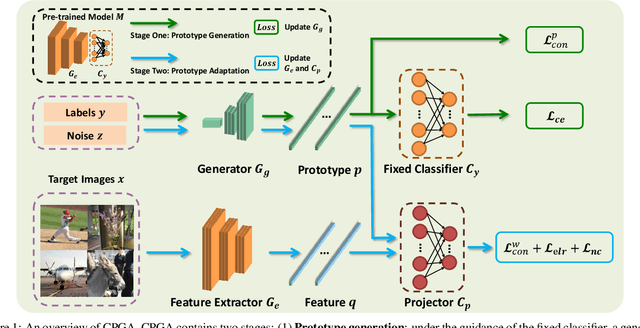
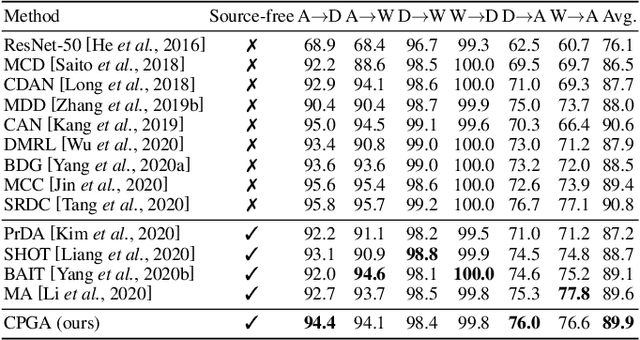
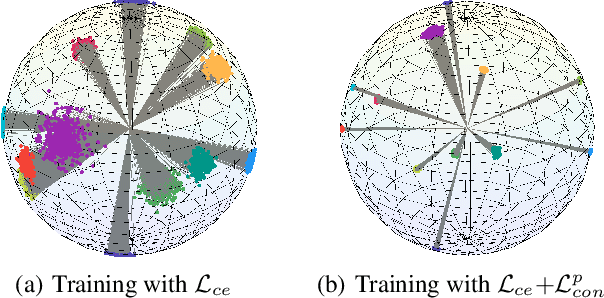
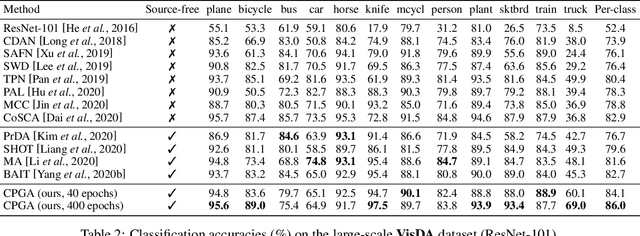
We study a practical domain adaptation task, called source-free unsupervised domain adaptation (UDA) problem, in which we cannot access source domain data due to data privacy issues but only a pre-trained source model and unlabeled target data are available. This task, however, is very difficult due to one key challenge: the lack of source data and target domain labels makes model adaptation very challenging. To address this, we propose to mine the hidden knowledge in the source model and exploit it to generate source avatar prototypes (i.e., representative features for each source class) as well as target pseudo labels for domain alignment. To this end, we propose a Contrastive Prototype Generation and Adaptation (CPGA) method. Specifically, CPGA consists of two stages: (1) prototype generation: by exploring the classification boundary information of the source model, we train a prototype generator to generate avatar prototypes via contrastive learning. (2) prototype adaptation: based on the generated source prototypes and target pseudo labels, we develop a new robust contrastive prototype adaptation strategy to align each pseudo-labeled target data to the corresponding source prototypes. Extensive experiments on three UDA benchmark datasets demonstrate the effectiveness and superiority of the proposed method.
