 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStable, Fast and Accurate: Kernelized Attention with Relative Positional Encoding
Jun 23, 2021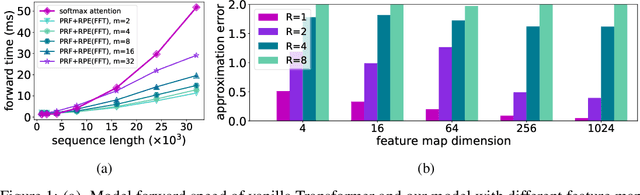
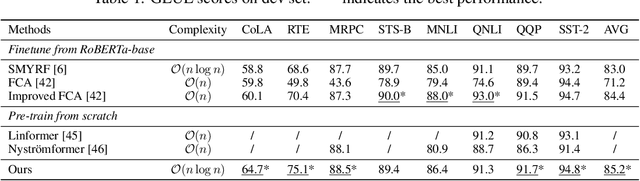


The attention module, which is a crucial component in Transformer, cannot scale efficiently to long sequences due to its quadratic complexity. Many works focus on approximating the dot-then-exponentiate softmax function in the original attention, leading to sub-quadratic or even linear-complexity Transformer architectures. However, we show that these methods cannot be applied to more powerful attention modules that go beyond the dot-then-exponentiate style, e.g., Transformers with relative positional encoding (RPE). Since in many state-of-the-art models, relative positional encoding is used as default, designing efficient Transformers that can incorporate RPE is appealing. In this paper, we propose a novel way to accelerate attention calculation for Transformers with RPE on top of the kernelized attention. Based upon the observation that relative positional encoding forms a Toeplitz matrix, we mathematically show that kernelized attention with RPE can be calculated efficiently using Fast Fourier Transform (FFT). With FFT, our method achieves $\mathcal{O}(n\log n)$ time complexity. Interestingly, we further demonstrate that properly using relative positional encoding can mitigate the training instability problem of vanilla kernelized attention. On a wide range of tasks, we empirically show that our models can be trained from scratch without any optimization issues. The learned model performs better than many efficient Transformer variants and is faster than standard Transformer in the long-sequence regime.
A Unified Framework for Conservative Exploration
Jun 22, 2021
We study bandits and reinforcement learning (RL) subject to a conservative constraint where the agent is asked to perform at least as well as a given baseline policy. This setting is particular relevant in real-world domains including digital marketing, healthcare, production, finance, etc. For multi-armed bandits, linear bandits and tabular RL, specialized algorithms and theoretical analyses were proposed in previous work. In this paper, we present a unified framework for conservative bandits and RL, in which our core technique is to calculate the necessary and sufficient budget obtained from running the baseline policy. For lower bounds, our framework gives a black-box reduction that turns a certain lower bound in the nonconservative setting into a new lower bound in the conservative setting. We strengthen the existing lower bound for conservative multi-armed bandits and obtain new lower bounds for conservative linear bandits, tabular RL and low-rank MDP. For upper bounds, our framework turns a certain nonconservative upper-confidence-bound (UCB) algorithm into a conservative algorithm with a simple analysis. For multi-armed bandits, linear bandits and tabular RL, our new upper bounds tighten or match existing ones with significantly simpler analyses. We also obtain a new upper bound for conservative low-rank MDP.
