 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRankGR: Rank-Enhanced Generative Retrieval with Listwise Direct Preference Optimization in Recommendation
Feb 09, 2026Generative retrieval (GR) has emerged as a promising paradigm in recommendation systems by autoregressively decoding identifiers of target items. Despite its potential, current approaches typically rely on the next-token prediction schema, which treats each token of the next interacted items as the sole target. This narrow focus 1) limits their ability to capture the nuanced structure of user preferences, and 2) overlooks the deep interaction between decoded identifiers and user behavior sequences. In response to these challenges, we propose RankGR, a Rank-enhanced Generative Retrieval method that incorporates listwise direct preference optimization for recommendation. RankGR decomposes the retrieval process into two complementary stages: the Initial Assessment Phase (IAP) and the Refined Scoring Phase (RSP). In IAP, we incorporate a novel listwise direct preference optimization strategy into GR, thus facilitating a more comprehensive understanding of the hierarchical user preferences and more effective partial-order modeling. The RSP then refines the top-λ candidates generated by IAP with interactions towards input sequences using a lightweight scoring module, leading to more precise candidate evaluation. Both phases are jointly optimized under a unified GR model, ensuring consistency and efficiency. Additionally, we implement several practical improvements in training and deployment, ultimately achieving a real-time system capable of handling nearly ten thousand requests per second. Extensive offline performance on both research and industrial datasets, as well as the online gains on the "Guess You Like" section of Taobao, validate the effectiveness and scalability of RankGR.
Real-IAD: A Real-World Multi-View Dataset for Benchmarking Versatile Industrial Anomaly Detection
Mar 19, 2024Industrial anomaly detection (IAD) has garnered significant attention and experienced rapid development. However, the recent development of IAD approach has encountered certain difficulties due to dataset limitations. On the one hand, most of the state-of-the-art methods have achieved saturation (over 99% in AUROC) on mainstream datasets such as MVTec, and the differences of methods cannot be well distinguished, leading to a significant gap between public datasets and actual application scenarios. On the other hand, the research on various new practical anomaly detection settings is limited by the scale of the dataset, posing a risk of overfitting in evaluation results. Therefore, we propose a large-scale, Real-world, and multi-view Industrial Anomaly Detection dataset, named Real-IAD, which contains 150K high-resolution images of 30 different objects, an order of magnitude larger than existing datasets. It has a larger range of defect area and ratio proportions, making it more challenging than previous datasets. To make the dataset closer to real application scenarios, we adopted a multi-view shooting method and proposed sample-level evaluation metrics. In addition, beyond the general unsupervised anomaly detection setting, we propose a new setting for Fully Unsupervised Industrial Anomaly Detection (FUIAD) based on the observation that the yield rate in industrial production is usually greater than 60%, which has more practical application value. Finally, we report the results of popular IAD methods on the Real-IAD dataset, providing a highly challenging benchmark to promote the development of the IAD field.
High-throughput discovery of chemical structure-polarity relationships combining automation and machine learning techniques
Feb 12, 2022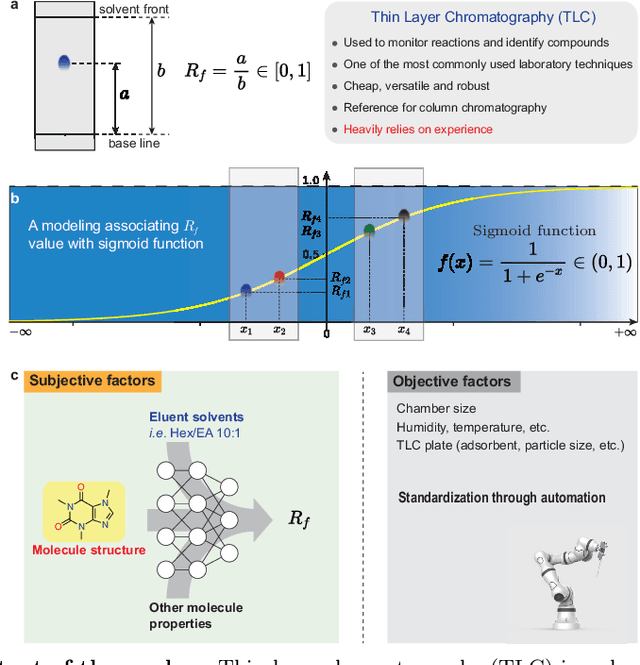

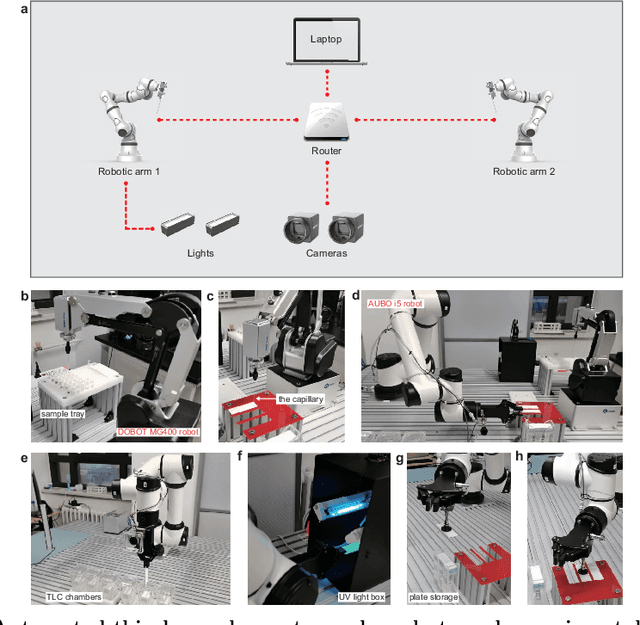

As an essential attribute of organic compounds, polarity has a profound influence on many molecular properties such as solubility and phase transition temperature. Thin layer chromatography (TLC) represents a commonly used technique for polarity measurement. However, current TLC analysis presents several problems, including the need for a large number of attempts to obtain suitable conditions, as well as irreproducibility due to non-standardization. Herein, we describe an automated experiment system for TLC analysis. This system is designed to conduct TLC analysis automatically, facilitating high-throughput experimentation by collecting large experimental data under standardized conditions. Using these datasets, machine learning (ML) methods are employed to construct surrogate models correlating organic compounds' structures and their polarity using retardation factor (Rf). The trained ML models are able to predict the Rf value curve of organic compounds with high accuracy. Furthermore, the constitutive relationship between the compound and its polarity can also be discovered through these modeling methods, and the underlying mechanism is rationalized through adsorption theories. The trained ML models not only reduce the need for empirical optimization currently required for TLC analysis, but also provide general guidelines for the selection of conditions, making TLC an easily accessible tool for the broad scientific community.