 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePreTraM: Self-Supervised Pre-training via Connecting Trajectory and Map
Apr 21, 2022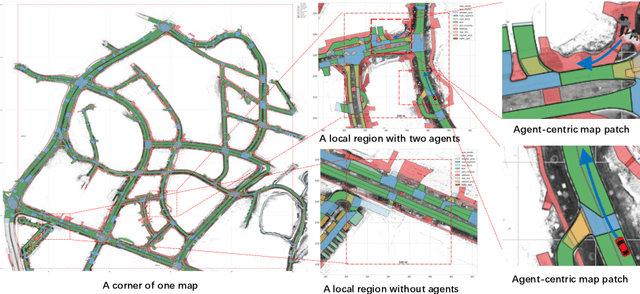
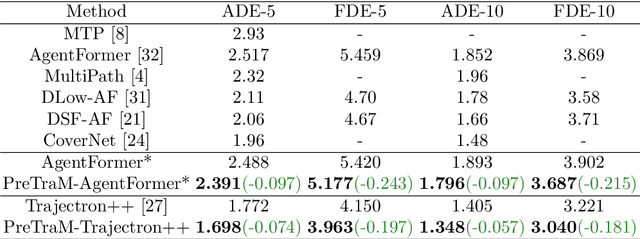
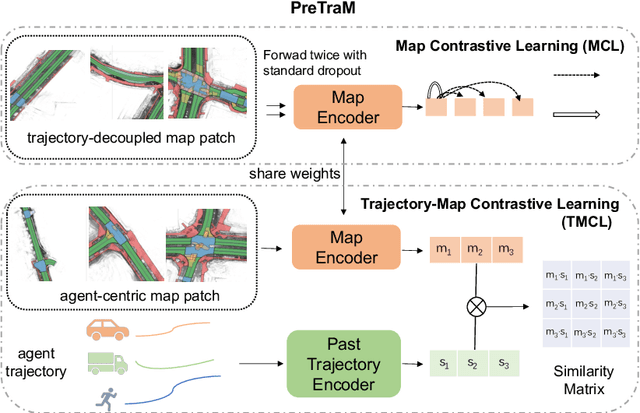

Deep learning has recently achieved significant progress in trajectory forecasting. However, the scarcity of trajectory data inhibits the data-hungry deep-learning models from learning good representations. While mature representation learning methods exist in computer vision and natural language processing, these pre-training methods require large-scale data. It is hard to replicate these approaches in trajectory forecasting due to the lack of adequate trajectory data (e.g., 34K samples in the nuScenes dataset). To work around the scarcity of trajectory data, we resort to another data modality closely related to trajectories-HD-maps, which is abundantly provided in existing datasets. In this paper, we propose PreTraM, a self-supervised pre-training scheme via connecting trajectories and maps for trajectory forecasting. Specifically, PreTraM consists of two parts: 1) Trajectory-Map Contrastive Learning, where we project trajectories and maps to a shared embedding space with cross-modal contrastive learning, and 2) Map Contrastive Learning, where we enhance map representation with contrastive learning on large quantities of HD-maps. On top of popular baselines such as AgentFormer and Trajectron++, PreTraM boosts their performance by 5.5% and 6.9% relatively in FDE-10 on the challenging nuScenes dataset. We show that PreTraM improves data efficiency and scales well with model size.