FedCM: Federated Learning with Client-level Momentum
Jun 21, 2021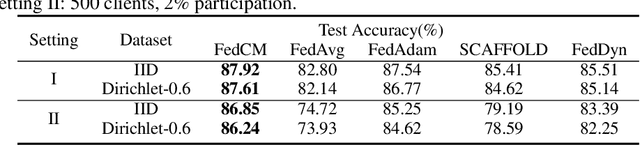
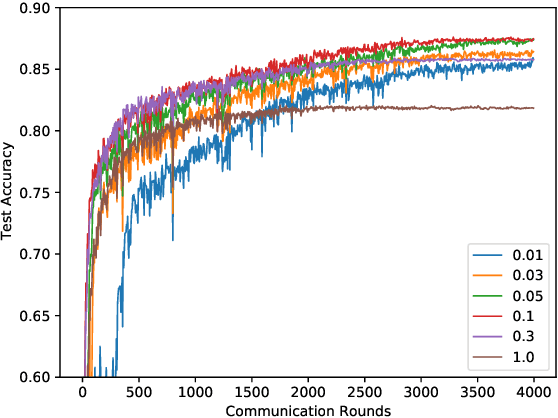
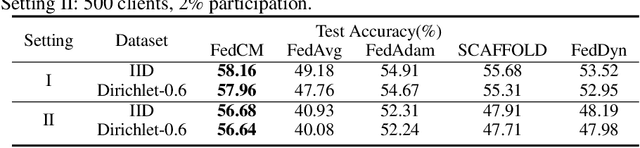
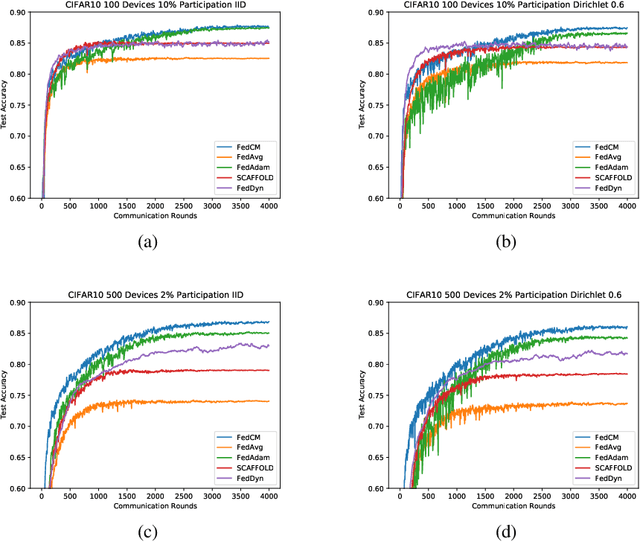
Federated Learning is a distributed machine learning approach which enables model training without data sharing. In this paper, we propose a new federated learning algorithm, Federated Averaging with Client-level Momentum (FedCM), to tackle problems of partial participation and client heterogeneity in real-world federated learning applications. FedCM aggregates global gradient information in previous communication rounds and modifies client gradient descent with a momentum-like term, which can effectively correct the bias and improve the stability of local SGD. We provide theoretical analysis to highlight the benefits of FedCM. We also perform extensive empirical studies and demonstrate that FedCM achieves superior performance in various tasks and is robust to different levels of client numbers, participation rate and client heterogeneity.
JointGT: Graph-Text Joint Representation Learning for Text Generation from Knowledge Graphs
Jun 19, 2021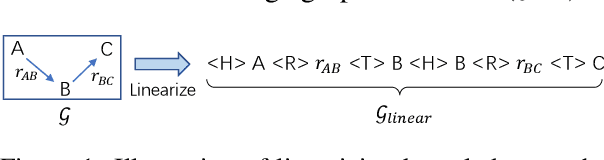

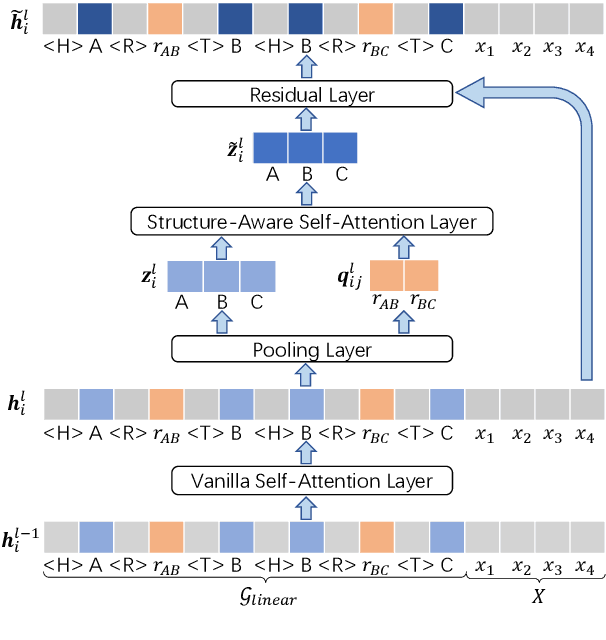
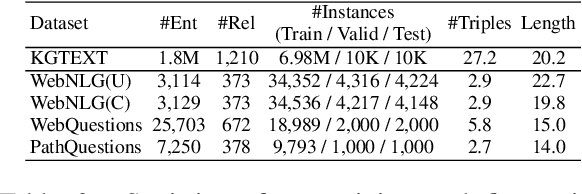
Existing pre-trained models for knowledge-graph-to-text (KG-to-text) generation simply fine-tune text-to-text pre-trained models such as BART or T5 on KG-to-text datasets, which largely ignore the graph structure during encoding and lack elaborate pre-training tasks to explicitly model graph-text alignments. To tackle these problems, we propose a graph-text joint representation learning model called JointGT. During encoding, we devise a structure-aware semantic aggregation module which is plugged into each Transformer layer to preserve the graph structure. Furthermore, we propose three new pre-training tasks to explicitly enhance the graph-text alignment including respective text / graph reconstruction, and graph-text alignment in the embedding space via Optimal Transport. Experiments show that JointGT obtains new state-of-the-art performance on various KG-to-text datasets.
