 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgemPLUG: Effective and Efficient Vision-Language Learning by Cross-modal Skip-connections
May 25, 2022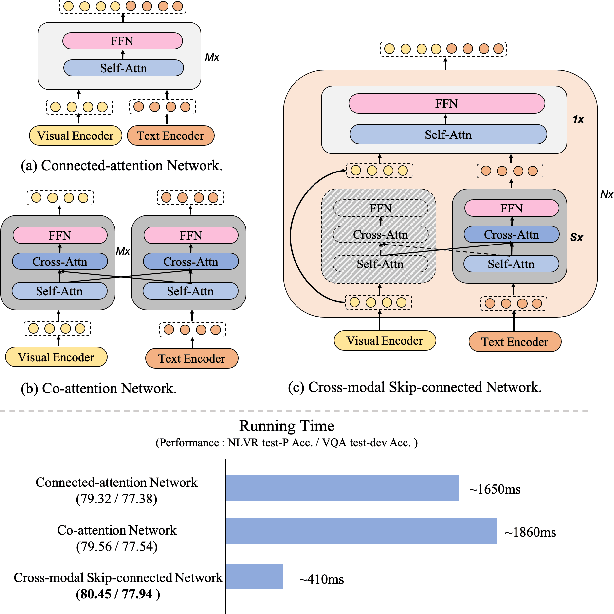
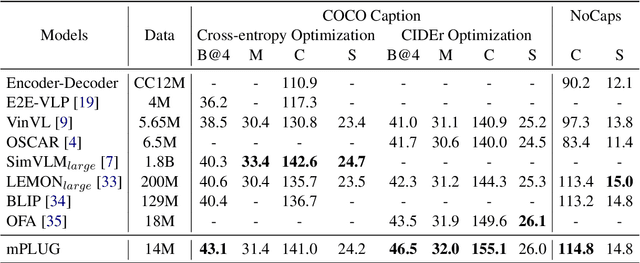
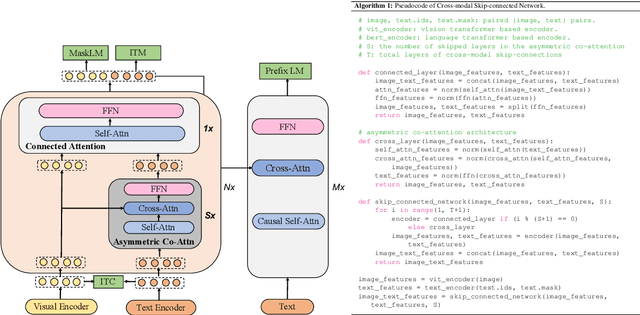
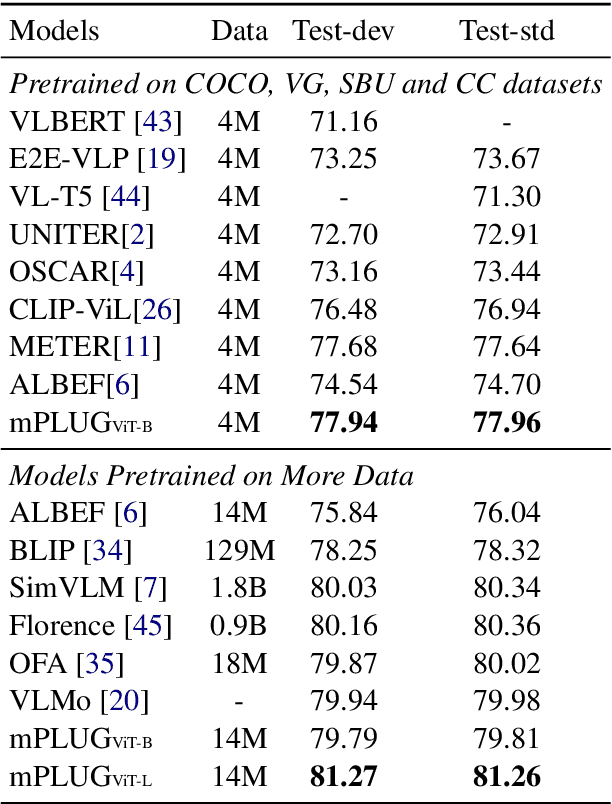
Large-scale pretrained foundation models have been an emerging paradigm for building artificial intelligence (AI) systems, which can be quickly adapted to a wide range of downstream tasks. This paper presents mPLUG, a new vision-language foundation model for both cross-modal understanding and generation. Most existing pre-trained models suffer from the problems of low computational efficiency and information asymmetry brought by the long visual sequence in cross-modal alignment. To address these problems, mPLUG introduces an effective and efficient vision-language architecture with novel cross-modal skip-connections, which creates inter-layer shortcuts that skip a certain number of layers for time-consuming full self-attention on the vision side. mPLUG is pre-trained end-to-end on large-scale image-text pairs with both discriminative and generative objectives. It achieves state-of-the-art results on a wide range of vision-language downstream tasks, such as image captioning, image-text retrieval, visual grounding and visual question answering. mPLUG also demonstrates strong zero-shot transferability when directly transferred to multiple video-language tasks.