Interventional Behavior Prediction: Avoiding Overly Confident Anticipation in Interactive Prediction
Apr 19, 2022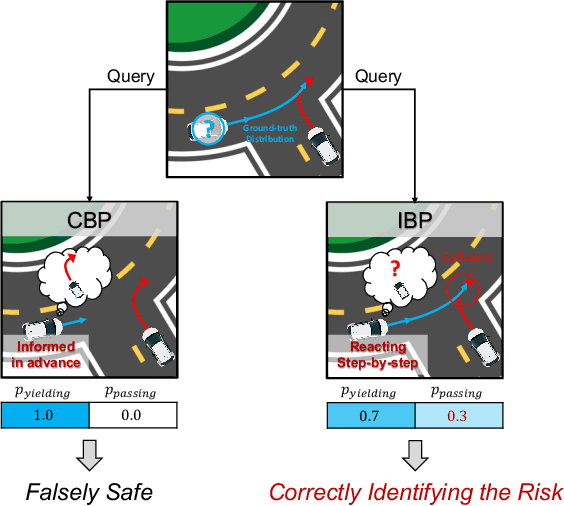
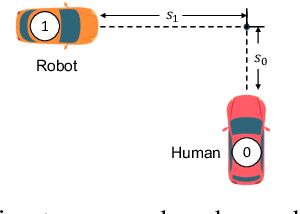
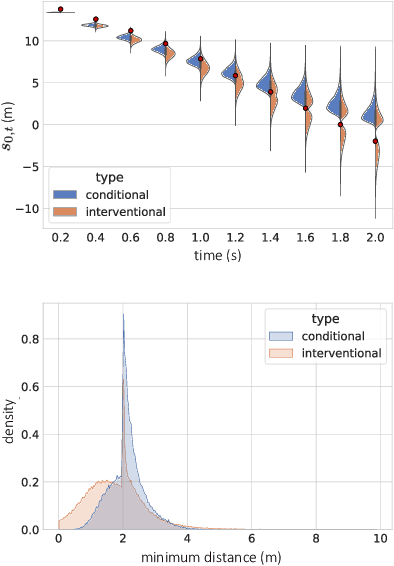
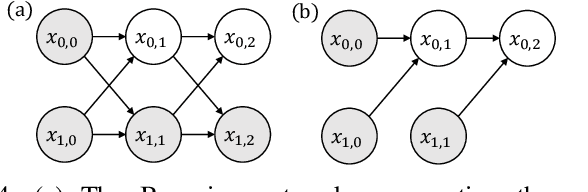
Conditional behavior prediction (CBP) builds up the foundation for a coherent interactive prediction and planning framework that can enable more efficient and less conservative maneuvers in interactive scenarios. In CBP task, we train a prediction model approximating the posterior distribution of target agents' future trajectories conditioned on the future trajectory of an assigned ego agent. However, we argue that CBP may provide overly confident anticipation on how the autonomous agent may influence the target agents' behavior. Consequently, it is risky for the planner to query a CBP model. Instead, we should treat the planned trajectory as an intervention and let the model learn the trajectory distribution under intervention. We refer to it as the interventional behavior prediction (IBP) task. Moreover, to properly evaluate an IBP model with offline datasets, we propose a Shapley-value-based metric to testify if the prediction model satisfies the inherent temporal independence of an interventional distribution. We show that the proposed metric can effectively identify a CBP model violating the temporal independence, which plays an important role when establishing IBP benchmarks.
Long-Horizon Motion Planning via Sampling and Segmented Trajectory Optimization
Apr 17, 2022
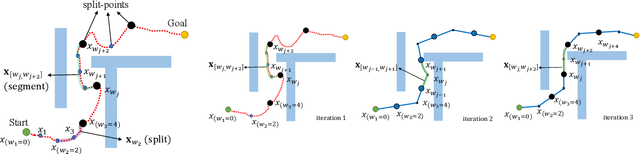
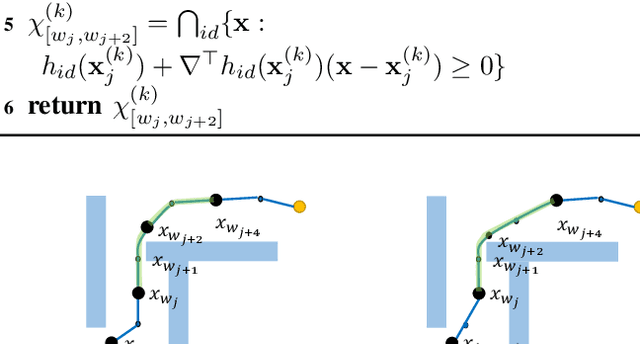
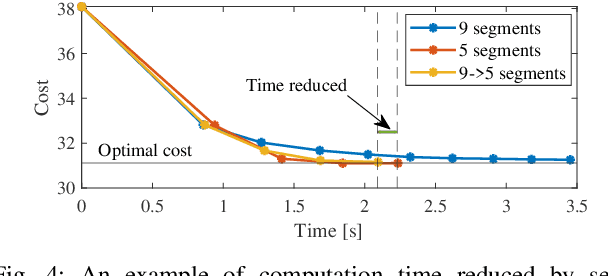
This paper presents a hybrid robot motion planner that generates long-horizon motion plans for robot navigation in environments with obstacles. We propose a hybrid planner, RRT* with segmented trajectory optimization (RRT*-sOpt), which combines the merits of sampling-based planning, optimization-based planning, and trajectory splitting to quickly plan for a collision-free and dynamically-feasible motion plan. When generating a plan, the RRT* layer quickly samples a semi-optimal path and sets it as an initial reference path. Then, the sOpt layer splits the reference path and performs optimization on each segment. It then splits the new trajectory again and repeats the process until the whole trajectory converges. We also propose to reduce the number of segments before convergence with the aim of further reducing computation time. Simulation results show that RRT*-sOpt benefits from the hybrid structure with trajectory splitting and performs robustly in various robot platforms and scenarios.