Towards a Theoretical Framework of Out-of-Distribution Generalization
Jun 13, 2021
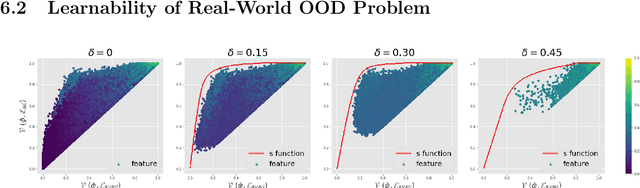
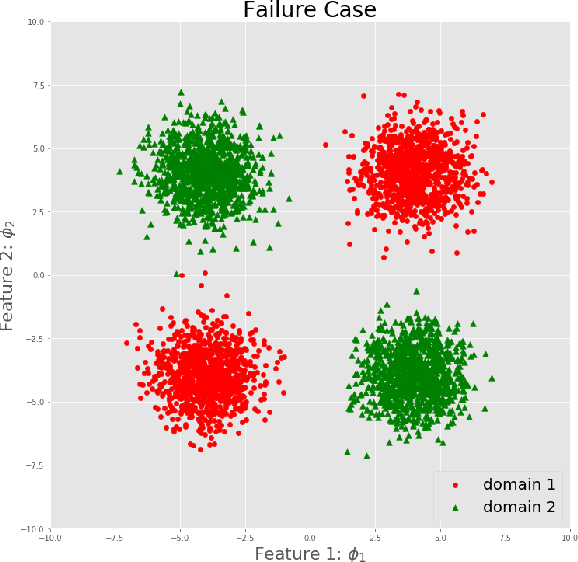

Generalization to out-of-distribution (OOD) data, or domain generalization, is one of the central problems in modern machine learning. Recently, there is a surge of attempts to propose algorithms for OOD that mainly build upon the idea of extracting invariant features. Although intuitively reasonable, theoretical understanding of what kind of invariance can guarantee OOD generalization is still limited, and generalization to arbitrary out-of-distribution is clearly impossible. In this work, we take the first step towards rigorous and quantitative definitions of 1) what is OOD; and 2) what does it mean by saying an OOD problem is learnable. We also introduce a new concept of expansion function, which characterizes to what extent the variance is amplified in the test domains over the training domains, and therefore give a quantitative meaning of invariant features. Based on these, we prove OOD generalization error bounds. It turns out that OOD generalization largely depends on the expansion function. As recently pointed out by Gulrajani and Lopez-Paz (2020), any OOD learning algorithm without a model selection module is incomplete. Our theory naturally induces a model selection criterion. Extensive experiments on benchmark OOD datasets demonstrate that our model selection criterion has a significant advantage over baselines.
