 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHoliGS: Holistic Gaussian Splatting for Embodied View Synthesis
Jun 24, 2025We propose HoliGS, a novel deformable Gaussian splatting framework that addresses embodied view synthesis from long monocular RGB videos. Unlike prior 4D Gaussian splatting and dynamic NeRF pipelines, which struggle with training overhead in minute-long captures, our method leverages invertible Gaussian Splatting deformation networks to reconstruct large-scale, dynamic environments accurately. Specifically, we decompose each scene into a static background plus time-varying objects, each represented by learned Gaussian primitives undergoing global rigid transformations, skeleton-driven articulation, and subtle non-rigid deformations via an invertible neural flow. This hierarchical warping strategy enables robust free-viewpoint novel-view rendering from various embodied camera trajectories by attaching Gaussians to a complete canonical foreground shape (\eg, egocentric or third-person follow), which may involve substantial viewpoint changes and interactions between multiple actors. Our experiments demonstrate that \ourmethod~ achieves superior reconstruction quality on challenging datasets while significantly reducing both training and rendering time compared to state-of-the-art monocular deformable NeRFs. These results highlight a practical and scalable solution for EVS in real-world scenarios. The source code will be released.
CoCo4D: Comprehensive and Complex 4D Scene Generation
Jun 24, 2025Existing 4D synthesis methods primarily focus on object-level generation or dynamic scene synthesis with limited novel views, restricting their ability to generate multi-view consistent and immersive dynamic 4D scenes. To address these constraints, we propose a framework (dubbed as CoCo4D) for generating detailed dynamic 4D scenes from text prompts, with the option to include images. Our method leverages the crucial observation that articulated motion typically characterizes foreground objects, whereas background alterations are less pronounced. Consequently, CoCo4D divides 4D scene synthesis into two responsibilities: modeling the dynamic foreground and creating the evolving background, both directed by a reference motion sequence. Given a text prompt and an optional reference image, CoCo4D first generates an initial motion sequence utilizing video diffusion models. This motion sequence then guides the synthesis of both the dynamic foreground object and the background using a novel progressive outpainting scheme. To ensure seamless integration of the moving foreground object within the dynamic background, CoCo4D optimizes a parametric trajectory for the foreground, resulting in realistic and coherent blending. Extensive experiments show that CoCo4D achieves comparable or superior performance in 4D scene generation compared to existing methods, demonstrating its effectiveness and efficiency. More results are presented on our website https://colezwhy.github.io/coco4d/.
Dynamic Context-oriented Decomposition for Task-aware Low-rank Adaptation with Less Forgetting and Faster Convergence
Jun 16, 2025



Conventional low-rank adaptation methods build adapters without considering data context, leading to sub-optimal fine-tuning performance and severe forgetting of inherent world knowledge. In this paper, we propose context-oriented decomposition adaptation (CorDA), a novel method that initializes adapters in a task-aware manner. Concretely, we develop context-oriented singular value decomposition, where we collect covariance matrices of input activations for each linear layer using sampled data from the target task, and apply SVD to the product of weight matrix and its corresponding covariance matrix. By doing so, the task-specific capability is compacted into the principal components. Thanks to the task awareness, our method enables two optional adaptation modes, knowledge-preserved mode (KPM) and instruction-previewed mode (IPM), providing flexibility to choose between freezing the principal components to preserve their associated knowledge or adapting them to better learn a new task. We further develop CorDA++ by deriving a metric that reflects the compactness of task-specific principal components, and then introducing dynamic covariance selection and dynamic rank allocation strategies based on the same metric. The two strategies provide each layer with the most representative covariance matrix and a proper rank allocation. Experimental results show that CorDA++ outperforms CorDA by a significant margin. CorDA++ in KPM not only achieves better fine-tuning performance than LoRA, but also mitigates the forgetting of pre-trained knowledge in both large language models and vision language models. For IPM, our method exhibits faster convergence, \emph{e.g.,} 4.5x speedup over QLoRA, and improves adaptation performance in various scenarios, outperforming strong baseline methods. Our method has been integrated into the PEFT library developed by Hugging Face.
