 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGood Token Hunting: A Hitchhiker's Guide to Token Selection for Visual Geometry Transformers
May 22, 2026Visual geometry transformers have become powerful architectures for multi-view 3D reconstruction, enabling joint prediction of multiple 3D attributes in a feed-forward manner. However, their computational cost grows quadratically with the input sequence length due to the global attention layers inside these models. This limits both their scalability and efficiency. In this work, we address this challenge with a simple yet general strategy: restricting the number of key/value tokens that each query interacts with during global attention. To achieve effective token selection, we introduce a two-stage framework. First, an inter-frame selection step operates at the frame level to identify frames that should be preserved. Second, an intra-frame selection step further discards more redundant tokens within the selected frames. Our analysis highlights the advantage of a diversity-based strategy for inter-frame selection, which ensures broad coverage of the scene. For intra-frame selection, we show that layer-aware sparsification is necessary, with the selection process guided by the entropy of the global attention pattern. Our approach offers a superior speed-accuracy trade-off compared to existing solutions. Extensive experiments show that it accelerates visual geometry transformers by over 85% for scenes with 500 images while maintaining, or even improving, baseline performance, which hints that how our token selection strategy can play a crucial role in future applications of visual geometry transformers. Our project website is available at https://zsh2000.github.io/good-token-hunting.github.io.
LoopSplat: Loop Closure by Registering 3D Gaussian Splats
Aug 20, 2024



Simultaneous Localization and Mapping (SLAM) based on 3D Gaussian Splats (3DGS) has recently shown promise towards more accurate, dense 3D scene maps. However, existing 3DGS-based methods fail to address the global consistency of the scene via loop closure and/or global bundle adjustment. To this end, we propose LoopSplat, which takes RGB-D images as input and performs dense mapping with 3DGS submaps and frame-to-model tracking. LoopSplat triggers loop closure online and computes relative loop edge constraints between submaps directly via 3DGS registration, leading to improvements in efficiency and accuracy over traditional global-to-local point cloud registration. It uses a robust pose graph optimization formulation and rigidly aligns the submaps to achieve global consistency. Evaluation on the synthetic Replica and real-world TUM-RGBD, ScanNet, and ScanNet++ datasets demonstrates competitive or superior tracking, mapping, and rendering compared to existing methods for dense RGB-D SLAM. Code is available at loopsplat.github.io.
VF-NeRF: Learning Neural Vector Fields for Indoor Scene Reconstruction
Aug 16, 2024



Implicit surfaces via neural radiance fields (NeRF) have shown surprising accuracy in surface reconstruction. Despite their success in reconstructing richly textured surfaces, existing methods struggle with planar regions with weak textures, which account for the majority of indoor scenes. In this paper, we address indoor dense surface reconstruction by revisiting key aspects of NeRF in order to use the recently proposed Vector Field (VF) as the implicit representation. VF is defined by the unit vector directed to the nearest surface point. It therefore flips direction at the surface and equals to the explicit surface normals. Except for this flip, VF remains constant along planar surfaces and provides a strong inductive bias in representing planar surfaces. Concretely, we develop a novel density-VF relationship and a training scheme that allows us to learn VF via volume rendering By doing this, VF-NeRF can model large planar surfaces and sharp corners accurately. We show that, when depth cues are available, our method further improves and achieves state-of-the-art results in reconstructing indoor scenes and rendering novel views. We extensively evaluate VF-NeRF on indoor datasets and run ablations of its components.
Splat-SLAM: Globally Optimized RGB-only SLAM with 3D Gaussians
May 26, 2024



3D Gaussian Splatting has emerged as a powerful representation of geometry and appearance for RGB-only dense Simultaneous Localization and Mapping (SLAM), as it provides a compact dense map representation while enabling efficient and high-quality map rendering. However, existing methods show significantly worse reconstruction quality than competing methods using other 3D representations, e.g. neural points clouds, since they either do not employ global map and pose optimization or make use of monocular depth. In response, we propose the first RGB-only SLAM system with a dense 3D Gaussian map representation that utilizes all benefits of globally optimized tracking by adapting dynamically to keyframe pose and depth updates by actively deforming the 3D Gaussian map. Moreover, we find that refining the depth updates in inaccurate areas with a monocular depth estimator further improves the accuracy of the 3D reconstruction. Our experiments on the Replica, TUM-RGBD, and ScanNet datasets indicate the effectiveness of globally optimized 3D Gaussians, as the approach achieves superior or on par performance with existing RGB-only SLAM methods methods in tracking, mapping and rendering accuracy while yielding small map sizes and fast runtimes. The source code is available at https://github.com/eriksandstroem/Splat-SLAM.
GlORIE-SLAM: Globally Optimized RGB-only Implicit Encoding Point Cloud SLAM
Mar 30, 2024