Data-Driven Multiscale Design of Cellular Composites with Multiclass Microstructures for Natural Frequency Maximization
Jun 11, 2021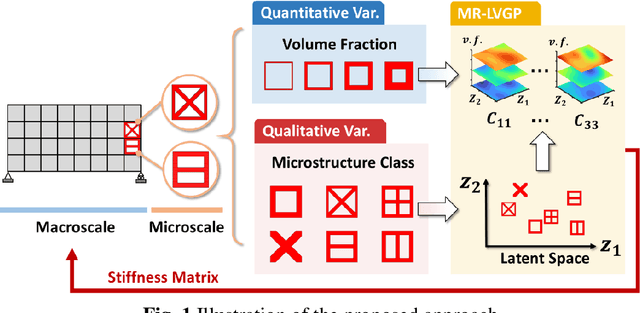
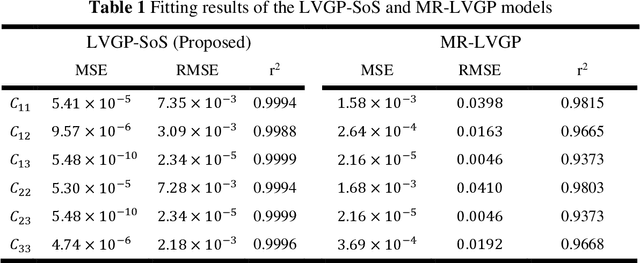
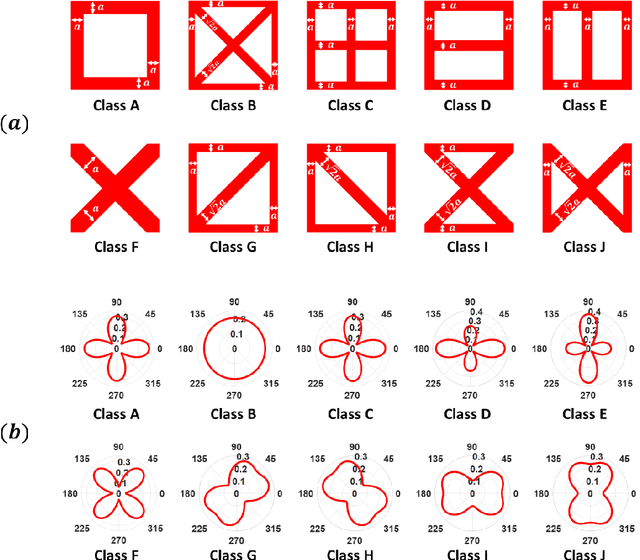
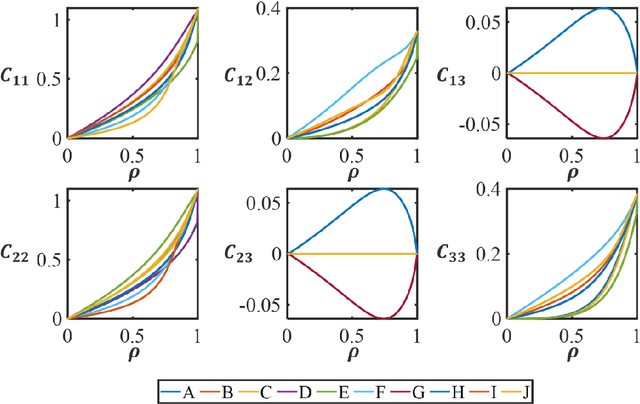
For natural frequency optimization of engineering structures, cellular composites have been shown to possess an edge over solid. However, existing multiscale design methods for cellular composites are either computationally exhaustive or confined to a single class of microstructures. In this paper, we propose a data-driven topology optimization (TO) approach to enable the multiscale design of cellular structures with various choices of microstructure classes. The key component is a newly proposed latent-variable Gaussian process (LVGP) model through which different classes of microstructures are mapped into a low-dimensional continuous latent space. It provides an interpretable distance metric between classes and captures their effects on the homogenized stiffness tensors. By introducing latent vectors as design variables, a differentiable transition of stiffness matrix between classes can be easily achieved with an analytical gradient. After integrating LVGP with the density-based TO, an efficient data-driven cellular composite optimization process is developed to enable concurrent exploration of microstructure concepts and the associated volume fractions for natural frequency optimization. Examples reveal that the proposed cellular designs with multiclass microstructures achieve higher natural frequencies than both single-scale and single-class designs. This framework can be easily extended to other multi-scale TO problems, such as thermal compliance and dynamic response optimization.
