 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSampling-Based Motion Planning with Scene Graphs Under Perception Constraints
Mar 03, 2026It will be increasingly common for robots to operate in cluttered human-centered environments such as homes, workplaces, and hospitals, where the robot is often tasked to maintain perception constraints, such as monitoring people or multiple objects, for safety and reliability while executing its task. However, existing perception-aware approaches typically focus on low-degree-of-freedom (DoF) systems or only consider a single object in the context of high-DoF robots. This motivates us to consider the problem of perception-aware motion planning for high-DoF robots that accounts for multi-object monitoring constraints. We employ a scene graph representation of the environment, offering a great potential for incorporating long-horizon task and motion planning thanks to its rich semantic and spatial information. However, it does not capture perception-constrained information, such as the viewpoints the user prefers. To address these challenges, we propose MOPS-PRM, a roadmap-based motion planner, that integrates the perception cost of observing multiple objects or humans directly into motion planning for high-DoF robots. The perception cost is embedded to each object as part of a scene graph, and used to selectively sample configurations for roadmap construction, implicitly enforcing the perception constraints. Our method is extensively validated in both simulated and real-world experiments, achieving more than ~36% improvement in the average number of detected objects and ~17% better track rate against other perception-constrained baselines, with comparable planning times and path lengths.
Hierarchical Imitation Learning of Team Behavior from Heterogeneous Demonstrations
Feb 24, 2025Successful collaboration requires team members to stay aligned, especially in complex sequential tasks. Team members must dynamically coordinate which subtasks to perform and in what order. However, real-world constraints like partial observability and limited communication bandwidth often lead to suboptimal collaboration. Even among expert teams, the same task can be executed in multiple ways. To develop multi-agent systems and human-AI teams for such tasks, we are interested in data-driven learning of multimodal team behaviors. Multi-Agent Imitation Learning (MAIL) provides a promising framework for data-driven learning of team behavior from demonstrations, but existing methods struggle with heterogeneous demonstrations, as they assume that all demonstrations originate from a single team policy. Hence, in this work, we introduce DTIL: a hierarchical MAIL algorithm designed to learn multimodal team behaviors in complex sequential tasks. DTIL represents each team member with a hierarchical policy and learns these policies from heterogeneous team demonstrations in a factored manner. By employing a distribution-matching approach, DTIL mitigates compounding errors and scales effectively to long horizons and continuous state representations. Experimental results show that DTIL outperforms MAIL baselines and accurately models team behavior across a variety of collaborative scenarios.
Socratic: Enhancing Human Teamwork via AI-enabled Coaching
Feb 24, 2025Coaches are vital for effective collaboration, but cost and resource constraints often limit their availability during real-world tasks. This limitation poses serious challenges in life-critical domains that rely on effective teamwork, such as healthcare and disaster response. To address this gap, we propose and realize an innovative application of AI: task-time team coaching. Specifically, we introduce Socratic, a novel AI system that complements human coaches by providing real-time guidance during task execution. Socratic monitors team behavior, detects misalignments in team members' shared understanding, and delivers automated interventions to improve team performance. We validated Socratic through two human subject experiments involving dyadic collaboration. The results demonstrate that the system significantly enhances team performance with minimal interventions. Participants also perceived Socratic as helpful and trustworthy, supporting its potential for adoption. Our findings also suggest promising directions both for AI research and its practical applications to enhance human teamwork.
IDIL: Imitation Learning of Intent-Driven Expert Behavior
Apr 25, 2024When faced with accomplishing a task, human experts exhibit intentional behavior. Their unique intents shape their plans and decisions, resulting in experts demonstrating diverse behaviors to accomplish the same task. Due to the uncertainties encountered in the real world and their bounded rationality, experts sometimes adjust their intents, which in turn influences their behaviors during task execution. This paper introduces IDIL, a novel imitation learning algorithm to mimic these diverse intent-driven behaviors of experts. Iteratively, our approach estimates expert intent from heterogeneous demonstrations and then uses it to learn an intent-aware model of their behavior. Unlike contemporary approaches, IDIL is capable of addressing sequential tasks with high-dimensional state representations, while sidestepping the complexities and drawbacks associated with adversarial training (a mainstay of related techniques). Our empirical results suggest that the models generated by IDIL either match or surpass those produced by recent imitation learning benchmarks in metrics of task performance. Moreover, as it creates a generative model, IDIL demonstrates superior performance in intent inference metrics, crucial for human-agent interactions, and aptly captures a broad spectrum of expert behaviors.