ASCNet: Self-supervised Video Representation Learning with Appearance-Speed Consistency
Jun 04, 2021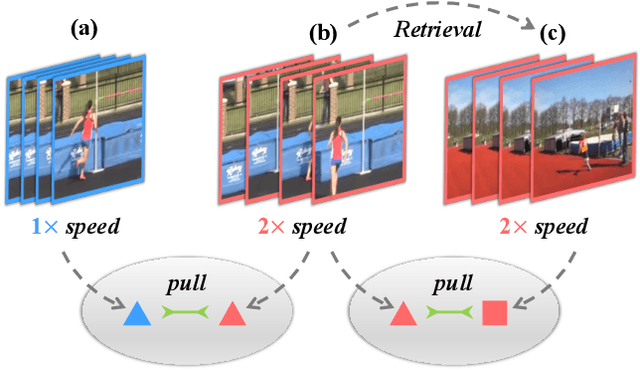

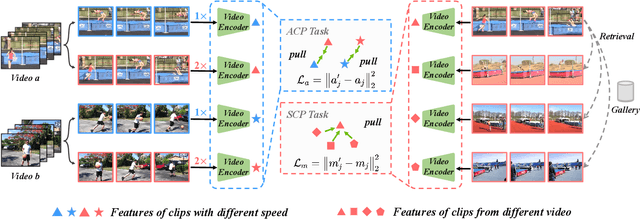
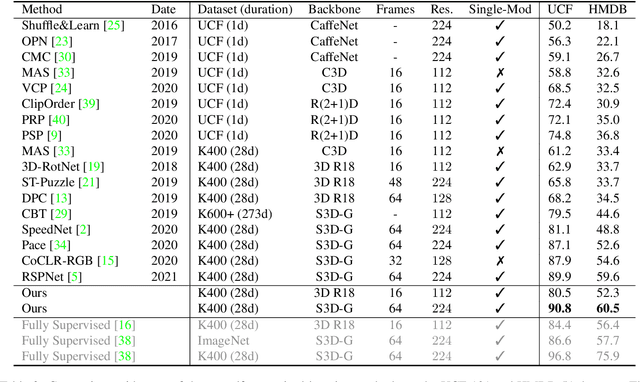
We study self-supervised video representation learning, which is a challenging task due to 1) a lack of labels for explicit supervision and 2) unstructured and noisy visual information. Existing methods mainly use contrastive loss with video clips as the instances and learn visual representation by discriminating instances from each other, but they require careful treatment of negative pairs by relying on large batch sizes, memory banks, extra modalities, or customized mining strategies, inevitably including noisy data. In this paper, we observe that the consistency between positive samples is the key to learn robust video representations. Specifically, we propose two tasks to learn the appearance and speed consistency, separately. The appearance consistency task aims to maximize the similarity between two clips of the same video with different playback speeds. The speed consistency task aims to maximize the similarity between two clips with the same playback speed but different appearance information. We show that joint optimization of the two tasks consistently improves the performance on downstream tasks, e.g., action recognition and video retrieval. Remarkably, for action recognition on the UCF-101 dataset, we achieve 90.8% accuracy without using any additional modalities or negative pairs for unsupervised pretraining, outperforming the ImageNet supervised pre-trained model. Codes and models will be available.
Towards Accurate Text-based Image Captioning with Content Diversity Exploration
Apr 23, 2021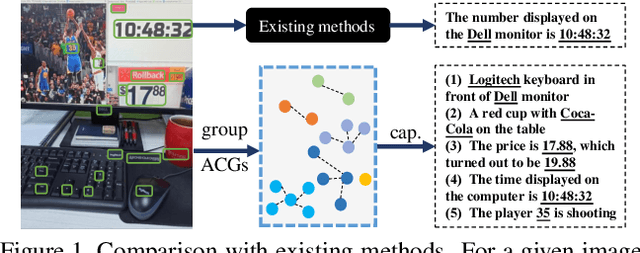
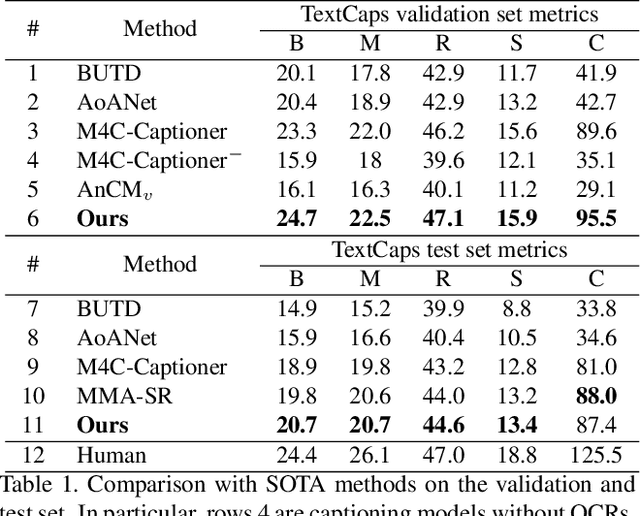
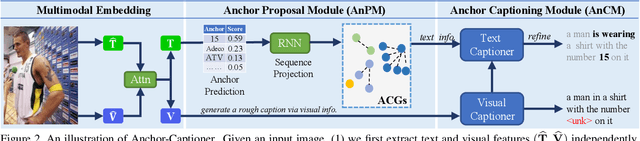
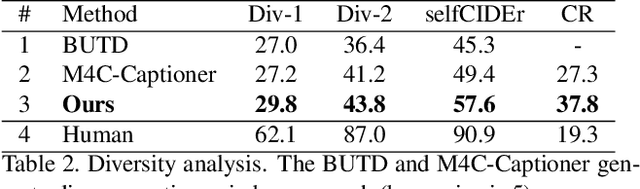
Text-based image captioning (TextCap) which aims to read and reason images with texts is crucial for a machine to understand a detailed and complex scene environment, considering that texts are omnipresent in daily life. This task, however, is very challenging because an image often contains complex texts and visual information that is hard to be described comprehensively. Existing