Robust Task Planning for Assembly Lines with Human-Robot Collaboration
Apr 17, 2022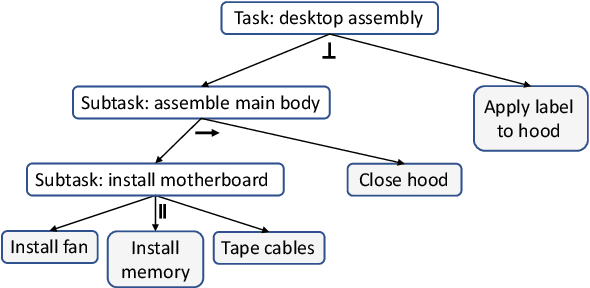
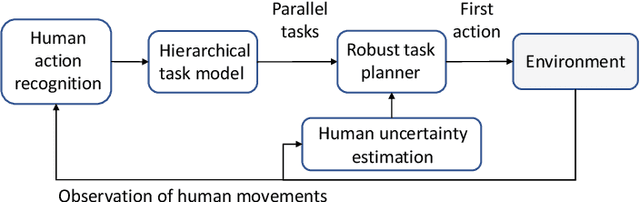
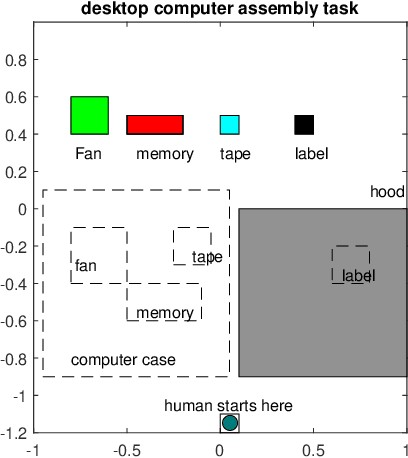

Efficient and robust task planning for a human-robot collaboration (HRC) system remains challenging. The human-aware task planner needs to assign jobs to both robots and human workers so that they can work collaboratively to achieve better time efficiency. However, the complexity of the tasks and the stochastic nature of the human collaborators bring challenges to such task planning. To reduce the complexity of the planning problem, we utilize the hierarchical task model, which explicitly captures the sequential and parallel relationships of the task. We model human movements with the sigma-lognormal functions to account for human-induced uncertainties. A human action model adaptation scheme is applied during run-time, and it provides a measure for modeling the human-induced uncertainties. We propose a sampling-based method to estimate human job completion time uncertainties. Next, we propose a robust task planner, which formulates the planning problem as a robust optimization problem by considering the task structure and the uncertainties. We conduct simulations of a robot arm collaborating with a human worker in an electronics assembly setting. The results show that our proposed planner can reduce task completion time when human-induced uncertainties occur compared to the baseline planner.