Good Visual Guidance Makes A Better Extractor: Hierarchical Visual Prefix for Multimodal Entity and Relation Extraction
May 07, 2022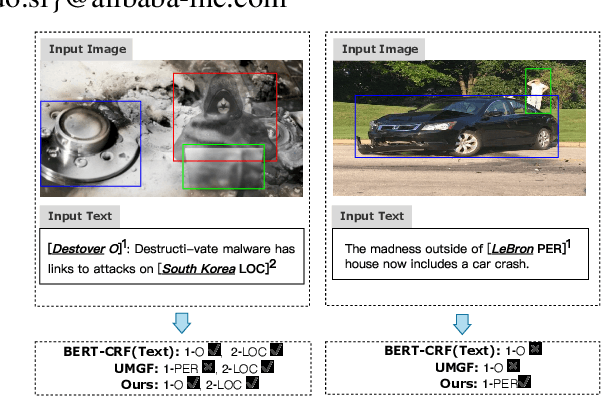
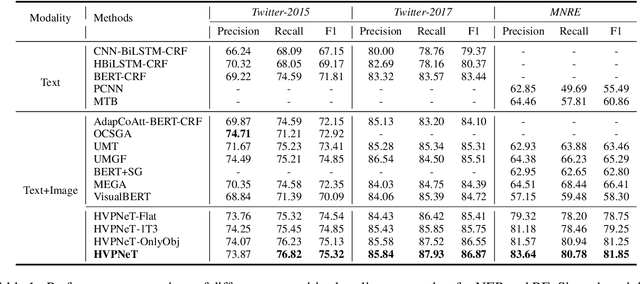
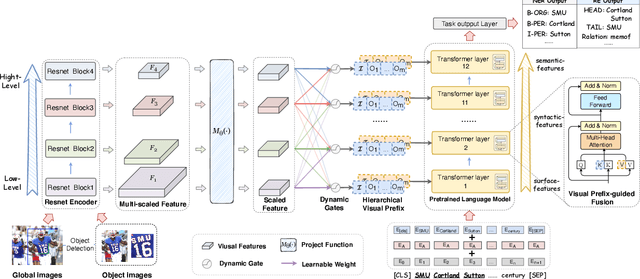

Multimodal named entity recognition and relation extraction (MNER and MRE) is a fundamental and crucial branch in information extraction. However, existing approaches for MNER and MRE usually suffer from error sensitivity when irrelevant object images incorporated in texts. To deal with these issues, we propose a novel Hierarchical Visual Prefix fusion NeTwork (HVPNeT) for visual-enhanced entity and relation extraction, aiming to achieve more effective and robust performance. Specifically, we regard visual representation as pluggable visual prefix to guide the textual representation for error insensitive forecasting decision. We further propose a dynamic gated aggregation strategy to achieve hierarchical multi-scaled visual features as visual prefix for fusion. Extensive experiments on three benchmark datasets demonstrate the effectiveness of our method, and achieve state-of-the-art performance. Code is available in https://github.com/zjunlp/HVPNeT.