methods attempt to extend the traditional image captioning methods to solve this task, which focus on describing the overall scene of images by one global caption. This is infeasible because the complex text and visual information cannot be described well within one caption. To resolve this difficulty, we seek to generate multiple captions that accurately describe different parts of an image in detail. To achieve this purpose, there are three key challenges: 1) it is hard to decide which parts of the texts of images to copy or paraphrase; 2) it is non-trivial to capture the complex relationship between diverse texts in an image; 3) how to generate multiple captions with diverse content is still an open problem. To conquer these, we propose a novel Anchor-Captioner method. Specifically, we first find the important tokens which are supposed to be paid more attention to and consider them as anchors. Then, for each chosen anchor, we group its relevant texts to construct the corresponding anchor-centred graph (ACG). Last, based on different ACGs, we conduct multi-view caption generation to improve the content diversity of generated captions. Experimental results show that our method not only achieves SOTA performance but also generates diverse captions to describe images.
Contrastive Neural Architecture Search with Neural Architecture Comparators
Apr 06, 2021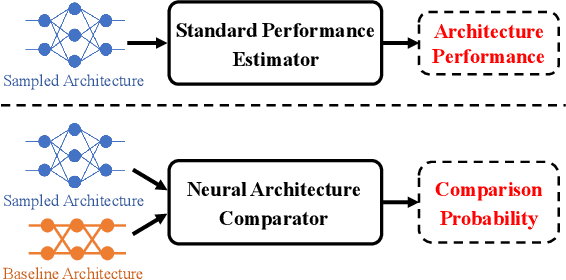
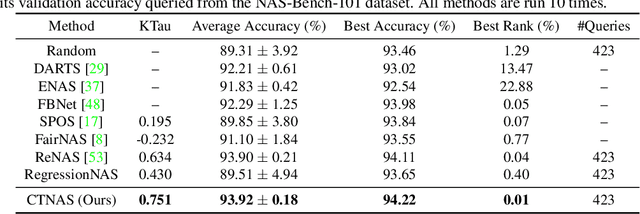
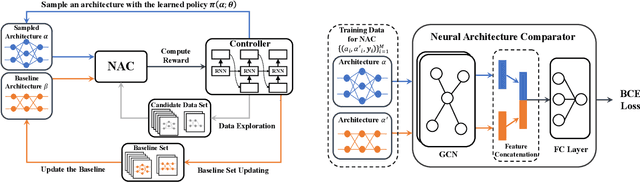
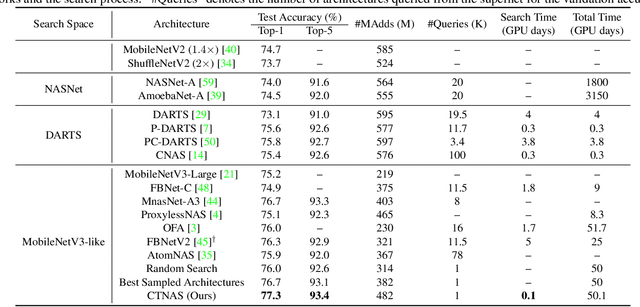
One of the key steps in Neural Architecture Search (NAS) is to estimate the performance of candidate architectures. Existing methods either directly use the validation performance or learn a predictor to estimate the performance. However, these methods can be either computationally expensive or very inaccurate, which may severely affect the search efficiency and performance. Moreover, as it is very difficult to annotate architectures with accurate performance on specific tasks, learning a promising performance predictor is often non-trivial due to the lack of labeled data. In this paper, we argue that it may not be necessary to estimate the absolute performance for NAS. On the contrary, we may need only to understand whether an architecture