 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFisher-Preserving Guidance: Training-Free Manifold Constraints for Safe Diffusion Control
May 28, 2026Diffusion models are effective for waypoint prediction in visual navigation, but standard sampling and test time guidance can produce unreliable or inefficient trajectories when updates drift off the training manifold. We propose Fisher Preserving Guidance with Outer Product Span Projection, a training-free inference method that avoids large Fisher drift associated with off-distribution actions while optimizing a task objective. Our method computes the Fisher-preserving update via a low-rank Jacobian factorization, requiring only a single backward pass per step and enabling real-time use. We further introduce Truncated Fisher Denoising Sensitivity as an uncertainty signal and use it for robust multi-sample action blending. Experiments on toy and realistic navigation benchmarks, including Maze2D with TSDF-based guidance, PushT with official Diffusion Policy weights, and visual navigation in simulation and on real robots, demonstrate consistent improvements in performance over strong diffusion-policy baselines without additional training.
Learning Reference-Guided Exposure Correction with Hybrid Illumination Characteristics
May 26, 2026We present HICNet, a reference-guided exposure correction framework. A lightweight, content-agnostic encoder distills each image into a compact illumination embedding capturing regional brightness, edge contrast, and higher-order luminance moments. The embedding difference between a source and its reference drives a multi-scale modulation network that combines FiLM-based global adjustment with Photometric Channel Rebalancing for fine-grained, illumination-aware spectral gating, producing exposure-matched outputs while faithfully preserving scene details. A cross-batch contrastive loss orders the illumination manifold, bolstering robustness to diverse lighting conditions. Trained without ground truth or intrinsic decomposition, HICNet attains better accuracy on public benchmarks and generalizes well to entirely unseen scenes.
STRNet: Visual Navigation with Spatio-Temporal Representation through Dynamic Graph Aggregation
Apr 03, 2026Visual navigation requires the robot to reach a specified goal such as an image, based on a sequence of first-person visual observations. While recent learning-based approaches have made significant progress, they often focus on improving policy heads or decision strategies while relying on simplistic feature encoders and temporal pooling to represent visual input. This leads to the loss of fine-grained spatial and temporal structure, ultimately limiting accurate action prediction and progress estimation. In this paper, we propose a unified spatio-temporal representation framework that enhances visual encoding for robotic navigation. Our approach extracts features from both image sequences and goal observations, and fuses them using the designed spatio-temporal fusion module. This module performs spatial graph reasoning within each frame and models temporal dynamics using a hybrid temporal shift module combined with multi-resolution difference-aware convolution. Experimental results demonstrate that our approach consistently improves navigation performance and offers a generalizable visual backbone for goal-conditioned control. Code is available at \href{https://github.com/hren20/STRNet}{https://github.com/hren20/STRNet}.
RAPID Hand: A Robust, Affordable, Perception-Integrated, Dexterous Manipulation Platform for Generalist Robot Autonomy
Jun 09, 2025
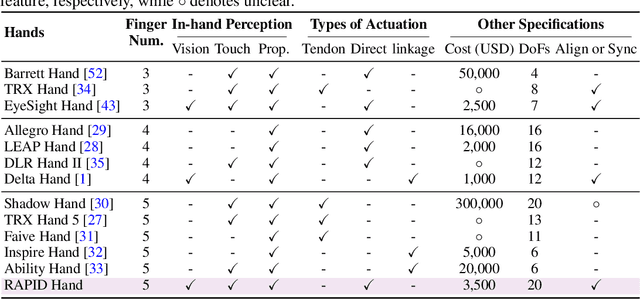


This paper addresses the scarcity of low-cost but high-dexterity platforms for collecting real-world multi-fingered robot manipulation data towards generalist robot autonomy. To achieve it, we propose the RAPID Hand, a co-optimized hardware and software platform where the compact 20-DoF hand, robust whole-hand perception, and high-DoF teleoperation interface are jointly designed. Specifically, RAPID Hand adopts a compact and practical hand ontology and a hardware-level perception framework that stably integrates wrist-mounted vision, fingertip tactile sensing, and proprioception with sub-7 ms latency and spatial alignment. Collecting high-quality demonstrations on high-DoF hands is challenging, as existing teleoperation methods struggle with precision and stability on complex multi-fingered systems. We address this by co-optimizing hand design, perception integration, and teleoperation interface through a universal actuation scheme, custom perception electronics, and two retargeting constraints. We evaluate the platform's hardware, perception, and teleoperation interface. Training a diffusion policy on collected data shows superior performance over prior works, validating the system's capability for reliable, high-quality data collection. The platform is constructed from low-cost and off-the-shelf components and will be made public to ensure reproducibility and ease of adoption.
Prior Does Matter: Visual Navigation via Denoising Diffusion Bridge Models
Apr 14, 2025Recent advancements in diffusion-based imitation learning, which show impressive performance in modeling multimodal distributions and training stability, have led to substantial progress in various robot learning tasks. In visual navigation, previous diffusion-based policies typically generate action sequences by initiating from denoising Gaussian noise. However, the target action distribution often diverges significantly from Gaussian noise, leading to redundant denoising steps and increased learning complexity. Additionally, the sparsity of effective action distributions makes it challenging for the policy to generate accurate actions without guidance. To address these issues, we propose a novel, unified visual navigation framework leveraging the denoising diffusion bridge models named NaviBridger. This approach enables action generation by initiating from any informative prior actions, enhancing guidance and efficiency in the denoising process. We explore how diffusion bridges can enhance imitation learning in visual navigation tasks and further examine three source policies for generating prior actions. Extensive experiments in both simulated and real-world indoor and outdoor scenarios demonstrate that NaviBridger accelerates policy inference and outperforms the baselines in generating target action sequences. Code is available at https://github.com/hren20/NaiviBridger.