Domain Knowledge Driven Pseudo Labels for Interpretable Goal-Conditioned Interactive Trajectory Prediction
Apr 05, 2022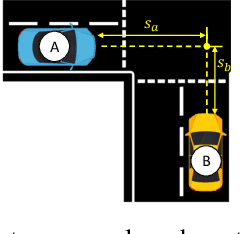
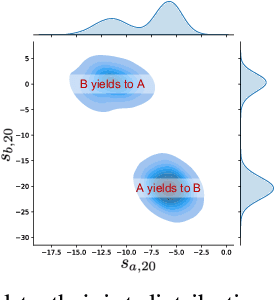
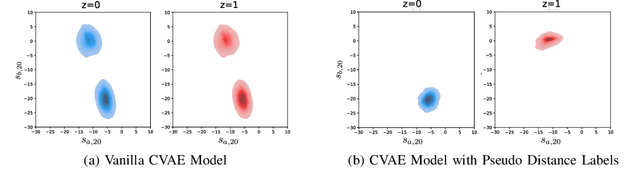
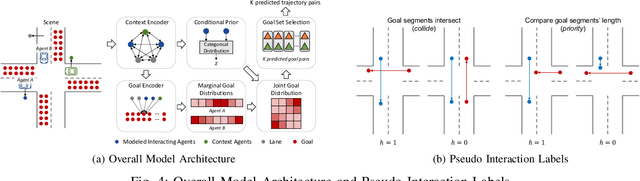
Motion forecasting in highly interactive scenarios is a challenging problem in autonomous driving. In such scenarios, we need to accurately predict the joint behavior of interacting agents to ensure the safe and efficient navigation of autonomous vehicles. Recently, goal-conditioned methods have gained increasing attention due to their advantage in performance and their ability to capture the multimodality in trajectory distribution. In this work, we study the joint trajectory prediction problem with the goal-conditioned framework. In particular, we introduce a conditional-variational-autoencoder-based (CVAE) model to explicitly encode different interaction modes into the latent space. However, we discover that the vanilla model suffers from posterior collapse and cannot induce an informative latent space as desired. To address these issues, we propose a novel approach to avoid KL vanishing and induce an interpretable interactive latent space with pseudo labels. The pseudo labels allow us to incorporate arbitrary domain knowledge on interaction. We motivate the proposed method using an illustrative toy example. In addition, we validate our framework on the Waymo Open Motion Dataset with both quantitative and qualitative evaluations.
Learning to Synthesize Volumetric Meshes from Vision-based Tactile Imprints
Mar 29, 2022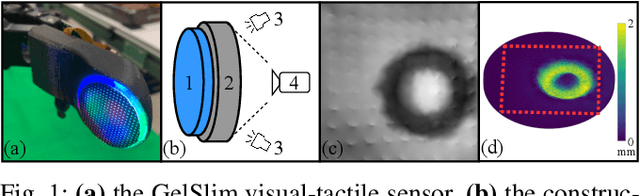
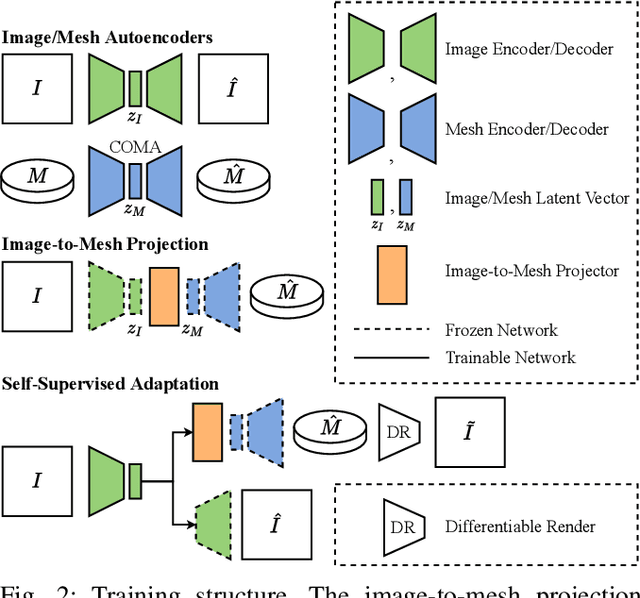


Vision-based tactile sensors typically utilize a deformable elastomer and a camera mounted above to provide high-resolution image observations of contacts. Obtaining accurate volumetric meshes for the deformed elastomer can provide direct contact information and benefit robotic grasping and manipulation. This paper focuses on learning to synthesize the volumetric mesh of the elastomer based on the image imprints acquired from vision-based tactile sensors. Synthetic image-mesh pairs and real-world images are gathered from 3D finite element methods (FEM) and physical sensors, respectively. A graph neural network (GNN) is introduced to learn the image-to-mesh mappings with supervised learning. A self-supervised adaptation method and image augmentation techniques are proposed to transfer networks from simulation to reality, from primitive contacts to unseen contacts, and from one sensor to another. Using these learned and adapted networks, our proposed method can accurately reconstruct the deformation of the real-world tactile sensor elastomer in various domains, as indicated by the quantitative and qualitative results.