is better than a baseline one. However, how to exploit this comparison information as the reward and how to well use the limited labeled data remains two great challenges. In this paper, we propose a novel Contrastive Neural Architecture Search (CTNAS) method which performs architecture search by taking the comparison results between architectures as the reward. Specifically, we design and learn a Neural Architecture Comparator (NAC) to compute the probability of candidate architectures being better than a baseline one. Moreover, we present a baseline updating scheme to improve the baseline iteratively in a curriculum learning manner. More critically, we theoretically show that learning NAC is equivalent to optimizing the ranking over architectures. Extensive experiments in three search spaces demonstrate the superiority of our CTNAS over existing methods.
Internal Wasserstein Distance for Adversarial Attack and Defense
Mar 13, 2021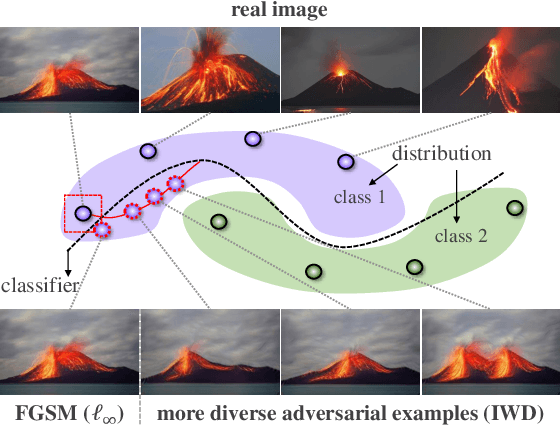
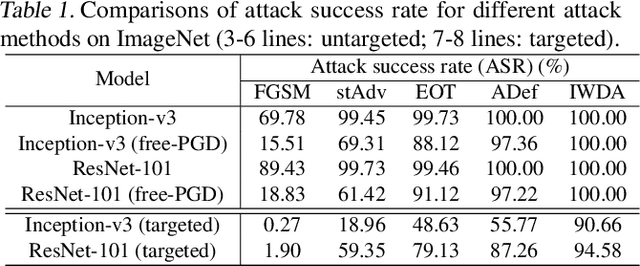
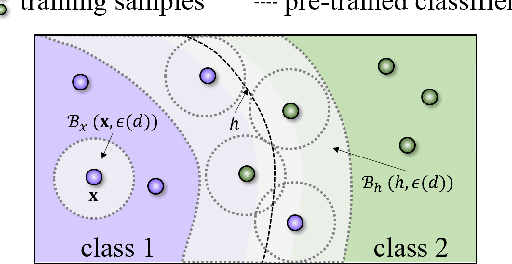
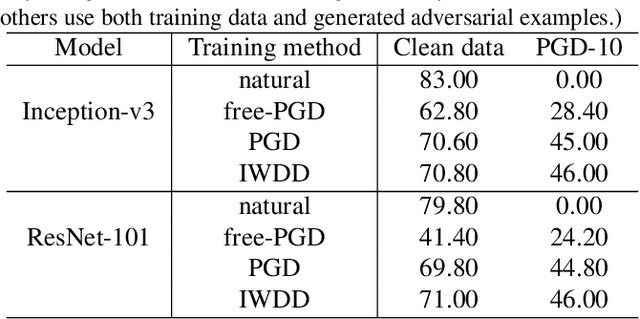
Deep neural networks (DNNs) are vulnerable to adversarial examples that can trigger misclassification of DNNs but may be imperceptible to human perception. Adversarial attack has been an important way to evaluate the robustness of DNNs. Existing attack methods on the construction of adversarial examples use such $\ell_p$ distance as a similarity metric to perturb samples. However, this kind of metric is incompatible with the underlying real-world image formation and human visual perception. In this paper, we first propose an internal Wasserstein distance (IWD) to measure image similarity between a sample and its adversarial example. We apply IWD to perform adversarial attack and defense. Specifically, we develop a novel attack method by capturing the distribution of patches in original samples. In this case, our approach is able to generate semantically similar but diverse adversarial examples that are more difficult to defend by existing defense methods. Relying on IWD, we also build a new defense method that seeks to learn robust models to defend against unseen adversarial examples. We provide both thorough theoretical and empirical evidence to support our methods.
