 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStep-Audio 2 Technical Report
Jul 24, 2025



This paper presents Step-Audio 2, an end-to-end multi-modal large language model designed for industry-strength audio understanding and speech conversation. By integrating a latent audio encoder and reasoning-centric reinforcement learning (RL), Step-Audio 2 achieves promising performance in automatic speech recognition (ASR) and audio understanding. To facilitate genuine end-to-end speech conversation, Step-Audio 2 incorporates the generation of discrete audio tokens into language modeling, significantly enhancing its responsiveness to paralinguistic information such as speaking styles and emotions. To effectively leverage the rich textual and acoustic knowledge in real-world data, Step-Audio 2 integrates retrieval-augmented generation (RAG) and is able to call external tools such as web search to mitigate hallucination and audio search to switch timbres. Trained on millions of hours of speech and audio data, Step-Audio 2 delivers intelligence and expressiveness across diverse conversational scenarios. Evaluation results demonstrate that Step-Audio 2 achieves state-of-the-art performance on various audio understanding and conversational benchmarks compared to other open-source and commercial solutions. Please visit https://github.com/stepfun-ai/Step-Audio2 for more information.
PyVision: Agentic Vision with Dynamic Tooling
Jul 10, 2025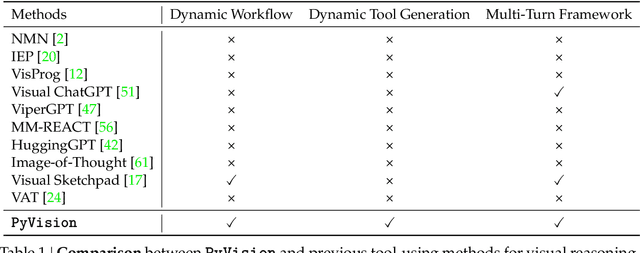
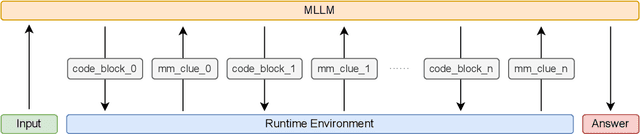
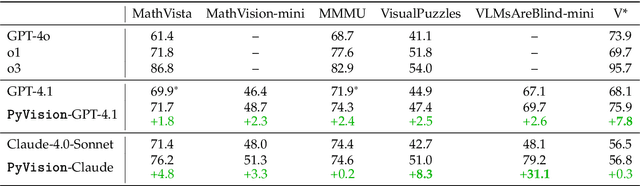
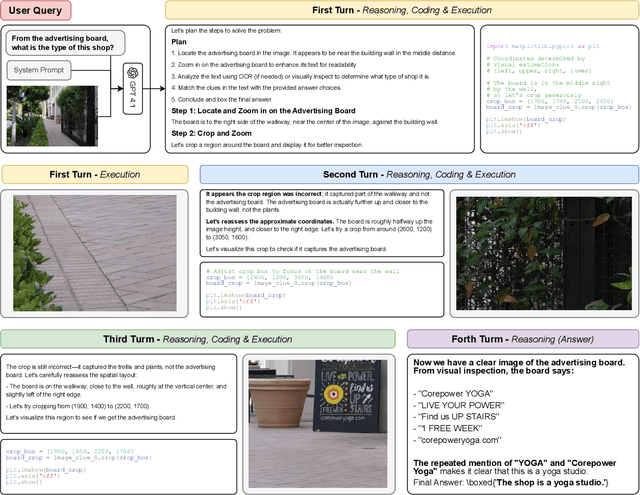
LLMs are increasingly deployed as agents, systems capable of planning, reasoning, and dynamically calling external tools. However, in visual reasoning, prior approaches largely remain limited by predefined workflows and static toolsets. In this report, we present PyVision, an interactive, multi-turn framework that enables MLLMs to autonomously generate, execute, and refine Python-based tools tailored to the task at hand, unlocking flexible and interpretable problem-solving. We develop a taxonomy of the tools created by PyVision and analyze their usage across a diverse set of benchmarks. Quantitatively, PyVision achieves consistent performance gains, boosting GPT-4.1 by +7.8% on V* and Claude-4.0-Sonnet by +31.1% on VLMsAreBlind-mini. These results point to a broader shift: dynamic tooling allows models not just to use tools, but to invent them, advancing toward more agentic visual reasoning.
