 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDGS-LRM: Real-Time Deformable 3D Gaussian Reconstruction From Monocular Videos
Jun 11, 2025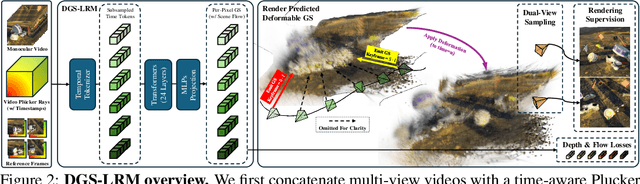
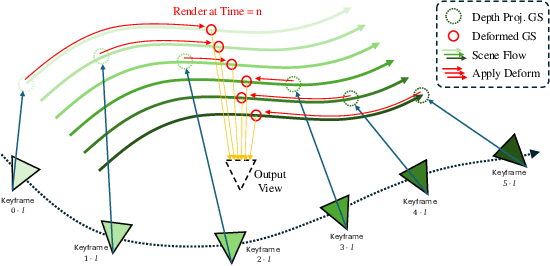
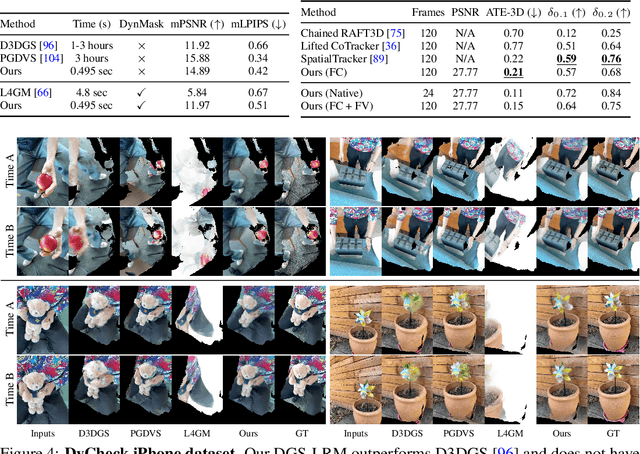

We introduce the Deformable Gaussian Splats Large Reconstruction Model (DGS-LRM), the first feed-forward method predicting deformable 3D Gaussian splats from a monocular posed video of any dynamic scene. Feed-forward scene reconstruction has gained significant attention for its ability to rapidly create digital replicas of real-world environments. However, most existing models are limited to static scenes and fail to reconstruct the motion of moving objects. Developing a feed-forward model for dynamic scene reconstruction poses significant challenges, including the scarcity of training data and the need for appropriate 3D representations and training paradigms. To address these challenges, we introduce several key technical contributions: an enhanced large-scale synthetic dataset with ground-truth multi-view videos and dense 3D scene flow supervision; a per-pixel deformable 3D Gaussian representation that is easy to learn, supports high-quality dynamic view synthesis, and enables long-range 3D tracking; and a large transformer network that achieves real-time, generalizable dynamic scene reconstruction. Extensive qualitative and quantitative experiments demonstrate that DGS-LRM achieves dynamic scene reconstruction quality comparable to optimization-based methods, while significantly outperforming the state-of-the-art predictive dynamic reconstruction method on real-world examples. Its predicted physically grounded 3D deformation is accurate and can readily adapt for long-range 3D tracking tasks, achieving performance on par with state-of-the-art monocular video 3D tracking methods.
Monocular Online Reconstruction with Enhanced Detail Preservation
May 14, 2025We propose an online 3D Gaussian-based dense mapping framework for photorealistic details reconstruction from a monocular image stream. Our approach addresses two key challenges in monocular online reconstruction: distributing Gaussians without relying on depth maps and ensuring both local and global consistency in the reconstructed maps. To achieve this, we introduce two key modules: the Hierarchical Gaussian Management Module for effective Gaussian distribution and the Global Consistency Optimization Module for maintaining alignment and coherence at all scales. In addition, we present the Multi-level Occupancy Hash Voxels (MOHV), a structure that regularizes Gaussians for capturing details across multiple levels of granularity. MOHV ensures accurate reconstruction of both fine and coarse geometries and textures, preserving intricate details while maintaining overall structural integrity. Compared to state-of-the-art RGB-only and even RGB-D methods, our framework achieves superior reconstruction quality with high computational efficiency. Moreover, it integrates seamlessly with various tracking systems, ensuring generality and scalability.