Hybrid Transformer with Multi-level Fusion for Multimodal Knowledge Graph Completion
May 04, 2022
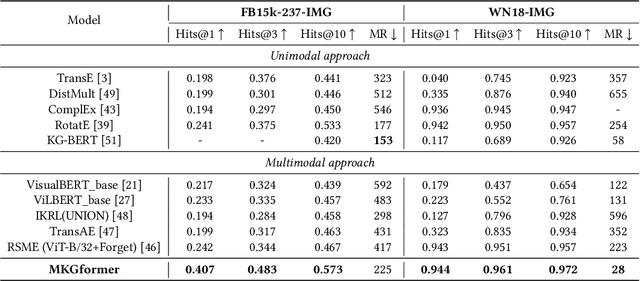
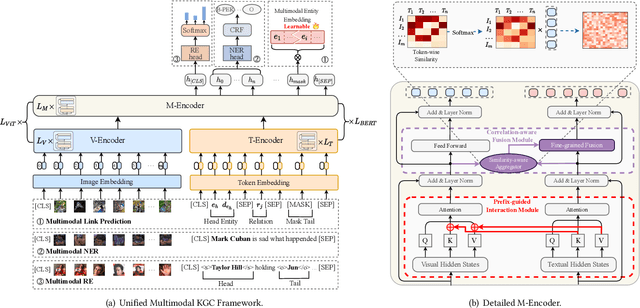
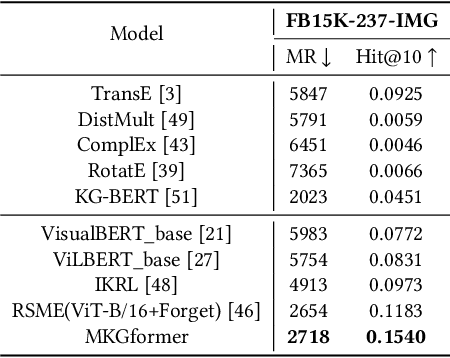
Multimodal Knowledge Graphs (MKGs), which organize visual-text factual knowledge, have recently been successfully applied to tasks such as information retrieval, question answering, and recommendation system. Since most MKGs are far from complete, extensive knowledge graph completion studies have been proposed focusing on the multimodal entity, relation extraction and link prediction. However, different tasks and modalities require changes to the model architecture, and not all images/objects are relevant to text input, which hinders the applicability to diverse real-world scenarios. In this paper, we propose a hybrid transformer with multi-level fusion to address those issues. Specifically, we leverage a hybrid transformer architecture with unified input-output for diverse multimodal knowledge graph completion tasks. Moreover, we propose multi-level fusion, which integrates visual and text representation via coarse-grained prefix-guided interaction and fine-grained correlation-aware fusion modules. We conduct extensive experiments to validate that our MKGformer can obtain SOTA performance on four datasets of multimodal link prediction, multimodal RE, and multimodal NER. Code is available in https://github.com/zjunlp/MKGformer.
