 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMake-It-Vivid: Dressing Your Animatable Biped Cartoon Characters from Text
Mar 25, 2024



Creating and animating 3D biped cartoon characters is crucial and valuable in various applications. Compared with geometry, the diverse texture design plays an important role in making 3D biped cartoon characters vivid and charming. Therefore, we focus on automatic texture design for cartoon characters based on input instructions. This is challenging for domain-specific requirements and a lack of high-quality data. To address this challenge, we propose Make-It-Vivid, the first attempt to enable high-quality texture generation from text in UV space. We prepare a detailed text-texture paired data for 3D characters by using vision-question-answering agents. Then we customize a pretrained text-to-image model to generate texture map with template structure while preserving the natural 2D image knowledge. Furthermore, to enhance fine-grained details, we propose a novel adversarial learning scheme to shorten the domain gap between original dataset and realistic texture domain. Extensive experiments show that our approach outperforms current texture generation methods, resulting in efficient character texturing and faithful generation with prompts. Besides, we showcase various applications such as out of domain generation and texture stylization. We also provide an efficient generation system for automatic text-guided textured character generation and animation.
Real-IAD: A Real-World Multi-View Dataset for Benchmarking Versatile Industrial Anomaly Detection
Mar 19, 2024Industrial anomaly detection (IAD) has garnered significant attention and experienced rapid development. However, the recent development of IAD approach has encountered certain difficulties due to dataset limitations. On the one hand, most of the state-of-the-art methods have achieved saturation (over 99% in AUROC) on mainstream datasets such as MVTec, and the differences of methods cannot be well distinguished, leading to a significant gap between public datasets and actual application scenarios. On the other hand, the research on various new practical anomaly detection settings is limited by the scale of the dataset, posing a risk of overfitting in evaluation results. Therefore, we propose a large-scale, Real-world, and multi-view Industrial Anomaly Detection dataset, named Real-IAD, which contains 150K high-resolution images of 30 different objects, an order of magnitude larger than existing datasets. It has a larger range of defect area and ratio proportions, making it more challenging than previous datasets. To make the dataset closer to real application scenarios, we adopted a multi-view shooting method and proposed sample-level evaluation metrics. In addition, beyond the general unsupervised anomaly detection setting, we propose a new setting for Fully Unsupervised Industrial Anomaly Detection (FUIAD) based on the observation that the yield rate in industrial production is usually greater than 60%, which has more practical application value. Finally, we report the results of popular IAD methods on the Real-IAD dataset, providing a highly challenging benchmark to promote the development of the IAD field.
Exploring Safety Generalization Challenges of Large Language Models via Code
Mar 14, 2024The rapid advancement of Large Language Models (LLMs) has brought about remarkable capabilities in natural language processing but also raised concerns about their potential misuse. While strategies like supervised fine-tuning and reinforcement learning from human feedback have enhanced their safety, these methods primarily focus on natural languages, which may not generalize to other domains. This paper introduces CodeAttack, a framework that transforms natural language inputs into code inputs, presenting a novel environment for testing the safety generalization of LLMs. Our comprehensive studies on state-of-the-art LLMs including GPT-4, Claude-2, and Llama-2 series reveal a common safety vulnerability of these models against code input: CodeAttack consistently bypasses the safety guardrails of all models more than 80% of the time. Furthermore, we find that a larger distribution gap between CodeAttack and natural language leads to weaker safety generalization, such as encoding natural language input with data structures or using less popular programming languages. These findings highlight new safety risks in the code domain and the need for more robust safety alignment algorithms to match the code capabilities of LLMs.
DEMOS: Dynamic Environment Motion Synthesis in 3D Scenes via Local Spherical-BEV Perception
Mar 04, 2024



Motion synthesis in real-world 3D scenes has recently attracted much attention. However, the static environment assumption made by most current methods usually cannot be satisfied especially for real-time motion synthesis in scanned point cloud scenes, if multiple dynamic objects exist, e.g., moving persons or vehicles. To handle this problem, we propose the first Dynamic Environment MOtion Synthesis framework (DEMOS) to predict future motion instantly according to the current scene, and use it to dynamically update the latent motion for final motion synthesis. Concretely, we propose a Spherical-BEV perception method to extract local scene features that are specifically designed for instant scene-aware motion prediction. Then, we design a time-variant motion blending to fuse the new predicted motions into the latent motion, and the final motion is derived from the updated latent motions, benefitting both from motion-prior and iterative methods. We unify the data format of two prevailing datasets, PROX and GTA-IM, and take them for motion synthesis evaluation in 3D scenes. We also assess the effectiveness of the proposed method in dynamic environments from GTA-IM and Semantic3D to check the responsiveness. The results show our method outperforms previous works significantly and has great performance in handling dynamic environments.
SimAda: A Simple Unified Framework for Adapting Segment Anything Model in Underperformed Scenes
Jan 31, 2024