Offline-Online Learning of Deformation Model for Cable Manipulation with Graph Neural Networks
Mar 28, 2022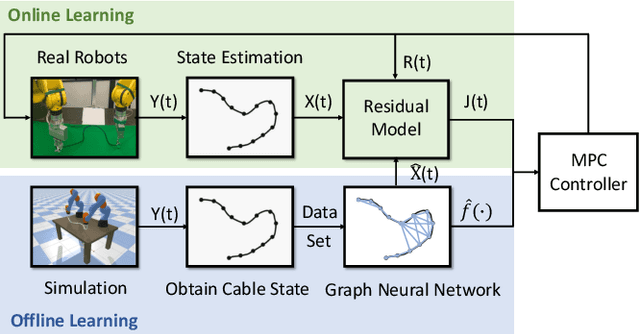
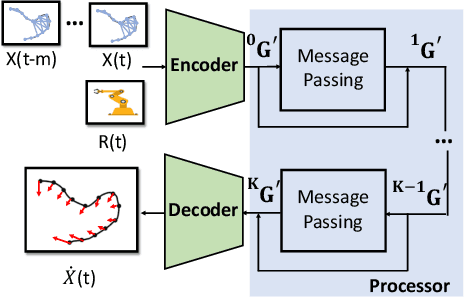
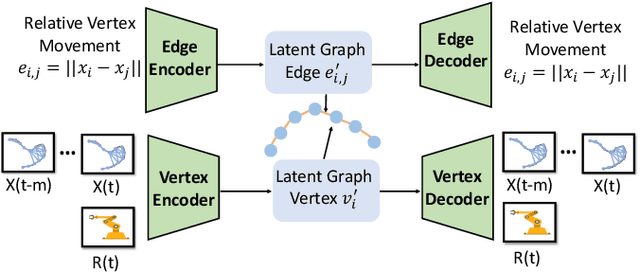
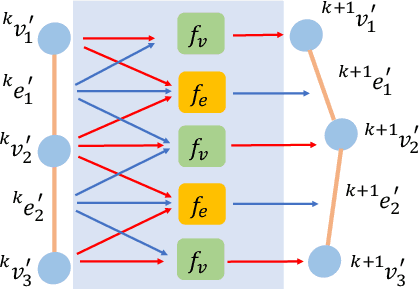
Manipulating deformable linear objects by robots has a wide range of applications, e.g., manufacturing and medical surgery. To complete such tasks, an accurate dynamics model for predicting the deformation is critical for robust control. In this work, we deal with this challenge by proposing a hybrid offline-online method to learn the dynamics of cables in a robust and data-efficient manner. In the offline phase, we adopt Graph Neural Network (GNN) to learn the deformation dynamics purely from the simulation data. Then a linear residual model is learned in real-time to bridge the sim-to-real gap. The learned model is then utilized as the dynamics constraint of a trust region based Model Predictive Controller (MPC) to calculate the optimal robot movements. The online learning and MPC run in a closed-loop manner to robustly accomplish the task. Finally, comparative results with existing methods are provided to quantitatively show the effectiveness and robustness.
DetMatch: Two Teachers are Better Than One for Joint 2D and 3D Semi-Supervised Object Detection
Mar 17, 2022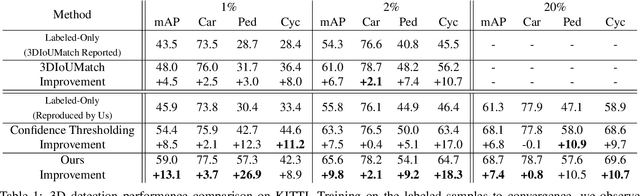
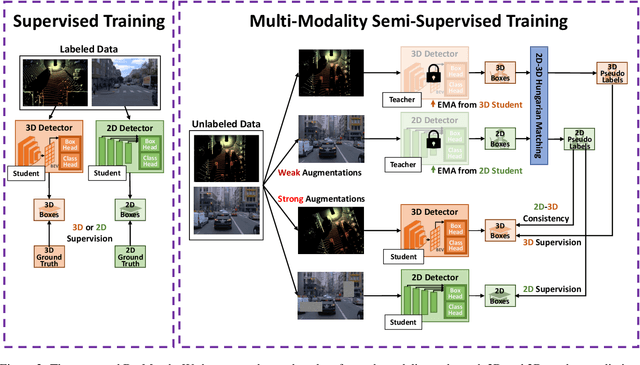

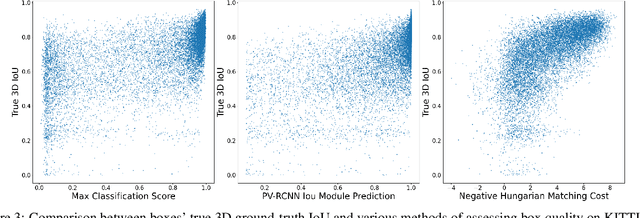
While numerous 3D detection works leverage the complementary relationship between RGB images and point clouds, developments in the broader framework of semi-supervised object recognition remain uninfluenced by multi-modal fusion. Current methods develop independent pipelines for 2D and 3D semi-supervised learning despite the availability of paired image and point cloud frames. Observing that the distinct characteristics of each sensor cause them to be biased towards detecting different objects, we propose DetMatch, a flexible framework for joint semi-supervised learning on 2D and 3D modalities. By identifying objects detected in both sensors, our