Learning Defense Transformers for Counterattacking Adversarial Examples
Mar 13, 2021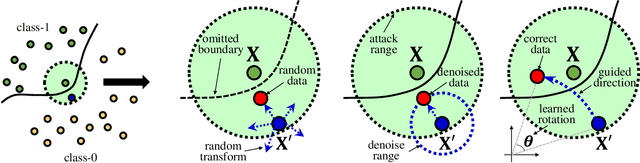
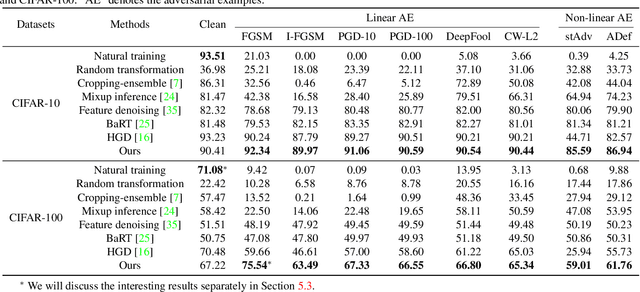
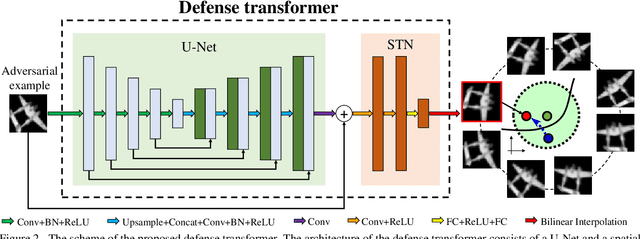
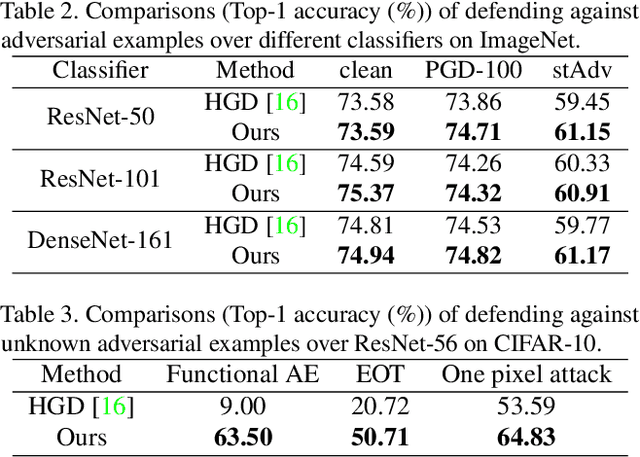
Deep neural networks (DNNs) are vulnerable to adversarial examples with small perturbations. Adversarial defense thus has been an important means which improves the robustness of DNNs by defending against adversarial examples. Existing defense methods focus on some specific types of adversarial examples and may fail to defend well in real-world applications. In practice, we may face many types of attacks where the exact type of adversarial examples in real-world applications can be even unknown. In this paper, motivated by that adversarial examples are more likely to appear near the classification boundary, we study adversarial examples from a new perspective that whether we can defend against adversarial examples by pulling them back to the original clean distribution. We theoretically and empirically verify the existence of defense affine transformations that restore adversarial examples. Relying on this, we learn a defense transformer to counterattack the adversarial examples by parameterizing the affine transformations and exploiting the boundary information of DNNs. Extensive experiments on both toy and real-world datasets demonstrate the effectiveness and generalization of our defense transformer.