Relation Extraction as Open-book Examination: Retrieval-enhanced Prompt Tuning
May 04, 2022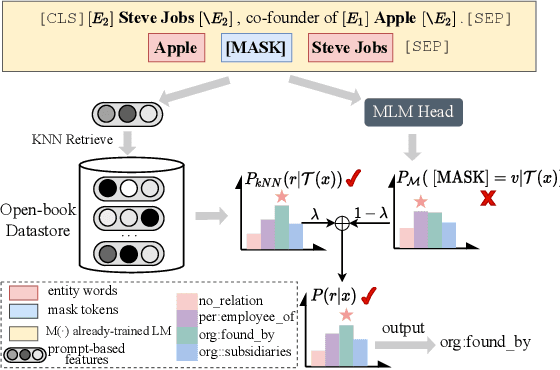

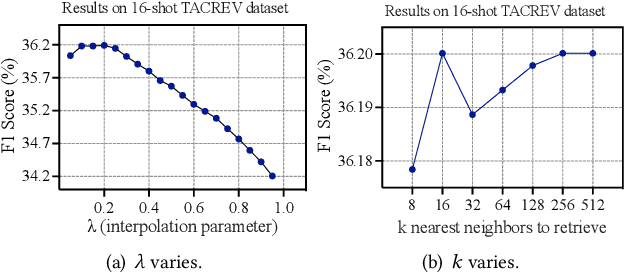
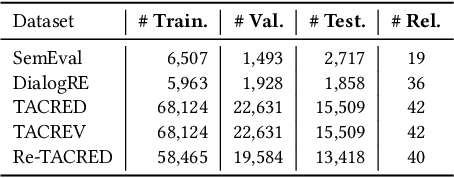
Pre-trained language models have contributed significantly to relation extraction by demonstrating remarkable few-shot learning abilities. However, prompt tuning methods for relation extraction may still fail to generalize to those rare or hard patterns. Note that the previous parametric learning paradigm can be viewed as memorization regarding training data as a book and inference as the close-book test. Those long-tailed or hard patterns can hardly be memorized in parameters given few-shot instances. To this end, we regard RE as an open-book examination and propose a new semiparametric paradigm of retrieval-enhanced prompt tuning for relation extraction. We construct an open-book datastore for retrieval regarding prompt-based instance representations and corresponding relation labels as memorized key-value pairs. During inference, the model can infer relations by linearly interpolating the base output of PLM with the non-parametric nearest neighbor distribution over the datastore. In this way, our model not only infers relation through knowledge stored in the weights during training but also assists decision-making by unwinding and querying examples in the open-book datastore. Extensive experiments on benchmark datasets show that our method can achieve state-of-the-art in both standard supervised and few-shot settings. Code are available in https://github.com/zjunlp/PromptKG/tree/main/research/RetrievalRE.
IAM: A Comprehensive and Large-Scale Dataset for Integrated Argument Mining Tasks
Mar 24, 2022

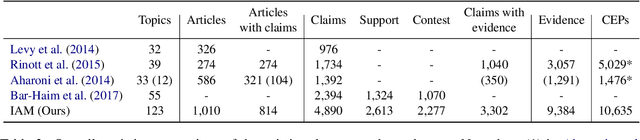
Traditionally, a debate usually requires a manual preparation process, including reading plenty of articles, selecting the claims, identifying the stances of the claims, seeking the evidence for the claims, etc. As the AI debate attracts more attention these years, it is worth exploring the methods to automate the tedious process involved in the debating system. In this work, we introduce a comprehensive and large dataset named IAM, which can be applied to a series of argument mining tasks, including claim extraction, stance classification, evidence extraction, etc. Our dataset is collected from over 1k articles related to 123 topics. Near 70k sentences in the dataset are fully annotated based on their argument properties (e.g., claims, stances, evidence, etc.). We further propose two new integrated argument mining tasks associated with the debate preparation process: (1) claim extraction with stance classification (CESC) and (2) claim-evidence pair extraction (CEPE). We adopt a pipeline approach and an end-to-end method for each integrated task separately. Promising experimental results are reported to show the values and challenges of our proposed tasks, and motivate future research on argument mining.