pipeline generates a cleaner, more robust set of pseudo-labels that both demonstrates stronger performance and stymies single-modality error propagation. Further, we leverage the richer semantics of RGB images to rectify incorrect 3D class predictions and improve localization of 3D boxes. Evaluating on the challenging KITTI and Waymo datasets, we improve upon strong semi-supervised learning methods and observe higher quality pseudo-labels. Code will be released at https://github.com/Divadi/DetMatch
Important Object Identification with Semi-Supervised Learning for Autonomous Driving
Mar 05, 2022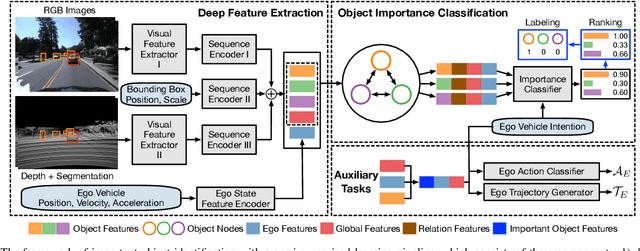
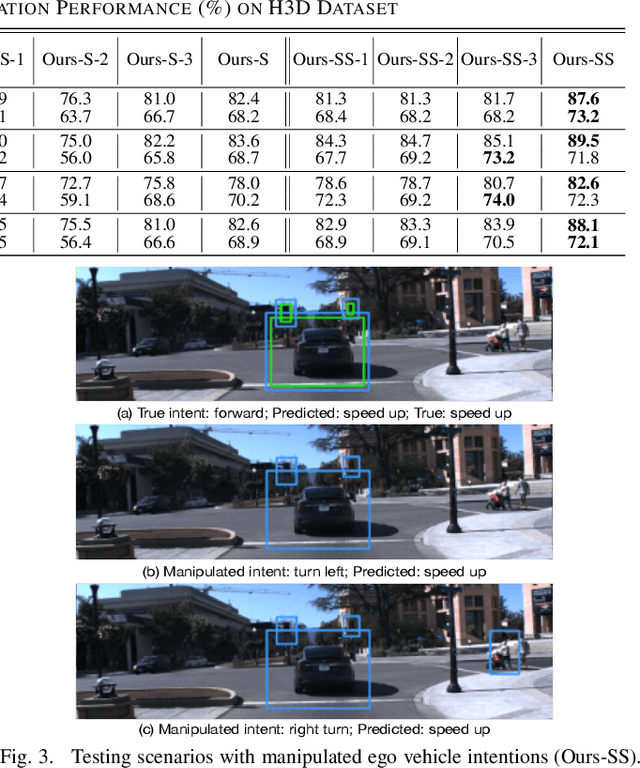
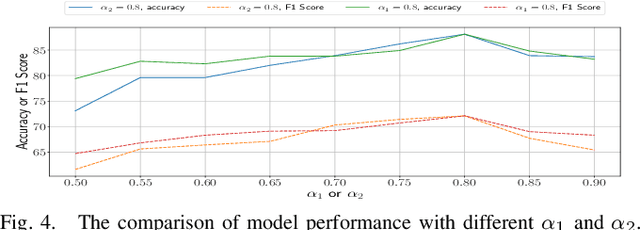
Accurate identification of important objects in the scene is a prerequisite for safe and high-quality decision making and motion planning of intelligent agents (e.g., autonomous vehicles) that navigate in complex and dynamic environments. Most existing approaches attempt to employ attention mechanisms to learn importance weights associated with each object indirectly via various tasks (e.g., trajectory prediction), which do not enforce direct supervision on the importance estimation. In contrast, we tackle this task in an explicit way and formulate it as a binary classification ("important" or "unimportant") problem. We propose a novel approach for important object identification in egocentric driving scenarios with relational reasoning on the objects in the scene. Besides, since human annotations are limited and expensive to obtain, we present a semi-supervised learning pipeline to enable the model to learn from unlimited unlabeled data. Moreover, we propose to leverage the auxiliary tasks of ego vehicle behavior prediction to further improve the accuracy of importance estimation. The proposed approach is evaluated on a public egocentric driving dataset (H3D) collected in complex traffic scenarios. A detailed ablative study is conducted to demonstrate the effectiveness of each model component and the training strategy. Our approach also outperforms rule-based baselines by a large margin.