Segment anything model (SAM) has demonstrated excellent generalization capabilities in common vision scenarios, yet lacking an understanding of specialized data. Although numerous works have focused on optimizing SAM for downstream tasks, these task-specific approaches usually limit the generalizability to other downstream tasks. In this paper, we aim to investigate the impact of the general vision modules on finetuning SAM and enable them to generalize across all downstream tasks. We propose a simple unified framework called SimAda for adapting SAM in underperformed scenes. Specifically, our framework abstracts the general modules of different methods into basic design elements, and we design four variants based on a shared theoretical framework. SimAda is simple yet effective, which removes all dataset-specific designs and focuses solely on general optimization, ensuring that SimAda can be applied to all SAM-based and even Transformer-based models. We conduct extensive experiments on nine datasets of six downstream tasks. The results demonstrate that SimAda significantly improves the performance of SAM on multiple downstream tasks and achieves state-of-the-art performance on most of them, without requiring task-specific designs. Code is available at: https://github.com/zongzi13545329/SimAda
Continuous Piecewise-Affine Based Motion Model for Image Animation
Jan 17, 2024Image animation aims to bring static images to life according to driving videos and create engaging visual content that can be used for various purposes such as animation, entertainment, and education. Recent unsupervised methods utilize affine and thin-plate spline transformations based on keypoints to transfer the motion in driving frames to the source image. However, limited by the expressive power of the transformations used, these methods always produce poor results when the gap between the motion in the driving frame and the source image is large. To address this issue, we propose to model motion from the source image to the driving frame in highly-expressive diffeomorphism spaces. Firstly, we introduce Continuous Piecewise-Affine based (CPAB) transformation to model the motion and present a well-designed inference algorithm to generate CPAB transformation from control keypoints. Secondly, we propose a SAM-guided keypoint semantic loss to further constrain the keypoint extraction process and improve the semantic consistency between the corresponding keypoints on the source and driving images. Finally, we design a structure alignment loss to align the structure-related features extracted from driving and generated images, thus helping the generator generate results that are more consistent with the driving action. Extensive experiments on four datasets demonstrate the effectiveness of our method against state-of-the-art competitors quantitatively and qualitatively. Code will be publicly available at: https://github.com/DevilPG/AAAI2024-CPABMM.
Class-Imbalanced Semi-Supervised Learning for Large-Scale Point Cloud Semantic Segmentation via Decoupling Optimization
Jan 13, 2024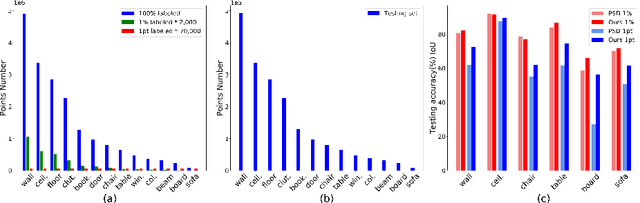
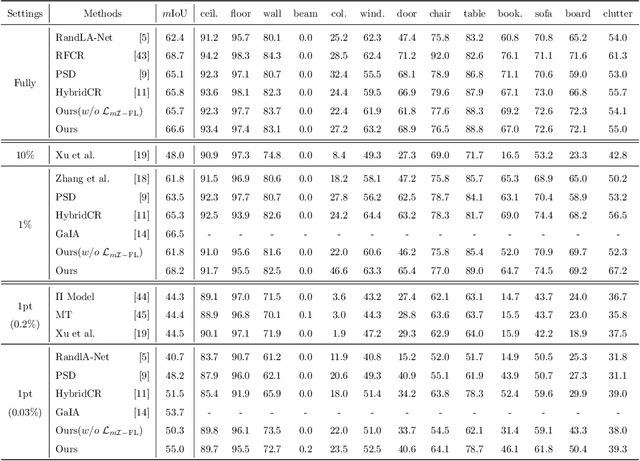
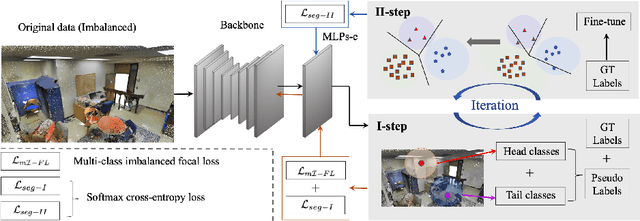