RelationPrompt: Leveraging Prompts to Generate Synthetic Data for Zero-Shot Relation Triplet Extraction
Mar 17, 2022
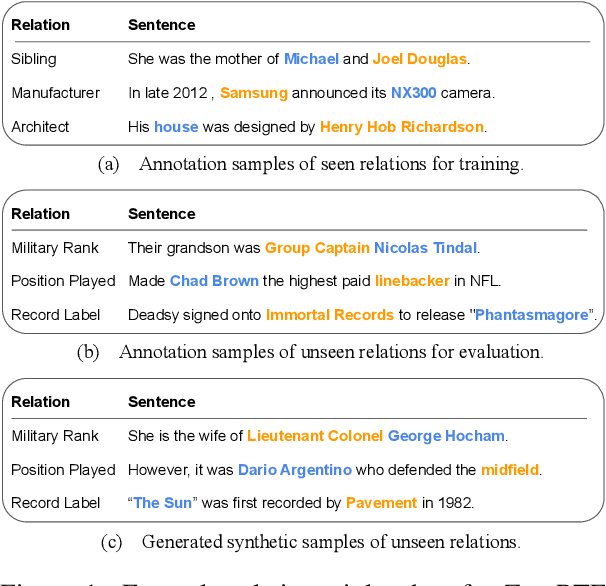

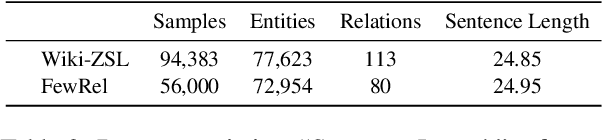
Despite the importance of relation extraction in building and representing knowledge, less research is focused on generalizing to unseen relations types. We introduce the task setting of Zero-Shot Relation Triplet Extraction (ZeroRTE) to encourage further research in low-resource relation extraction methods. Given an input sentence, each extracted triplet consists of the head entity, relation label, and tail entity where the relation label is not seen at the training stage. To solve ZeroRTE, we propose to synthesize relation examples by prompting language models to generate structured texts. Concretely, we unify language model prompts and structured text approaches to design a structured prompt template for generating synthetic relation samples when conditioning on relation label prompts (RelationPrompt). To overcome the limitation for extracting multiple relation triplets in a sentence, we design a novel Triplet Search Decoding method. Experiments on FewRel and Wiki-ZSL datasets show the efficacy of RelationPrompt for the ZeroRTE task and zero-shot relation classification. Our code and data are available at github.com/declare-lab/RelationPrompt.
GALAXY: A Generative Pre-trained Model for Task-Oriented Dialog with Semi-Supervised Learning and Explicit Policy Injection
Dec 27, 2021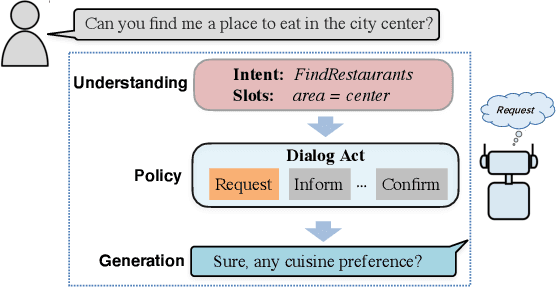
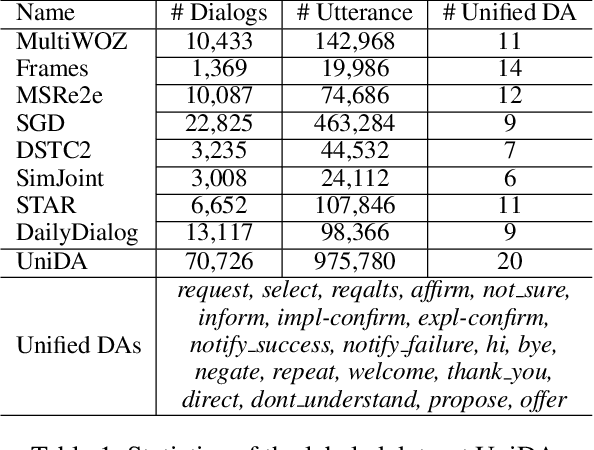

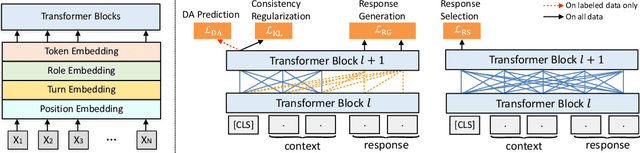
Pre-trained models have proved to be powerful in enhancing task-oriented dialog systems. However, current pre-training methods mainly focus on enhancing dialog understanding and generation tasks while neglecting the exploitation of dialog policy. In this paper, we propose GALAXY, a novel pre-trained dialog model that explicitly learns dialog policy from limited labeled dialogs and large-scale unlabeled dialog corpora via semi-supervised learning. Specifically, we introduce a dialog act prediction task for policy optimization during pre-training and employ a consistency regularization term to refine the learned representation with the help of unlabeled dialogs. We also implement a gating mechanism to weigh suitable unlabeled dialog samples. Empirical results show that GALAXY substantially improves the performance of task-oriented dialog systems, and achieves new state-of-the-art results on benchmark datasets: In-Car, MultiWOZ2.0 and MultiWOZ2.1, improving their end-to-end combined scores by 2.5, 5.3 and 5.5 points, respectively. We also show that GALAXY has a stronger few-shot ability than existing models under various low-resource settings.