Pareto-Frontier-aware Neural Architecture Generation for Diverse Budgets
Feb 27, 2021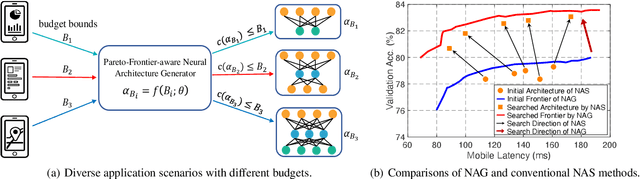
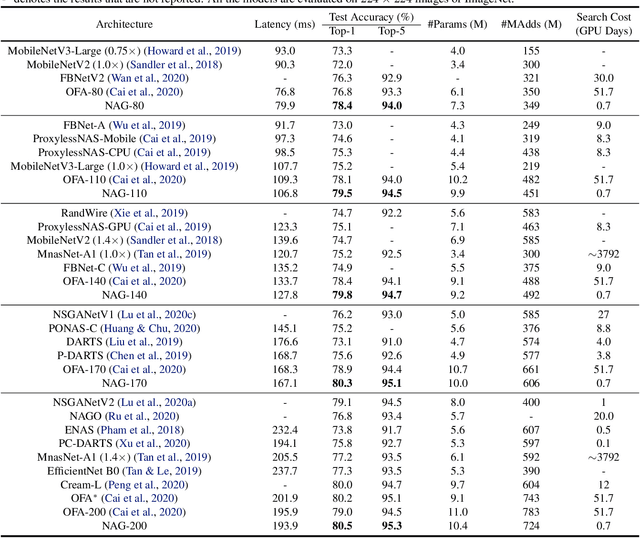
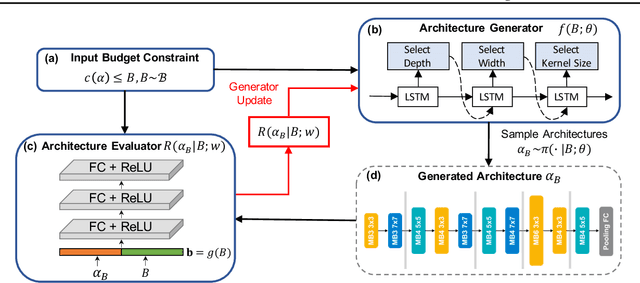

Designing feasible and effective architectures under diverse computation budgets incurred by different applications/devices is essential for deploying deep models in practice. Existing methods often perform an independent architecture search for each target budget, which is very inefficient yet unnecessary. Moreover, the repeated independent search manner would inevitably ignore the common knowledge among different search processes and hamper the search performance. To address these issues, we seek to train a general architecture generator that automatically produces effective architectures for an arbitrary budget merely via model inference. To this end, we propose a Pareto-Frontier-aware Neural Architecture Generator (NAG) which takes an arbitrary budget as input and produces the Pareto optimal architecture for the target budget. We train NAG by learning the Pareto frontier (i.e., the set of Pareto optimal architectures) over model performance and computational cost (e.g., latency). Extensive experiments on three platforms (i.e., mobile, CPU, and GPU) show the superiority of the proposed method over existing NAS methods.