Semi-supervised learning (SSL), thanks to the significant reduction of data annotation costs, has been an active research topic for large-scale 3D scene understanding. However, the existing SSL-based methods suffer from severe training bias, mainly due to class imbalance and long-tail distributions of the point cloud data. As a result, they lead to a biased prediction for the tail class segmentation. In this paper, we introduce a new decoupling optimization framework, which disentangles feature representation learning and classifier in an alternative optimization manner to shift the bias decision boundary effectively. In particular, we first employ two-round pseudo-label generation to select unlabeled points across head-to-tail classes. We further introduce multi-class imbalanced focus loss to adaptively pay more attention to feature learning across head-to-tail classes. We fix the backbone parameters after feature learning and retrain the classifier using ground-truth points to update its parameters. Extensive experiments demonstrate the effectiveness of our method outperforming previous state-of-the-art methods on both indoor and outdoor 3D point cloud datasets (i.e., S3DIS, ScanNet-V2, Semantic3D, and SemanticKITTI) using 1% and 1pt evaluation.
BA-SAM: Scalable Bias-Mode Attention Mask for Segment Anything Model
Jan 08, 2024



In this paper, we address the challenge of image resolution variation for the Segment Anything Model (SAM). SAM, known for its zero-shot generalizability, exhibits a performance degradation when faced with datasets with varying image sizes. Previous approaches tend to resize the image to a fixed size or adopt structure modifications, hindering the preservation of SAM's rich prior knowledge. Besides, such task-specific tuning necessitates a complete retraining of the model, which is cost-expensive and unacceptable for deployment in the downstream tasks. In this paper, we reformulate this issue as a length extrapolation problem, where token sequence length varies while maintaining a consistent patch size for images of different sizes. To this end, we propose Scalable Bias-Mode Attention Mask (BA-SAM) to enhance SAM's adaptability to varying image resolutions while eliminating the need for structure modifications. Firstly, we introduce a new scaling factor to ensure consistent magnitude in the attention layer's dot product values when the token sequence length changes. Secondly, we present a bias-mode attention mask that allows each token to prioritize neighboring information, mitigating the impact of untrained distant information. Our BA-SAM demonstrates efficacy in two scenarios: zero-shot and fine-tuning. Extensive evaluation on diverse datasets, including DIS5K, DUTS, ISIC, COD10K, and COCO, reveals its ability to significantly mitigate performance degradation in the zero-shot setting and achieve state-of-the-art performance with minimal fine-tuning. Furthermore, we propose a generalized model and benchmark, showcasing BA-SAM's generalizability across all four datasets simultaneously.
A Theory of Non-Acyclic Generative Flow Networks
Dec 23, 2023



GFlowNets is a novel flow-based method for learning a stochastic policy to generate objects via a sequence of actions and with probability proportional to a given positive reward. We contribute to relaxing hypotheses limiting the application range of GFlowNets, in particular: acyclicity (or lack thereof). To this end, we extend the theory of GFlowNets on measurable spaces which includes continuous state spaces without cycle restrictions, and provide a generalization of cycles in this generalized context. We show that losses used so far push flows to get stuck into cycles and we define a family of losses solving this issue. Experiments on graphs and continuous tasks validate those principles.
COTR: Compact Occupancy TRansformer for Vision-based 3D Occupancy Prediction
Dec 04, 2023



The autonomous driving community has shown significant interest in 3D occupancy prediction, driven by its exceptional geometric perception and general object recognition capabilities. To achieve this, current works try to construct a Tri-Perspective View (TPV) or Occupancy (OCC) representation extending from the Bird-Eye-View perception. However, compressed views like TPV representation lose 3D geometry information while raw and sparse OCC representation requires heavy but reducant computational costs. To address the above limitations, we propose Compact Occupancy TRansformer (COTR), with a geometry-aware occupancy encoder and a semantic-aware group decoder to reconstruct a compact 3D OCC representation. The occupancy encoder first generates a compact geometrical OCC feature through efficient explicit-implicit view transformation. Then, the occupancy decoder further enhances the semantic discriminability of the compact OCC representation by a coarse-to-fine semantic grouping strategy. Empirical experiments show that there are evident performance gains across multiple baselines, e.g., COTR outperforms baselines with a relative improvement of 8%-15%, demonstrating the superiority of our method.