Knowledge Based Multilingual Language Model
Nov 22, 2021
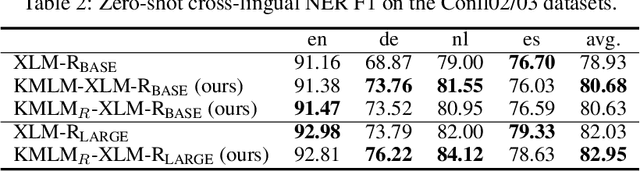
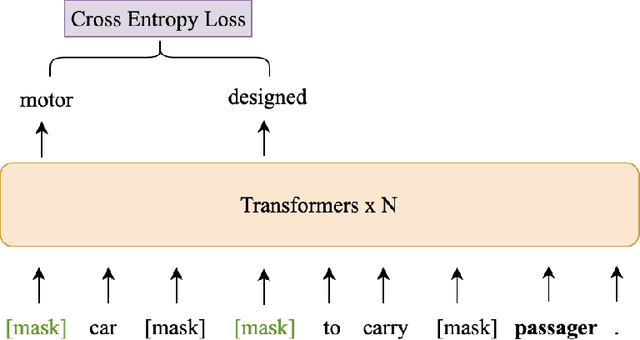
Knowledge enriched language representation learning has shown promising performance across various knowledge-intensive NLP tasks. However, existing knowledge based language models are all trained with monolingual knowledge graph data, which limits their application to more languages. In this work, we present a novel framework to pretrain knowledge based multilingual language models (KMLMs). We first generate a large amount of code-switched synthetic sentences and reasoning-based multilingual training data using the Wikidata knowledge graphs. Then based on the intra- and inter-sentence structures of the generated data, we design pretraining tasks to facilitate knowledge learning, which allows the language models to not only memorize the factual knowledge but also learn useful logical patterns. Our pretrained KMLMs demonstrate significant performance improvements on a wide range of knowledge-intensive cross-lingual NLP tasks, including named entity recognition, factual knowledge retrieval, relation classification, and a new task designed by us, namely, logic reasoning. Our code and pretrained language models will be made publicly available.
Achieving Human Parity on Visual Question Answering
Nov 19, 2021
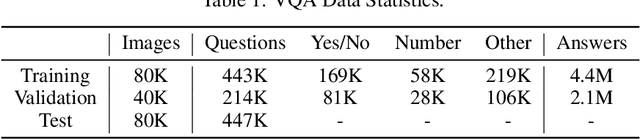
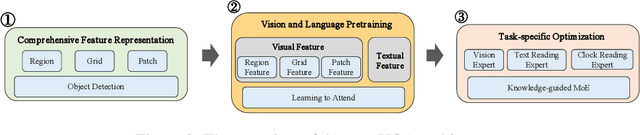
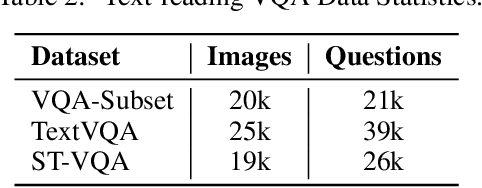
The Visual Question Answering (VQA) task utilizes both visual image and language analysis to answer a textual question with respect to an image. It has been a popular research topic with an increasing number of real-world applications in the last decade. This paper describes our recent research of AliceMind-MMU (ALIbaba's Collection of Encoder-decoders from Machine IntelligeNce lab of Damo academy - MultiMedia Understanding) that obtains similar or even slightly better results than human being does on VQA. This is achieved by systematically improving the VQA pipeline including: (1) pre-training with comprehensive visual and textual feature representation; (2) effective cross-modal interaction with learning to attend; and (3) A novel knowledge mining framework with specialized expert modules for the complex VQA task. Treating different types of visual questions with corresponding expertise needed plays an important role in boosting the performance of our VQA architecture up to the human level. An extensive set of experiments and analysis are conducted to demonstrate the effectiveness of the new research work.