Towards Accurate and Compact Architectures via Neural Architecture Transformer
Feb 20, 2021
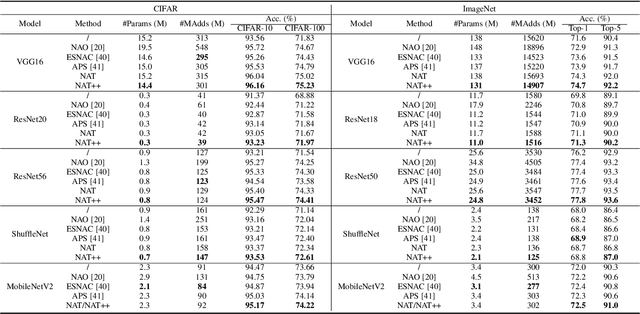
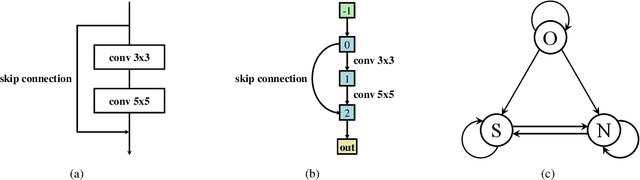
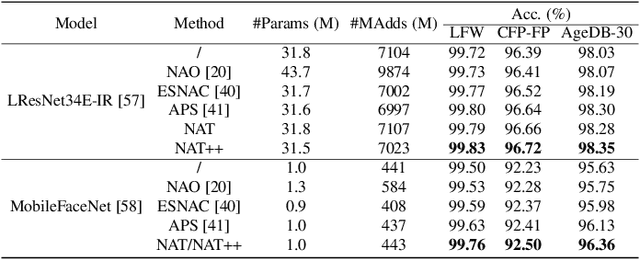
Designing effective architectures is one of the key factors behind the success of deep neural networks. Existing deep architectures are either manually designed or automatically searched by some Neural Architecture Search (NAS) methods. However, even a well-designed/searched architecture may still contain many nonsignificant or redundant modules/operations. Thus, it is necessary to optimize the operations inside an architecture to improve the performance without introducing extra computational cost. To this end, we have proposed a Neural Architecture Transformer (NAT) method which casts the optimization problem into a Markov Decision Process (MDP) and seeks to replace the redundant operations with more efficient operations, such as skip or null connection. Note that NAT only considers a small number of possible transitions and thus comes with a limited search/transition space. As a result, such a small search space may hamper the performance of architecture optimization. To address this issue, we propose a Neural Architecture Transformer++ (NAT++) method which further enlarges the set of candidate transitions to improve the performance of architecture optimization. Specifically, we present a two-level transition rule to obtain valid transitions, i.e., allowing operations to have more efficient types (e.g., convolution->separable convolution) or smaller kernel sizes (e.g., 5x5->3x3). Note that different operations may have different valid transitions. We further propose a Binary-Masked Softmax (BMSoftmax) layer to omit the possible invalid transitions. Extensive experiments on several benchmark datasets show that the transformed architecture significantly outperforms both its original counterpart and the architectures optimized by existing methods.
LBS: Loss-aware Bit Sharing for Automatic Model Compression
Feb 15, 2021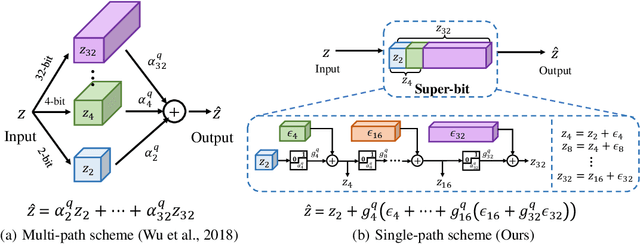
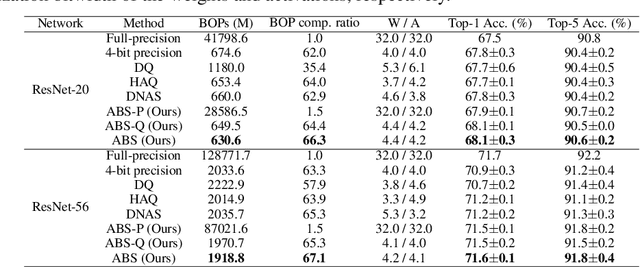
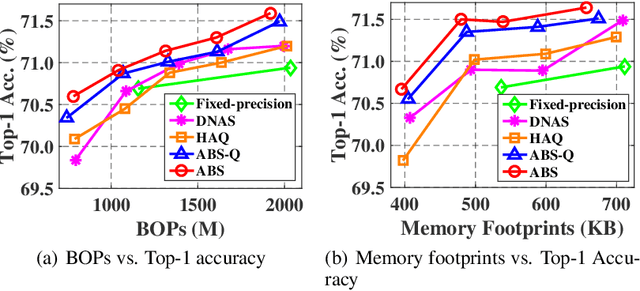
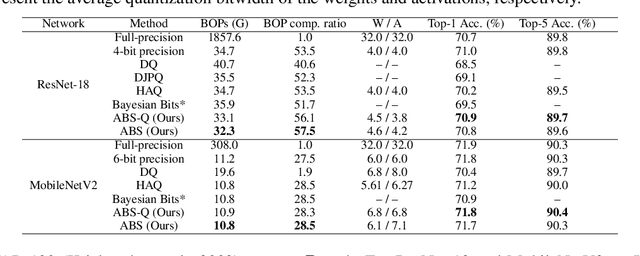