SAT: 2D Semantics Assisted Training for 3D Visual Grounding
May 24, 2021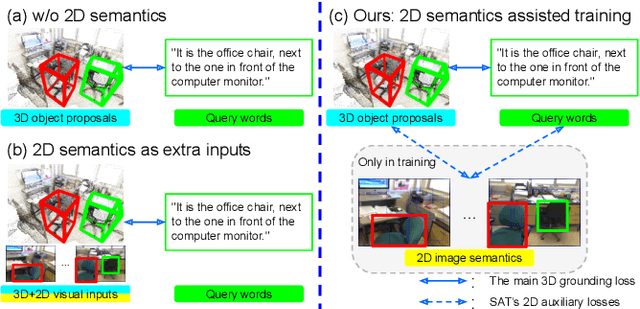
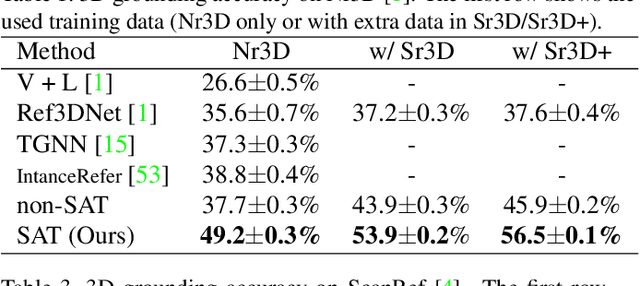
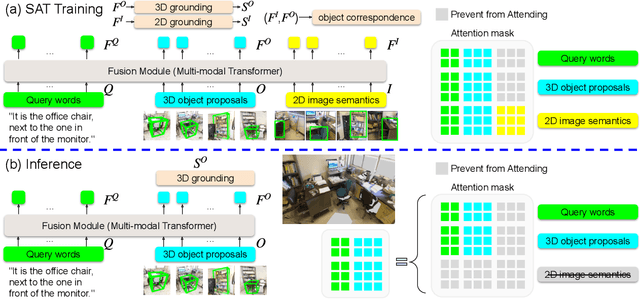
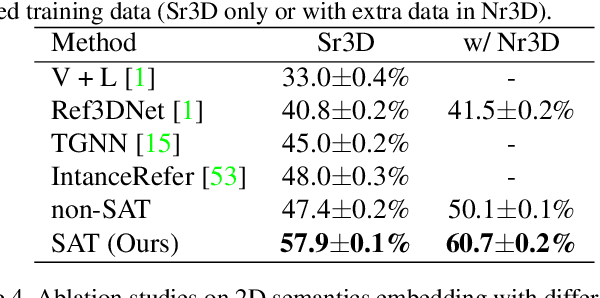
3D visual grounding aims at grounding a natural language description about a 3D scene, usually represented in the form of 3D point clouds, to the targeted object region. Point clouds are sparse, noisy, and contain limited semantic information compared with 2D images. These inherent limitations make the 3D visual grounding problem more challenging. In this study, we propose 2D Semantics Assisted Training (SAT) that utilizes 2D image semantics in the training stage to ease point-cloud-language joint representation learning and assist 3D visual grounding. The main idea is to learn auxiliary alignments between rich, clean 2D object representations and the corresponding objects or mentioned entities in 3D scenes. SAT takes 2D object semantics, i.e., object label, image feature, and 2D geometric feature, as the extra input in training but does not require such inputs during inference. By effectively utilizing 2D semantics in training, our approach boosts the accuracy on the Nr3D dataset from 37.7% to 49.2%, which significantly surpasses the non-SAT baseline with the identical network architecture and inference input. Our approach outperforms the state of the art by large margins on multiple 3D visual grounding datasets, i.e., +10.4% absolute accuracy on Nr3D, +9.9% on Sr3D, and +5.6% on ScanRef.