I-CEE: Tailoring Explanations of Image Classifications Models to User Expertise
Dec 19, 2023



Effectively explaining decisions of black-box machine learning models is critical to responsible deployment of AI systems that rely on them. Recognizing their importance, the field of explainable AI (XAI) provides several techniques to generate these explanations. Yet, there is relatively little emphasis on the user (the explainee) in this growing body of work and most XAI techniques generate "one-size-fits-all" explanations. To bridge this gap and achieve a step closer towards human-centered XAI, we present I-CEE, a framework that provides Image Classification Explanations tailored to User Expertise. Informed by existing work, I-CEE explains the decisions of image classification models by providing the user with an informative subset of training data (i.e., example images), corresponding local explanations, and model decisions. However, unlike prior work, I-CEE models the informativeness of the example images to depend on user expertise, resulting in different examples for different users. We posit that by tailoring the example set to user expertise, I-CEE can better facilitate users' understanding and simulatability of the model. To evaluate our approach, we conduct detailed experiments in both simulation and with human participants (N = 100) on multiple datasets. Experiments with simulated users show that I-CEE improves users' ability to accurately predict the model's decisions (simulatability) compared to baselines, providing promising preliminary results. Experiments with human participants demonstrate that our method significantly improves user simulatability accuracy, highlighting the importance of human-centered XAI
GO-DICE: Goal-Conditioned Option-Aware Offline Imitation Learning via Stationary Distribution Correction Estimation
Dec 17, 2023



Offline imitation learning (IL) refers to learning expert behavior solely from demonstrations, without any additional interaction with the environment. Despite significant advances in offline IL, existing techniques find it challenging to learn policies for long-horizon tasks and require significant re-training when task specifications change. Towards addressing these limitations, we present GO-DICE an offline IL technique for goal-conditioned long-horizon sequential tasks. GO-DICE discerns a hierarchy of sub-tasks from demonstrations and uses these to learn separate policies for sub-task transitions and action execution, respectively; this hierarchical policy learning facilitates long-horizon reasoning. Inspired by the expansive DICE-family of techniques, policy learning at both the levels transpires within the space of stationary distributions. Further, both policies are learnt with goal conditioning to minimize need for retraining when task goals change. Experimental results substantiate that GO-DICE outperforms recent baselines, as evidenced by a marked improvement in the completion rate of increasingly challenging pick-and-place Mujoco robotic tasks. GO-DICE is also capable of leveraging imperfect demonstration and partial task segmentation when available, both of which boost task performance relative to learning from expert demonstrations alone.
Automated Task-Time Interventions to Improve Teamwork using Imitation Learning
Mar 02, 2023



Effective human-human and human-autonomy teamwork is critical but often challenging to perfect. The challenge is particularly relevant in time-critical domains, such as healthcare and disaster response, where the time pressures can make coordination increasingly difficult to achieve and the consequences of imperfect coordination can be severe. To improve teamwork in these and other domains, we present TIC: an automated intervention approach for improving coordination between team members. Using BTIL, a multi-agent imitation learning algorithm, our approach first learns a generative model of team behavior from past task execution data. Next, it utilizes the learned generative model and team's task objective (shared reward) to algorithmically generate execution-time interventions. We evaluate our approach in synthetic multi-agent teaming scenarios, where team members make decentralized decisions without full observability of the environment. The experiments demonstrate that the automated interventions can successfully improve team performance and shed light on the design of autonomous agents for improving teamwork.
A Bayesian Approach to Identifying Representational Errors
Mar 28, 2021
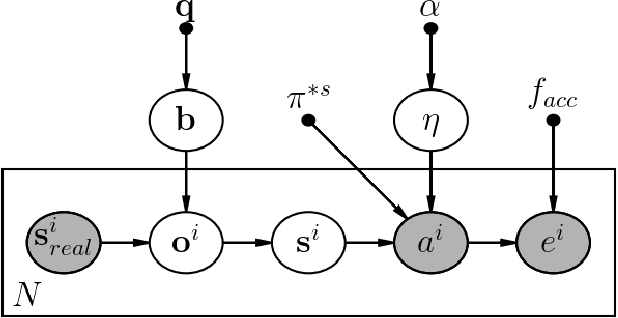


Trained AI systems and expert decision makers can make errors that are often difficult to identify and understand. Determining the root cause for these errors can improve future decisions. This work presents Generative Error Model (GEM), a generative model for inferring representational errors based on observations of an actor's behavior (either simulated agent, robot, or human). The model considers two sources of error: those that occur due to representational limitations -- "blind spots" -- and non-representational errors, such as those caused by noise in execution or systematic errors present in the actor's policy. Disambiguating these two error types allows for targeted refinement of the actor's policy (i.e., representational errors require perceptual augmentation, while other errors can be reduced through methods such as improved training or attention support). We present a Bayesian inference algorithm for GEM and evaluate its utility in recovering representational errors on multiple domains. Results show that our approach can recover blind spots of both reinforcement learning agents as well as human users.