Velocity Obstacle Based Risk-Bounded Motion Planning for Stochastic Multi-Agent Systems
Feb 20, 2022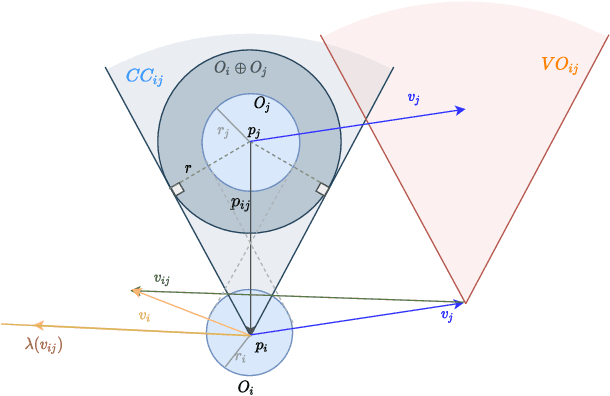
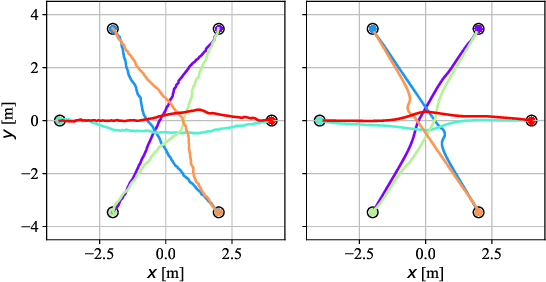
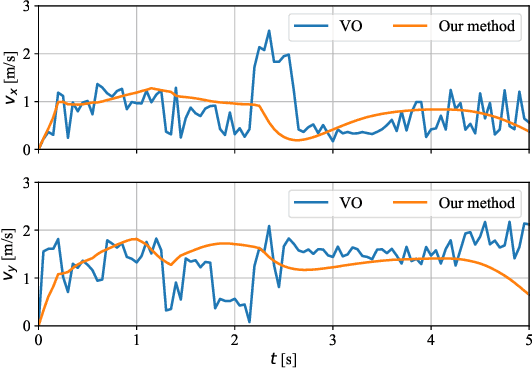
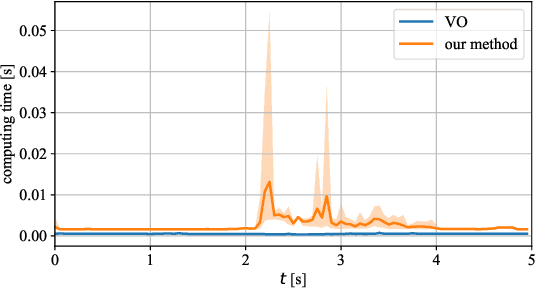
In this paper, we present an innovative risk-bounded motion planning methodology for stochastic multi-agent systems. For this methodology, the disturbance, noise, and model uncertainty are considered; and a velocity obstacle method is utilized to formulate the collision-avoidance constraints in the velocity space. With the exploitation of geometric information of static obstacles and velocity obstacles, a distributed optimization problem with probabilistic chance constraints is formulated for the stochastic multi-agent system. Consequently, collision-free trajectories are generated under a prescribed collision risk bound. Due to the existence of probabilistic and disjunctive constraints, the distributed chance-constrained optimization problem is reformulated as a mixed-integer program by introducing the binary variable to improve computational efficiency. This approach thus renders it possible to execute the motion planning task in the velocity space instead of the position space, which leads to smoother collision-free trajectories for multi-agent systems and higher computational efficiency. Moreover, the risk of potential collisions is bounded with this robust motion planning methodology. To validate the effectiveness of the methodology, different scenarios for multiple agents are investigated, and the simulation results clearly show that the proposed approach can generate high-quality trajectories under a predefined collision risk bound and avoid potential collisions effectively in the velocity space.