InstaInpaint: Instant 3D-Scene Inpainting with Masked Large Reconstruction Model
Jun 12, 2025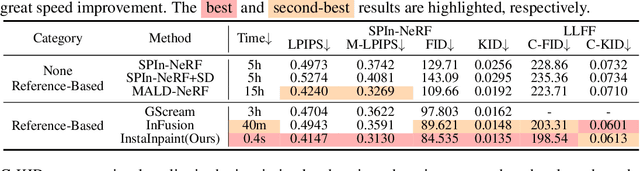


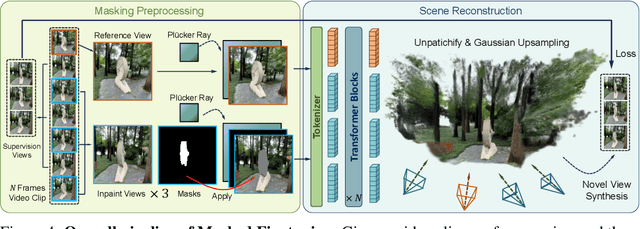
Recent advances in 3D scene reconstruction enable real-time viewing in virtual and augmented reality. To support interactive operations for better immersiveness, such as moving or editing objects, 3D scene inpainting methods are proposed to repair or complete the altered geometry. However, current approaches rely on lengthy and computationally intensive optimization, making them impractical for real-time or online applications. We propose InstaInpaint, a reference-based feed-forward framework that produces 3D-scene inpainting from a 2D inpainting proposal within 0.4 seconds. We develop a self-supervised masked-finetuning strategy to enable training of our custom large reconstruction model (LRM) on the large-scale dataset. Through extensive experiments, we analyze and identify several key designs that improve generalization, textural consistency, and geometric correctness. InstaInpaint achieves a 1000x speed-up from prior methods while maintaining a state-of-the-art performance across two standard benchmarks. Moreover, we show that InstaInpaint generalizes well to flexible downstream applications such as object insertion and multi-region inpainting. More video results are available at our project page: https://dhmbb2.github.io/InstaInpaint_page/.
DGS-LRM: Real-Time Deformable 3D Gaussian Reconstruction From Monocular Videos
Jun 11, 2025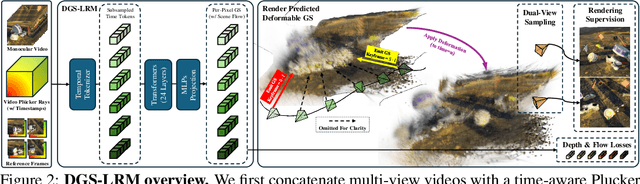
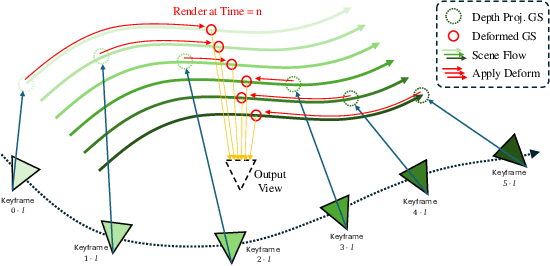
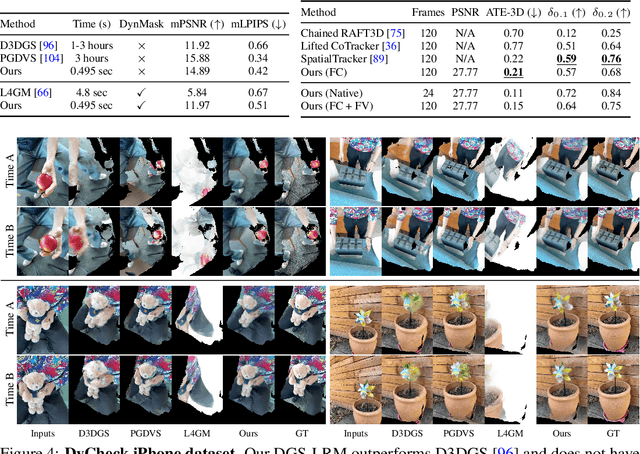

We introduce the Deformable Gaussian Splats Large Reconstruction Model (DGS-LRM), the first feed-forward method predicting deformable 3D Gaussian splats from a monocular posed video of any dynamic scene. Feed-forward scene reconstruction has gained significant attention for its ability to rapidly create digital replicas of real-world environments. However, most existing models are limited to static scenes and fail to reconstruct the motion of moving objects. Developing a feed-forward model for dynamic scene reconstruction poses significant challenges, including the scarcity of training data and the need for appropriate 3D representations and training paradigms. To address these challenges, we introduce several key technical contributions: an enhanced