Low-bitwidth model compression is an effective method to reduce the model size and computational overhead. Existing compression methods rely on some compression configurations (such as pruning rates, and/or bitwidths), which are often determined manually and not optimal. Some attempts have been made to search them automatically, but the optimization process is often very expensive. To alleviate this, we devise a simple yet effective method named Loss-aware Bit Sharing (LBS) to automatically search for optimal model compression configurations. To this end, we propose a novel single-path model to encode all candidate compression configurations, where a high bitwidth quantized value can be decomposed into the sum of the lowest bitwidth quantized value and a series of re-assignment offsets. We then introduce learnable binary gates to encode the choice of bitwidth, including filter-wise 0-bit for filter pruning. By jointly training the binary gates in conjunction with network parameters, the compression configurations of each layer can be automatically determined. Extensive experiments on both CIFAR-100 and ImageNet show that LBS is able to significantly reduce computational cost while preserving promising performance.
Deep View Synthesis via Self-Consistent Generative Network
Jan 19, 2021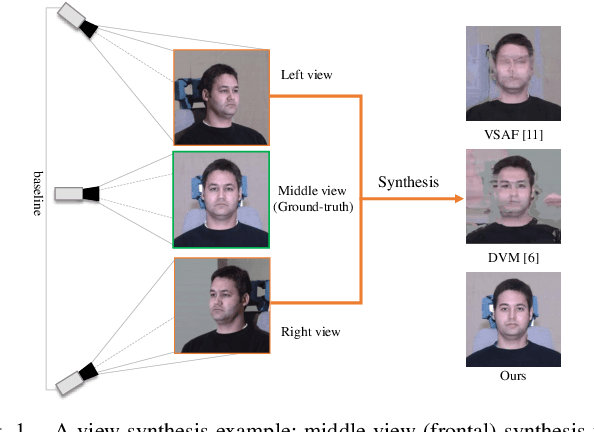



View synthesis aims to produce unseen views from a set of views captured by two or more cameras at different positions. This task is non-trivial since it is hard to conduct pixel-level matching among different views. To address this issue, most existing methods seek to exploit the geometric information to match pixels. However, when the distinct cameras have a large baseline (i.e., far away from each other), severe geometry distortion issues would occur and the geometric information may fail to provide useful guidance, resulting in very blurry synthesized images. To address the above issues, in this paper, we propose a novel deep generative model, called Self-Consistent Generative Network (SCGN), which synthesizes novel views from the given input views without explicitly exploiting the geometric information. The proposed SCGN model consists of two main components, i.e., a View Synthesis Network (VSN) and a View Decomposition Network (VDN), both employing an Encoder-Decoder structure. Here, the VDN seeks to reconstruct input views from the synthesized novel view to preserve the consistency of view synthesis. Thanks to VDN, SCGN is able to synthesize novel views without using any geometric rectification before encoding, making it easier for both training and applications. Finally, adversarial loss is introduced to improve the photo-realism of novel views. Both qualitative and quantitative comparisons against several state-of-the-art methods on two benchmark tasks demonstrated the superiority of our approach.