 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBounded Risk-Sensitive Markov Game and Its Inverse Reward Learning Problem
Paper and Code
Sep 05, 2020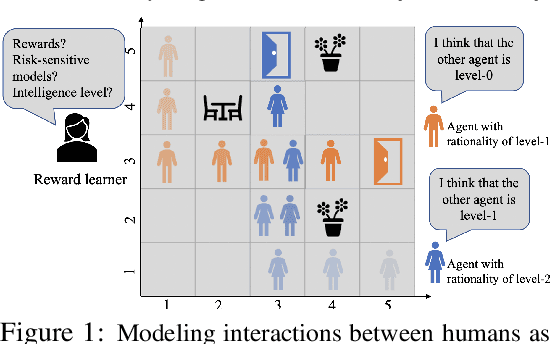

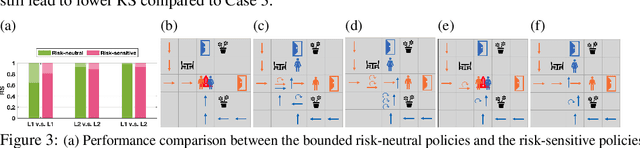

Classical game-theoretic approaches for multi-agent systems in both the forward policy learning/design problem and the inverse reward learning problem often make strong rationality assumptions: agents are perfectly rational expected utility maximizers. Specifically, the agents are risk-neutral to all uncertainties, maximize their expected rewards, and have unlimited computation resources to explore such policies. Such assumptions, however, substantially mismatch with many observed humans' behaviors such as satisficing with sub-optimal policies, risk-seeking and loss-aversion decisions. In this paper, we investigate the problem of bounded risk-sensitive Markov Game (BRSMG) and its inverse reward learning problem. Instead of assuming unlimited computation resources, we consider the influence of bounded intelligence by exploiting iterative reasoning models in BRSMG. Instead of assuming agents maximize their expected utilities (a risk-neutral measure), we consider the impact of risk-sensitive measures such as the cumulative prospect theory. Convergence analysis of BRSMG for both the forward policy learning and the inverse reward learning are established. The proposed forward policy learning and inverse reward learning algorithms in BRSMG are validated through a navigation scenario. Simulation results show that the behaviors of agents in BRSMG demonstrate both risk-averse and risk-seeking phenomena, which are consistent with observations from humans. Moreover, in the inverse reward learning task, the proposed bounded risk-sensitive inverse learning algorithm outperforms the baseline risk-neutral inverse learning algorithm.