GlobalWoZ: Globalizing MultiWoZ to Develop Multilingual Task-Oriented Dialogue Systems
Oct 14, 2021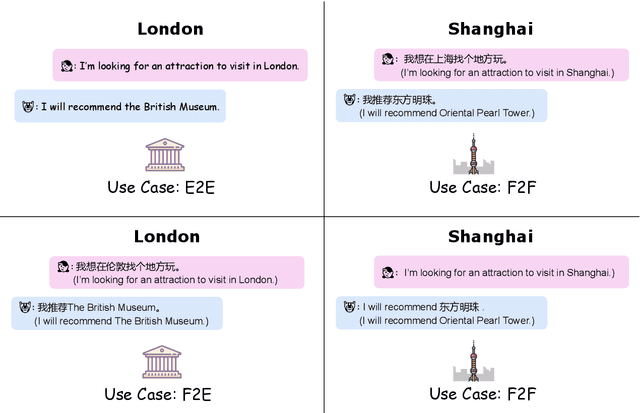
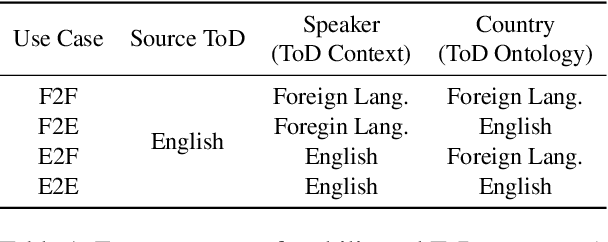
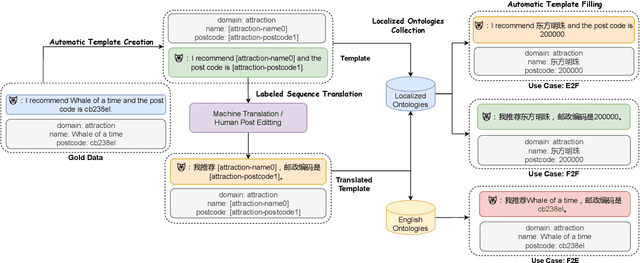
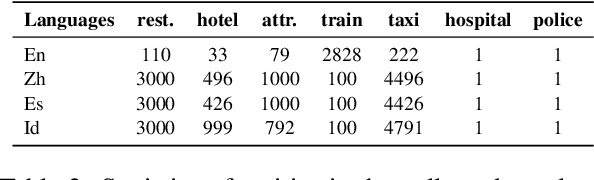
Much recent progress in task-oriented dialogue (ToD) systems has been driven by available annotation data across multiple domains for training. Over the last few years, there has been a move towards data curation for multilingual ToD systems that are applicable to serve people speaking different languages. However, existing multilingual ToD datasets either have a limited coverage of languages due to the high cost of data curation, or ignore the fact that dialogue entities barely exist in countries speaking these languages. To tackle these limitations, we introduce a novel data curation method that generates GlobalWoZ -- a large-scale multilingual ToD dataset globalized from an English ToD dataset for three unexplored use cases. Our method is based on translating dialogue templates and filling them with local entities in the target-language countries. We release our dataset as well as a set of strong baselines to encourage research on learning multilingual ToD systems for real use cases.