Decoupling Features and Coordinates for Few-shot RGB Relocalization
Nov 26, 2019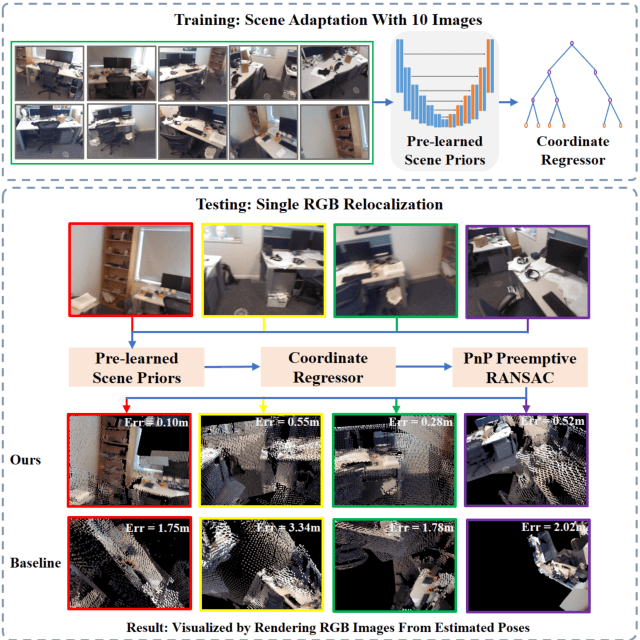
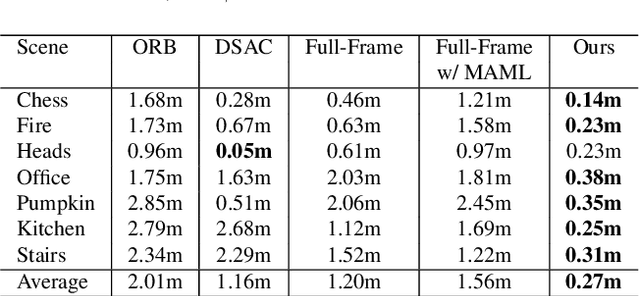
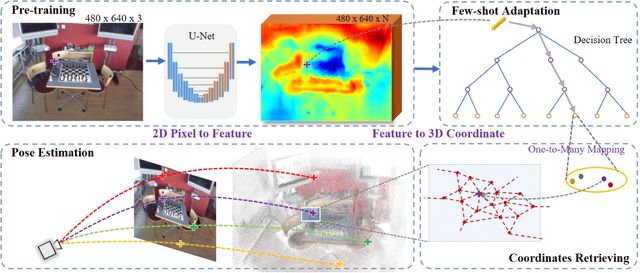
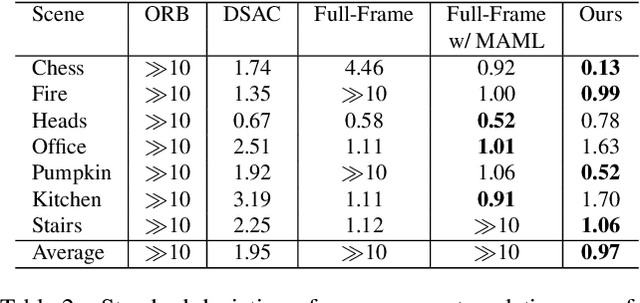
Cross-scene model adaption is a crucial feature for camera relocalization applied in real scenarios. It is preferable that a pre-learned model can be quickly deployed in a novel scene with as little training as possible. The existing state-of-the-art approaches, however, can hardly support few-shot scene adaption due to the entangling of image feature extraction and 3D coordinate regression, which requires a large-scale of training data. To address this issue, inspired by how humans relocalize, we approach camera relocalization with a decoupled solution where feature extraction, coordinate regression and pose estimation are performed separately. Our key insight is that robust and discriminative image features used for coordinate regression should be learned by removing the distracting factor of camera views, because coordinates in the world reference frame are obviously independent of local views. In particular, we employ a deep neural network to learn view-factorized pixel-wise features using several training scenes. Given a new scene, we train a view-dependent per-pixel 3D coordinate regressor while keeping the feature extractor fixed. Such a decoupled design allows us to adapt the entire model to novel scene and achieve accurate camera pose estimation with only few-shot training samples and two orders of magnitude less training time than the state-of-the-arts.