Learning Dense Rewards for Contact-Rich Manipulation Tasks
Nov 17, 2020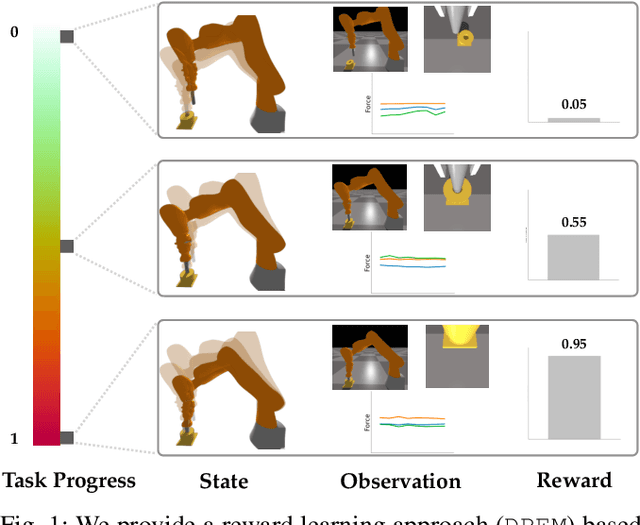
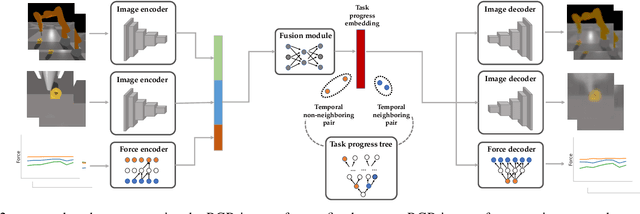
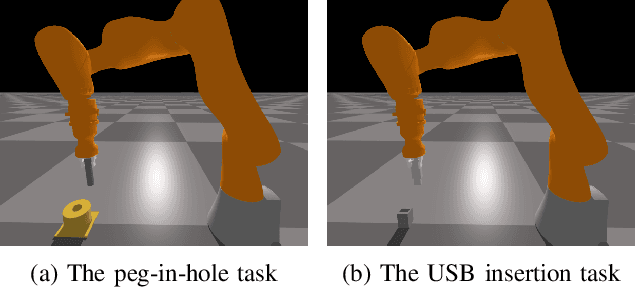
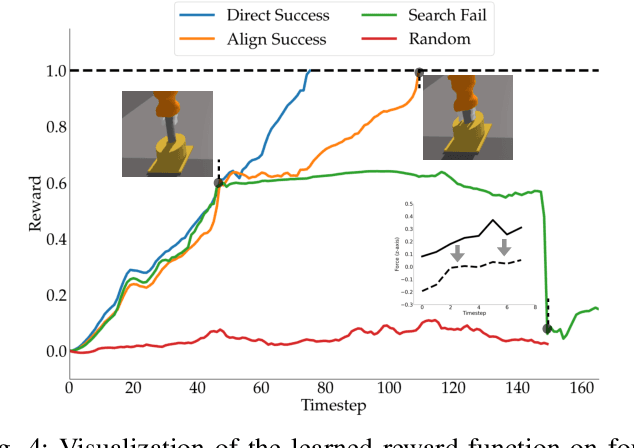
Rewards play a crucial role in reinforcement learning. To arrive at the desired policy, the design of a suitable reward function often requires significant domain expertise as well as trial-and-error. Here, we aim to minimize the effort involved in designing reward functions for contact-rich manipulation tasks. In particular, we provide an approach capable of extracting dense reward functions algorithmically from robots' high-dimensional observations, such as images and tactile feedback. In contrast to state-of-the-art high-dimensional reward learning methodologies, our approach does not leverage adversarial training, and is thus less prone to the associated training instabilities. Instead, our approach learns rewards by estimating task progress in a self-supervised manner. We demonstrate the effectiveness and efficiency of our approach on two contact-rich manipulation tasks, namely, peg-in-hole and USB insertion. The experimental results indicate that the policies trained with the learned reward function achieves better performance and faster convergence compared to the baselines.