Graph Learning for Cooperative Cell-Free ISAC Systems: From Optimization to Estimation
Jul 09, 2025Cell-free integrated sensing and communication (ISAC) systems have emerged as a promising paradigm for sixth-generation (6G) networks, enabling simultaneous high-rate data transmission and high-precision radar sensing through cooperative distributed access points (APs). Fully exploiting these capabilities requires a unified design that bridges system-level optimization with multi-target parameter estimation. This paper proposes an end-to-end graph learning approach to close this gap, modeling the entire cell-free ISAC network as a heterogeneous graph to jointly design the AP mode selection, user association, precoding, and echo signal processing for multi-target position and velocity estimation. In particular, we propose two novel heterogeneous graph learning frameworks: a dynamic graph learning framework and a lightweight mirror-based graph attention network (mirror-GAT) framework. The dynamic graph learning framework employs structural and temporal attention mechanisms integrated with a three-dimensional convolutional neural network (3D-CNN), enabling superior performance and robustness in cell-free ISAC environments. Conversely, the mirror-GAT framework significantly reduces computational complexity and signaling overhead through a bi-level iterative structure with share adjacency. Simulation results validate that both proposed graph-learning-based frameworks achieve significant improvements in multi-target position and velocity estimation accuracy compared to conventional heuristic and optimization-based designs. Particularly, the mirror-GAT framework demonstrates substantial reductions in computational time and signaling overhead, underscoring its suitability for practical deployments.
Robust Brain Tumor Segmentation with Incomplete MRI Modalities Using Hölder Divergence and Mutual Information-Enhanced Knowledge Transfer
Jul 02, 2025



Multimodal MRI provides critical complementary information for accurate brain tumor segmentation. However, conventional methods struggle when certain modalities are missing due to issues such as image quality, protocol inconsistencies, patient allergies, or financial constraints. To address this, we propose a robust single-modality parallel processing framework that achieves high segmentation accuracy even with incomplete modalities. Leveraging Holder divergence and mutual information, our model maintains modality-specific features while dynamically adjusting network parameters based on the available inputs. By using these divergence- and information-based loss functions, the framework effectively quantifies discrepancies between predictions and ground-truth labels, resulting in consistently accurate segmentation. Extensive evaluations on the BraTS 2018 and BraTS 2020 datasets demonstrate superior performance over existing methods in handling missing modalities.
Sekai: A Video Dataset towards World Exploration
Jun 18, 2025Video generation techniques have made remarkable progress, promising to be the foundation of interactive world exploration. However, existing video generation datasets are not well-suited for world exploration training as they suffer from some limitations: limited locations, short duration, static scenes, and a lack of annotations about exploration and the world. In this paper, we introduce Sekai (meaning ``world'' in Japanese), a high-quality first-person view worldwide video dataset with rich annotations for world exploration. It consists of over 5,000 hours of walking or drone view (FPV and UVA) videos from over 100 countries and regions across 750 cities. We develop an efficient and effective toolbox to collect, pre-process and annotate videos with location, scene, weather, crowd density, captions, and camera trajectories. Experiments demonstrate the quality of the dataset. And, we use a subset to train an interactive video world exploration model, named YUME (meaning ``dream'' in Japanese). We believe Sekai will benefit the area of video generation and world exploration, and motivate valuable applications.
ViCrit: A Verifiable Reinforcement Learning Proxy Task for Visual Perception in VLMs
Jun 11, 2025Reinforcement learning (RL) has shown great effectiveness for fine-tuning large language models (LLMs) using tasks that are challenging yet easily verifiable, such as math reasoning or code generation. However, extending this success to visual perception in vision-language models (VLMs) has been impeded by the scarcity of vision-centric tasks that are simultaneously challenging and unambiguously verifiable. To this end, we introduce ViCrit (Visual Caption Hallucination Critic), an RL proxy task that trains VLMs to localize a subtle, synthetic visual hallucination injected into paragraphs of human-written image captions. Starting from a 200-word captions, we inject a single, subtle visual description error-altering a few words on objects, attributes, counts, or spatial relations-and task the model to pinpoint the corrupted span given the image and the modified caption. This formulation preserves the full perceptual difficulty while providing a binary, exact-match reward that is easy to compute and unambiguous. Models trained with the ViCrit Task exhibit substantial gains across a variety of VL benchmarks. Crucially, the improvements transfer beyond natural-image training data to abstract image reasoning and visual math, showing promises of learning to perceive rather than barely memorizing seen objects. To facilitate evaluation, we further introduce ViCrit-Bench, a category-balanced diagnostic benchmark that systematically probes perception errors across diverse image domains and error types. Together, our results demonstrate that fine-grained hallucination criticism is an effective and generalizable objective for enhancing visual perception in VLMs.
