 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeE$^3$C: Video Generation with 3D Environmental Memory and Ego-Exo Human Pose Control
May 25, 2026Controllable and physically grounded egocentric video generation is essential for embodied agents to reason about how their own and others' actions manifest and change the world. Compared to generic video synthesis, egocentric generation is especially challenging: the camera is tightly coupled to the actor, leading to rapid viewpoint changes and frequent self-occlusions; the underlying actions are subtle, articulated, and often only partially visible; and both the people and the scene state must evolve consistently with the specified controls. We present E$^3$C, a controllable video diffusion framework for egocentric generation that builds structured and compact conditions disentangling persistent scene structure from human-driven dynamics. From context frames, E$^3$C constructs a semi-dense point cloud-based 3D memory and augments each point with appearance descriptors from video-VAE features. Rendering this memory into target viewpoints produces conditioning aligned with the target frames. Human dynamics are modeled separately. The observed people in the scene are controlled by skeleton renderings (exo human control), while the camera wearer is specified by their 3D body joints and 6DoF wrist motion (ego human control). To preserve ego human control when the wearer's body parts are invisible, we introduce an ego motion encoder that produces persistent cross-attention tokens. Experiments on Nymeria show that E$^3$C improves visual fidelity, camera-motion accuracy, object consistency, and ego & exo human control over strong baselines, while also enabling intuitive scene editing.
Boxer: Robust Lifting of Open-World 2D Bounding Boxes to 3D
Apr 06, 2026Detecting and localizing objects in space is a fundamental computer vision problem. While much progress has been made to solve 2D object detection, 3D object localization is much less explored and far from solved, especially for open-world categories. To address this research challenge, we propose Boxer, an algorithm to estimate static 3D bounding boxes (3DBBs) from 2D open-vocabulary object detections, posed images and optional depth either represented as a sparse point cloud or dense depth. At its core is BoxerNet, a transformer-based network which lifts 2D bounding box (2DBB) proposals into 3D, followed by multi-view fusion and geometric filtering to produce globally consistent de-duplicated 3DBBs in metric world space. Boxer leverages the power of existing 2DBB detection algorithms (e.g. DETIC, OWLv2, SAM3) to localize objects in 2D. This allows the main BoxerNet model to focus on lifting to 3D rather than detecting, ultimately reducing the demand for costly annotated 3DBB training data. Extending the CuTR formulation, we incorporate an aleatoric uncertainty for robust regression, a median depth patch encoding to support sparse depth inputs, and large-scale training with over 1.2 million unique 3DBBs. BoxerNet outperforms state-of-the-art baselines in open-world 3DBB lifting, including CuTR in egocentric settings without dense depth (0.532 vs. 0.010 mAP) and on CA-1M with dense depth available (0.412 vs. 0.250 mAP).
NymeriaPlus: Enriching Nymeria Dataset with Additional Annotations and Data
Mar 19, 2026The Nymeria Dataset, released in 2024, is a large-scale collection of in-the-wild human activities captured with multiple egocentric wearable devices that are spatially localized and temporally synchronized. It provides body-motion ground truth recorded with a motion-capture suit, device trajectories, semi-dense 3D point clouds, and in-context narrations. In this paper, we upgrade Nymeria and introduce NymeriaPlus. NymeriaPlus features: (1) improved human motion in Momentum Human Rig (MHR) and SMPL formats; (2) dense 3D and 2D bounding box annotations for indoor objects and structural elements; (3) instance-level 3D object reconstructions; and (4) additional modalities e.g., basemap recordings, audio, and wristband videos. By consolidating these complementary modalities and annotations into a single, coherent benchmark, NymeriaPlus strengthens Nymeria into a more powerful in-the-wild egocentric dataset. We expect NymeriaPlus to bridge a key gap in existing egocentric resources and to support a broader range of research, including unique explorations of multimodal learning for embodied AI.