Recent advancements in RGB-only dense Simultaneous Localization and Mapping (SLAM) have predominantly utilized grid-based neural implicit encodings and/or struggle to efficiently realize global map and pose consistency. To this end, we propose an efficient RGB-only dense SLAM system using a flexible neural point cloud scene representation that adapts to keyframe poses and depth updates, without needing costly backpropagation. Another critical challenge of RGB-only SLAM is the lack of geometric priors. To alleviate this issue, with the aid of a monocular depth estimator, we introduce a novel DSPO layer for bundle adjustment which optimizes the pose and depth of keyframes along with the scale of the monocular depth. Finally, our system benefits from loop closure and online global bundle adjustment and performs either better or competitive to existing dense neural RGB SLAM methods in tracking, mapping and rendering accuracy on the Replica, TUM-RGBD and ScanNet datasets. The source code will be made available.
How NeRFs and 3D Gaussian Splatting are Reshaping SLAM: a Survey
Feb 20, 2024Over the past two decades, research in the field of Simultaneous Localization and Mapping (SLAM) has undergone a significant evolution, highlighting its critical role in enabling autonomous exploration of unknown environments. This evolution ranges from hand-crafted methods, through the era of deep learning, to more recent developments focused on Neural Radiance Fields (NeRFs) and 3D Gaussian Splatting (3DGS) representations. Recognizing the growing body of research and the absence of a comprehensive survey on the topic, this paper aims to provide the first comprehensive overview of SLAM progress through the lens of the latest advancements in radiance fields. It sheds light on the background, evolutionary path, inherent strengths and limitations, and serves as a fundamental reference to highlight the dynamic progress and specific challenges.
Loopy-SLAM: Dense Neural SLAM with Loop Closures
Feb 14, 2024



Neural RGBD SLAM techniques have shown promise in dense Simultaneous Localization And Mapping (SLAM), yet face challenges such as error accumulation during camera tracking resulting in distorted maps. In response, we introduce Loopy-SLAM that globally optimizes poses and the dense 3D model. We use frame-to-model tracking using a data-driven point-based submap generation method and trigger loop closures online by performing global place recognition. Robust pose graph optimization is used to rigidly align the local submaps. As our representation is point based, map corrections can be performed efficiently without the need to store the entire history of input frames used for mapping as typically required by methods employing a grid based mapping structure. Evaluation on the synthetic Replica and real-world TUM-RGBD and ScanNet datasets demonstrate competitive or superior performance in tracking, mapping, and rendering accuracy when compared to existing dense neural RGBD SLAM methods. Project page: notchla.github.io/Loopy-SLAM.
UncLe-SLAM: Uncertainty Learning for Dense Neural SLAM
Jun 19, 2023We present an uncertainty learning framework for dense neural simultaneous localization and mapping (SLAM). Estimating pixel-wise uncertainties for the depth input of dense SLAM methods allows to re-weigh the tracking and mapping losses towards image regions that contain more suitable information that is more reliable for SLAM. To this end, we propose an online framework for sensor uncertainty estimation that can be trained in a self-supervised manner from only 2D input data. We further discuss the advantages of the uncertainty learning for the case of multi-sensor input. Extensive analysis, experimentation, and ablations show that our proposed modeling paradigm improves both mapping and tracking accuracy and often performs better than alternatives that require ground truth depth or 3D. Our experiments show that we achieve a 38% and 27% lower absolute trajectory tracking error (ATE) on the 7-Scenes and TUM-RGBD datasets respectively. On the popular Replica dataset on two types of depth sensors we report an 11% F1-score improvement on RGBD SLAM compared to the recent state-of-the-art neural implicit approaches. Our source code will be made available.
Point-SLAM: Dense Neural Point Cloud-based SLAM
Apr 09, 2023We propose a dense neural simultaneous localization and mapping (SLAM) approach for monocular RGBD input which anchors the features of a neural scene representation in a point cloud that is iteratively generated in an input-dependent data-driven manner. We demonstrate that both tracking and mapping can be performed with the same point-based neural scene representation by minimizing an RGBD-based re-rendering loss. In contrast to recent dense neural SLAM methods which anchor the scene features in a sparse grid, our point-based approach allows dynamically adapting the anchor point density to the information density of the input. This strategy reduces runtime and memory usage in regions with fewer details and dedicates higher point density to resolve fine details. Our approach performs either better or competitive to existing dense neural RGBD SLAM methods in tracking, mapping and rendering accuracy on the Replica, TUM-RGBD and ScanNet datasets. The source code is available at https://github.com/tfy14esa/Point-SLAM.
Learning Online Multi-Sensor Depth Fusion
Apr 07, 2022

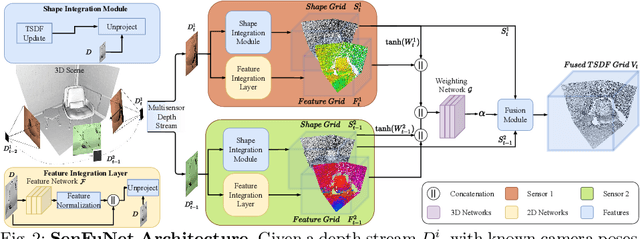
Many hand-held or mixed reality devices are used with a single sensor for 3D reconstruction, although they often comprise multiple sensors. Multi-sensor depth fusion is able to substantially improve the robustness and accuracy of 3D reconstruction methods, but existing techniques are not robust enough to handle sensors which operate with diverse value ranges as well as noise and outlier statistics. To this end, we introduce SenFuNet, a depth fusion approach that learns sensor-specific noise and outlier statistics and combines the data streams of depth frames from different sensors in an online fashion. Our method fuses multi-sensor depth streams regardless of time synchronization and calibration and generalizes well with little training data. We conduct experiments with various sensor combinations on the real-world CoRBS and Scene3D datasets, as well as the Replica dataset. Experiments demonstrate that our fusion strategy outperforms traditional and recent online depth fusion approaches. In addition, the combination of multiple sensors yields more robust outlier handling and precise surface reconstruction than the use of a single sensor.