large-scale synthetic dataset with ground-truth multi-view videos and dense 3D scene flow supervision; a per-pixel deformable 3D Gaussian representation that is easy to learn, supports high-quality dynamic view synthesis, and enables long-range 3D tracking; and a large transformer network that achieves real-time, generalizable dynamic scene reconstruction. Extensive qualitative and quantitative experiments demonstrate that DGS-LRM achieves dynamic scene reconstruction quality comparable to optimization-based methods, while significantly outperforming the state-of-the-art predictive dynamic reconstruction method on real-world examples. Its predicted physically grounded 3D deformation is accurate and can readily adapt for long-range 3D tracking tasks, achieving performance on par with state-of-the-art monocular video 3D tracking methods.
RAPID Hand: A Robust, Affordable, Perception-Integrated, Dexterous Manipulation Platform for Generalist Robot Autonomy
Jun 09, 2025
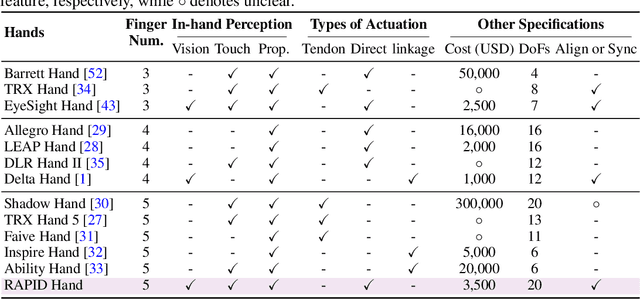


This paper addresses the scarcity of low-cost but high-dexterity platforms for collecting real-world multi-fingered robot manipulation data towards generalist robot autonomy. To achieve it, we propose the RAPID Hand, a co-optimized hardware and software platform where the compact 20-DoF hand, robust whole-hand perception, and high-DoF teleoperation interface are jointly designed. Specifically, RAPID Hand adopts a compact and practical hand ontology and a hardware-level perception framework that stably integrates wrist-mounted vision, fingertip tactile sensing, and proprioception with sub-7 ms latency and spatial alignment. Collecting high-quality demonstrations on high-DoF hands is challenging, as existing teleoperation methods struggle with precision and stability on complex multi-fingered systems. We address this by co-optimizing hand design, perception integration, and teleoperation interface through a universal actuation scheme, custom perception electronics, and two retargeting constraints. We evaluate the platform's hardware, perception, and teleoperation interface. Training a diffusion policy on collected data shows superior performance over prior works, validating the system's capability for reliable, high-quality data collection. The platform is constructed from low-cost and off-the-shelf components and will be made public to ensure reproducibility and ease of adoption.