ShapeR: Robust Conditional 3D Shape Generation from Casual Captures
Jan 16, 2026Recent advances in 3D shape generation have achieved impressive results, but most existing methods rely on clean, unoccluded, and well-segmented inputs. Such conditions are rarely met in real-world scenarios. We present ShapeR, a novel approach for conditional 3D object shape generation from casually captured sequences. Given an image sequence, we leverage off-the-shelf visual-inertial SLAM, 3D detection algorithms, and vision-language models to extract, for each object, a set of sparse SLAM points, posed multi-view images, and machine-generated captions. A rectified flow transformer trained to effectively condition on these modalities then generates high-fidelity metric 3D shapes. To ensure robustness to the challenges of casually captured data, we employ a range of techniques including on-the-fly compositional augmentations, a curriculum training scheme spanning object- and scene-level datasets, and strategies to handle background clutter. Additionally, we introduce a new evaluation benchmark comprising 178 in-the-wild objects across 7 real-world scenes with geometry annotations. Experiments show that ShapeR significantly outperforms existing approaches in this challenging setting, achieving an improvement of 2.7x in Chamfer distance compared to state of the art.
DGS-LRM: Real-Time Deformable 3D Gaussian Reconstruction From Monocular Videos
Jun 11, 2025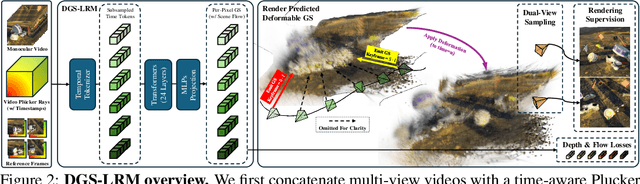
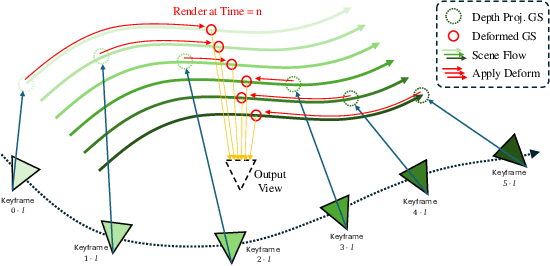
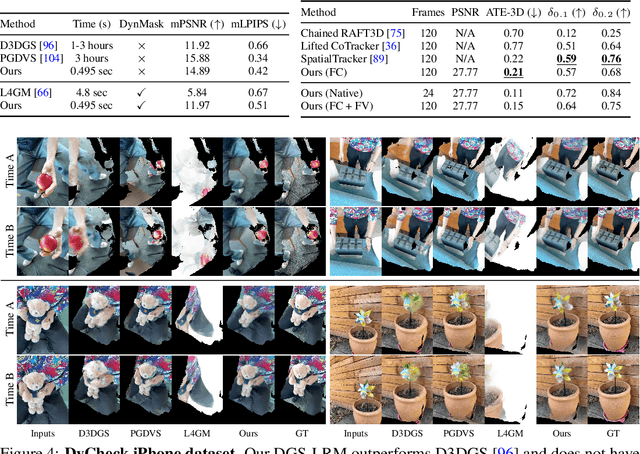

We introduce the Deformable Gaussian Splats Large Reconstruction Model (DGS-LRM), the first feed-forward method predicting deformable 3D Gaussian splats from a monocular posed video of any dynamic scene. Feed-forward scene reconstruction has gained significant attention for its ability to rapidly create digital replicas of real-world environments. However, most existing models are limited to static scenes and fail to reconstruct the motion of moving objects. Developing a feed-forward model for dynamic scene reconstruction poses significant challenges, including the scarcity of training data and the need for appropriate 3D representations and training paradigms. To address these challenges, we introduce several key technical contributions: an enhanced large-scale synthetic dataset with ground-truth multi-view videos and dense 3D scene flow supervision; a per-pixel deformable 3D Gaussian representation that is easy to learn, supports high-quality dynamic view synthesis, and enables long-range 3D tracking; and a large transformer network that achieves real-time, generalizable dynamic scene reconstruction. Extensive qualitative and quantitative experiments demonstrate that DGS-LRM achieves dynamic scene reconstruction quality comparable to optimization-based methods, while significantly outperforming the state-of-the-art predictive dynamic reconstruction method on real-world examples. Its predicted physically grounded 3D deformation is accurate and can readily adapt for long-range 3D tracking tasks, achieving performance on par with state-of-the-art monocular video 3D tracking methods.