Step-Audio-AQAA: a Fully End-to-End Expressive Large Audio Language Model
Jun 10, 2025



Large Audio-Language Models (LALMs) have significantly advanced intelligent human-computer interaction, yet their reliance on text-based outputs limits their ability to generate natural speech responses directly, hindering seamless audio interactions. To address this, we introduce Step-Audio-AQAA, a fully end-to-end LALM designed for Audio Query-Audio Answer (AQAA) tasks. The model integrates a dual-codebook audio tokenizer for linguistic and semantic feature extraction, a 130-billion-parameter backbone LLM and a neural vocoder for high-fidelity speech synthesis. Our post-training approach employs interleaved token-output of text and audio to enhance semantic coherence and combines Direct Preference Optimization (DPO) with model merge to improve performance. Evaluations on the StepEval-Audio-360 benchmark demonstrate that Step-Audio-AQAA excels especially in speech control, outperforming the state-of-art LALMs in key areas. This work contributes a promising solution for end-to-end LALMs and highlights the critical role of token-based vocoder in enhancing overall performance for AQAA tasks.
What makes Reasoning Models Different? Follow the Reasoning Leader for Efficient Decoding
Jun 08, 2025Large reasoning models (LRMs) achieve strong reasoning performance by emitting long chains of thought. Yet, these verbose traces slow down inference and often drift into unnecessary detail, known as the overthinking phenomenon. To better understand LRMs' behavior, we systematically analyze the token-level misalignment between reasoning and non-reasoning models. While it is expected that their primary difference lies in the stylistic "thinking cues", LRMs uniquely exhibit two pivotal, previously under-explored phenomena: a Global Misalignment Rebound, where their divergence from non-reasoning models persists or even grows as response length increases, and more critically, a Local Misalignment Diminish, where the misalignment concentrates at the "thinking cues" each sentence starts with but rapidly declines in the remaining of the sentence. Motivated by the Local Misalignment Diminish, we propose FoReaL-Decoding, a collaborative fast-slow thinking decoding method for cost-quality trade-off. In FoReaL-Decoding, a Leading model leads the first few tokens for each sentence, and then a weaker draft model completes the following tokens to the end of each sentence. FoReaL-Decoding adopts a stochastic gate to smoothly interpolate between the small and the large model. On four popular math-reasoning benchmarks (AIME24, GPQA-Diamond, MATH500, AMC23), FoReaL-Decoding reduces theoretical FLOPs by 30 to 50% and trims CoT length by up to 40%, while preserving 86 to 100% of model performance. These results establish FoReaL-Decoding as a simple, plug-and-play route to controllable cost-quality trade-offs in reasoning-centric tasks.
Diarization-Aware Multi-Speaker Automatic Speech Recognition via Large Language Models
Jun 06, 2025Multi-speaker automatic speech recognition (MS-ASR) faces significant challenges in transcribing overlapped speech, a task critical for applications like meeting transcription and conversational analysis. While serialized output training (SOT)-style methods serve as common solutions, they often discard absolute timing information, limiting their utility in time-sensitive scenarios. Leveraging recent advances in large language models (LLMs) for conversational audio processing, we propose a novel diarization-aware multi-speaker ASR system that integrates speaker diarization with LLM-based transcription. Our framework processes structured diarization inputs alongside frame-level speaker and semantic embeddings, enabling the LLM to generate segment-level transcriptions. Experiments demonstrate that the system achieves robust performance in multilingual dyadic conversations and excels in complex, high-overlap multi-speaker meeting scenarios. This work highlights the potential of LLMs as unified back-ends for joint speaker-aware segmentation and transcription.
ChronoTailor: Harnessing Attention Guidance for Fine-Grained Video Virtual Try-On
Jun 06, 2025Video virtual try-on aims to seamlessly replace the clothing of a person in a source video with a target garment. Despite significant progress in this field, existing approaches still struggle to maintain continuity and reproduce garment details. In this paper, we introduce ChronoTailor, a diffusion-based framework that generates temporally consistent videos while preserving fine-grained garment details. By employing a precise spatio-temporal attention mechanism to guide the integration of fine-grained garment features, ChronoTailor achieves robust try-on performance. First, ChronoTailor leverages region-aware spatial guidance to steer the evolution of spatial attention and employs an attention-driven temporal feature fusion mechanism to generate more continuous temporal features. This dual approach not only enables fine-grained local editing but also effectively mitigates artifacts arising from video dynamics. Second, ChronoTailor integrates multi-scale garment features to preserve low-level visual details and incorporates a garment-pose feature alignment to ensure temporal continuity during dynamic motion. Additionally, we collect StyleDress, a new dataset featuring intricate garments, varied environments, and diverse poses, offering advantages over existing public datasets, and will be publicly available for research. Extensive experiments show that ChronoTailor maintains spatio-temporal continuity and preserves garment details during motion, significantly outperforming previous methods.