DAGN: Discourse-Aware Graph Network for Logical Reasoning
Apr 08, 2021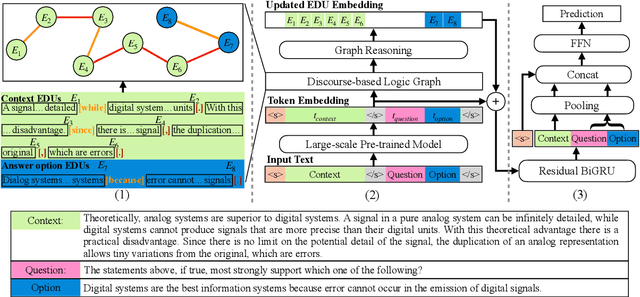
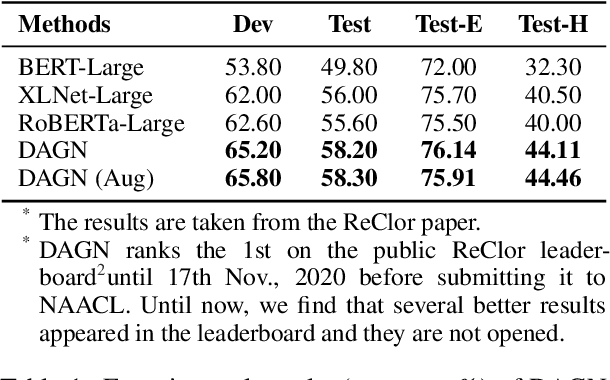
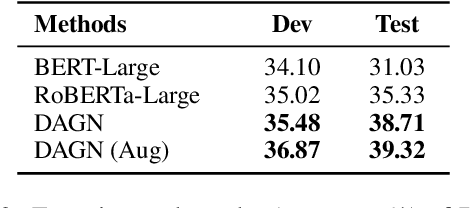

Recent QA with logical reasoning questions requires passage-level relations among the sentences. However, current approaches still focus on sentence-level relations interacting among tokens. In this work, we explore aggregating passage-level clues for solving logical reasoning QA by using discourse-based information. We propose a discourse-aware graph network (DAGN) that reasons relying on the discourse structure of the texts. The model encodes discourse information as a graph with elementary discourse units (EDUs) and discourse relations, and learns the discourse-aware features via a graph network for downstream QA tasks. Experiments are conducted on two logical reasoning QA datasets, ReClor and LogiQA, and our proposed DAGN achieves competitive results. The source code is available at https://github.com/Eleanor-H/DAGN.
Dense Relation Distillation with Context-aware Aggregation for Few-Shot Object Detection
Mar 30, 2021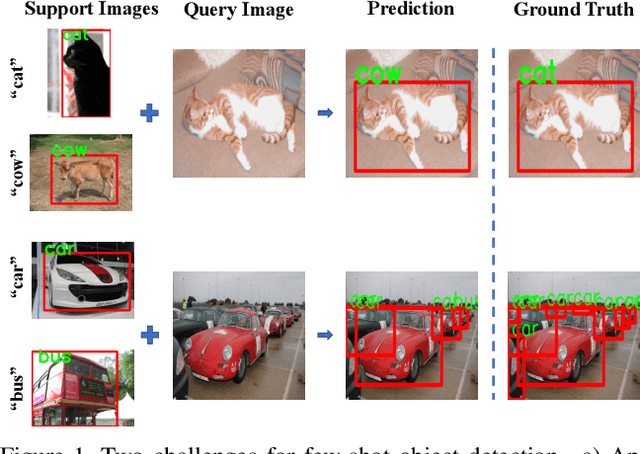
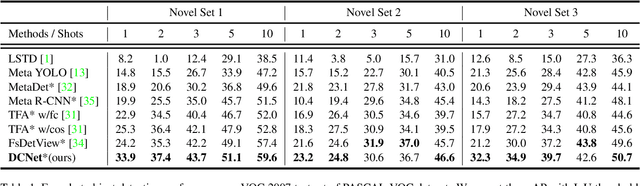
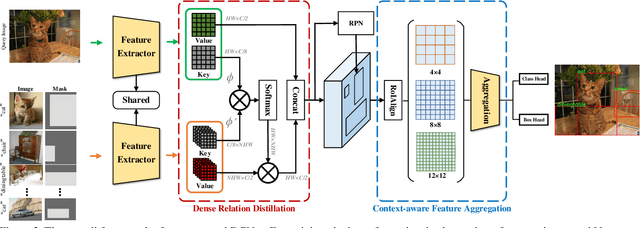
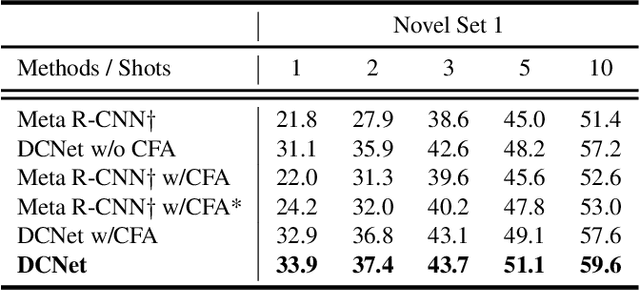
Conventional deep learning based methods for object detection require a large amount of bounding box annotations for training, which is expensive to obtain such high quality annotated data. Few-shot object detection, which learns to adapt to novel classes with only a few annotated examples, is very challenging since the fine-grained feature of novel object can be easily overlooked with only a few data available. In this work, aiming to fully exploit features of annotated novel object and capture fine-grained features of query object, we propose Dense