VideoMathQA: Benchmarking Mathematical Reasoning via Multimodal Understanding in Videos
Jun 05, 2025



Mathematical reasoning in real-world video settings presents a fundamentally different challenge than in static images or text. It requires interpreting fine-grained visual information, accurately reading handwritten or digital text, and integrating spoken cues, often dispersed non-linearly over time. In such multimodal contexts, success hinges not just on perception, but on selectively identifying and integrating the right contextual details from a rich and noisy stream of content. To this end, we introduce VideoMathQA, a benchmark designed to evaluate whether models can perform such temporally extended cross-modal reasoning on videos. The benchmark spans 10 diverse mathematical domains, covering videos ranging from 10 seconds to over 1 hour. It requires models to interpret structured visual content, understand instructional narratives, and jointly ground concepts across visual, audio, and textual modalities. We employ graduate-level experts to ensure high quality, totaling over $920$ man-hours of annotation. To reflect real-world scenarios, questions are designed around three core reasoning challenges: direct problem solving, where answers are grounded in the presented question; conceptual transfer, which requires applying learned methods to new problems; and deep instructional comprehension, involving multi-step reasoning over extended explanations and partially worked-out solutions. Each question includes multi-step reasoning annotations, enabling fine-grained diagnosis of model capabilities. Through this benchmark, we highlight the limitations of existing approaches and establish a systematic evaluation framework for models that must reason, rather than merely perceive, across temporally extended and modality-rich mathematical problem settings. Our benchmark and evaluation code are available at: https://mbzuai-oryx.github.io/VideoMathQA
Manifold-aware Representation Learning for Degradation-agnostic Image Restoration
May 24, 2025Image Restoration (IR) aims to recover high quality images from degraded inputs affected by various corruptions such as noise, blur, haze, rain, and low light conditions. Despite recent advances, most existing approaches treat IR as a direct mapping problem, relying on shared representations across degradation types without modeling their structural diversity. In this work, we present MIRAGE, a unified and lightweight framework for all in one IR that explicitly decomposes the input feature space into three semantically aligned parallel branches, each processed by a specialized module attention for global context, convolution for local textures, and MLP for channel-wise statistics. This modular decomposition significantly improves generalization and efficiency across diverse degradations. Furthermore, we introduce a cross layer contrastive learning scheme that aligns shallow and latent features to enhance the discriminability of shared representations. To better capture the underlying geometry of feature representations, we perform contrastive learning in a Symmetric Positive Definite (SPD) manifold space rather than the conventional Euclidean space. Extensive experiments show that MIRAGE not only achieves new state of the art performance across a variety of degradation types but also offers a scalable solution for challenging all-in-one IR scenarios. Our code and models will be publicly available at https://amazingren.github.io/MIRAGE/.
Self-Supervised and Generalizable Tokenization for CLIP-Based 3D Understanding
May 24, 2025



Vision-language models like CLIP can offer a promising foundation for 3D scene understanding when extended with 3D tokenizers. However, standard approaches, such as k-nearest neighbor or radius-based tokenization, struggle with cross-domain generalization due to sensitivity to dataset-specific spatial scales. We present a universal 3D tokenizer designed for scale-invariant representation learning with a frozen CLIP backbone. We show that combining superpoint-based grouping with coordinate scale normalization consistently outperforms conventional methods through extensive experimental analysis. Specifically, we introduce S4Token, a tokenization pipeline that produces semantically-informed tokens regardless of scene scale. Our tokenizer is trained without annotations using masked point modeling and clustering-based objectives, along with cross-modal distillation to align 3D tokens with 2D multi-view image features. For dense prediction tasks, we propose a superpoint-level feature propagation module to recover point-level detail from sparse tokens.
KRIS-Bench: Benchmarking Next-Level Intelligent Image Editing Models
May 22, 2025Recent advances in multi-modal generative models have enabled significant progress in instruction-based image editing. However, while these models produce visually plausible outputs, their capacity for knowledge-based reasoning editing tasks remains under-explored. In this paper, we introduce KRIS-Bench (Knowledge-based Reasoning in Image-editing Systems Benchmark), a diagnostic benchmark designed to assess models through a cognitively informed lens. Drawing from educational theory, KRIS-Bench categorizes editing tasks across three foundational knowledge types: Factual, Conceptual, and Procedural. Based on this taxonomy, we design 22 representative tasks spanning 7 reasoning dimensions and release 1,267 high-quality annotated editing instances. To support fine-grained evaluation, we propose a comprehensive protocol that incorporates a novel Knowledge Plausibility metric, enhanced by knowledge hints and calibrated through human studies. Empirical results on 10 state-of-the-art models reveal significant gaps in reasoning performance, highlighting the need for knowledge-centric benchmarks to advance the development of intelligent image editing systems.