Sonata: Self-Supervised Learning of Reliable Point Representations
Mar 20, 2025In this paper, we question whether we have a reliable self-supervised point cloud model that can be used for diverse 3D tasks via simple linear probing, even with limited data and minimal computation. We find that existing 3D self-supervised learning approaches fall short when evaluated on representation quality through linear probing. We hypothesize that this is due to what we term the "geometric shortcut", which causes representations to collapse to low-level spatial features. This challenge is unique to 3D and arises from the sparse nature of point cloud data. We address it through two key strategies: obscuring spatial information and enhancing the reliance on input features, ultimately composing a Sonata of 140k point clouds through self-distillation. Sonata is simple and intuitive, yet its learned representations are strong and reliable: zero-shot visualizations demonstrate semantic grouping, alongside strong spatial reasoning through nearest-neighbor relationships. Sonata demonstrates exceptional parameter and data efficiency, tripling linear probing accuracy (from 21.8% to 72.5%) on ScanNet and nearly doubling performance with only 1% of the data compared to previous approaches. Full fine-tuning further advances SOTA across both 3D indoor and outdoor perception tasks.
Human-in-the-Loop Local Corrections of 3D Scene Layouts via Infilling
Mar 14, 2025We present a novel human-in-the-loop approach to estimate 3D scene layout that uses human feedback from an egocentric standpoint. We study this approach through introduction of a novel local correction task, where users identify local errors and prompt a model to automatically correct them. Building on SceneScript, a state-of-the-art framework for 3D scene layout estimation that leverages structured language, we propose a solution that structures this problem as "infilling", a task studied in natural language processing. We train a multi-task version of SceneScript that maintains performance on global predictions while significantly improving its local correction ability. We integrate this into a human-in-the-loop system, enabling a user to iteratively refine scene layout estimates via a low-friction "one-click fix'' workflow. Our system enables the final refined layout to diverge from the training distribution, allowing for more accurate modelling of complex layouts.
EFM3D: A Benchmark for Measuring Progress Towards 3D Egocentric Foundation Models
Jun 14, 2024



The advent of wearable computers enables a new source of context for AI that is embedded in egocentric sensor data. This new egocentric data comes equipped with fine-grained 3D location information and thus presents the opportunity for a novel class of spatial foundation models that are rooted in 3D space. To measure progress on what we term Egocentric Foundation Models (EFMs) we establish EFM3D, a benchmark with two core 3D egocentric perception tasks. EFM3D is the first benchmark for 3D object detection and surface regression on high quality annotated egocentric data of Project Aria. We propose Egocentric Voxel Lifting (EVL), a baseline for 3D EFMs. EVL leverages all available egocentric modalities and inherits foundational capabilities from 2D foundation models. This model, trained on a large simulated dataset, outperforms existing methods on the EFM3D benchmark.
EgoLifter: Open-world 3D Segmentation for Egocentric Perception
Mar 26, 2024In this paper we present EgoLifter, a novel system that can automatically segment scenes captured from egocentric sensors into a complete decomposition of individual 3D objects. The system is specifically designed for egocentric data where scenes contain hundreds of objects captured from natural (non-scanning) motion. EgoLifter adopts 3D Gaussians as the underlying representation of 3D scenes and objects and uses segmentation masks from the Segment Anything Model (SAM) as weak supervision to learn flexible and promptable definitions of object instances free of any specific object taxonomy. To handle the challenge of dynamic objects in ego-centric videos, we design a transient prediction module that learns to filter out dynamic objects in the 3D reconstruction. The result is a fully automatic pipeline that is able to reconstruct 3D object instances as collections of 3D Gaussians that collectively compose the entire scene. We created a new benchmark on the Aria Digital Twin dataset that quantitatively demonstrates its state-of-the-art performance in open-world 3D segmentation from natural egocentric input. We run EgoLifter on various egocentric activity datasets which shows the promise of the method for 3D egocentric perception at scale.
Pixel-Aligned Recurrent Queries for Multi-View 3D Object Detection
Oct 02, 2023



We present PARQ - a multi-view 3D object detector with transformer and pixel-aligned recurrent queries. Unlike previous works that use learnable features or only encode 3D point positions as queries in the decoder, PARQ leverages appearance-enhanced queries initialized from reference points in 3D space and updates their 3D location with recurrent cross-attention operations. Incorporating pixel-aligned features and cross attention enables the model to encode the necessary 3D-to-2D correspondences and capture global contextual information of the input images. PARQ outperforms prior best methods on the ScanNet and ARKitScenes datasets, learns and detects faster, is more robust to distribution shifts in reference points, can leverage additional input views without retraining, and can adapt inference compute by changing the number of recurrent iterations.