Relation Distillation with Context-aware Aggregation (DCNet) to tackle the few-shot detection problem. Built on the meta-learning based framework, Dense Relation Distillation module targets at fully exploiting support features, where support features and query feature are densely matched, covering all spatial locations in a feed-forward fashion. The abundant usage of the guidance information endows model the capability to handle common challenges such as appearance changes and occlusions. Moreover, to better capture scale-aware features, Context-aware Aggregation module adaptively harnesses features from different scales for a more comprehensive feature representation. Extensive experiments illustrate that our proposed approach achieves state-of-the-art results on PASCAL VOC and MS COCO datasets. Code will be made available at https://github.com/hzhupku/DCNet.
Revisiting Language Encoding in Learning Multilingual Representations
Feb 16, 2021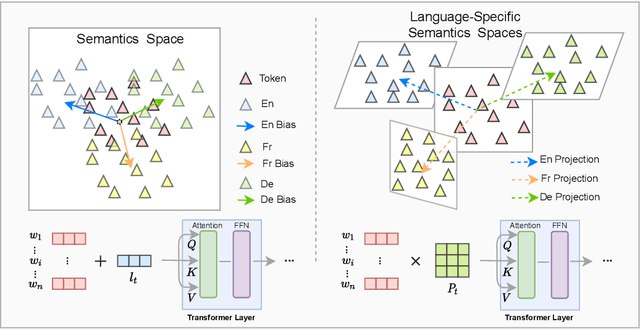
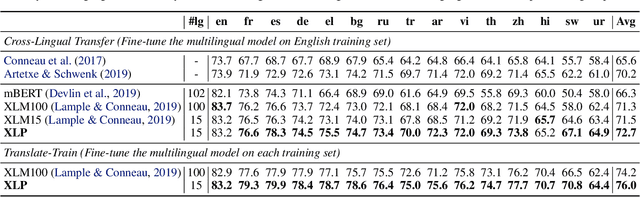
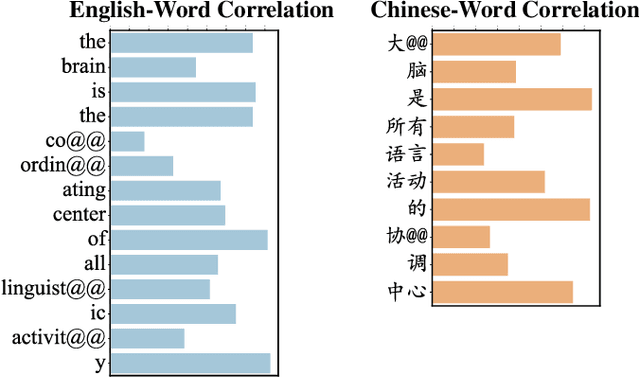

Transformer has demonstrated its great power to learn contextual word representations for multiple languages in a single model. To process multilingual sentences in the model, a learnable vector is usually assigned to each language, which is called "language embedding". The language embedding can be either added to the word embedding or attached at the beginning of the sentence. It serves as a language-specific signal for the Transformer to capture contextual representations across languages. In this paper, we revisit the use of language embedding and identify several problems in the existing formulations. By investigating the interaction between language embedding and word embedding in the self-attention module, we find that the current methods cannot reflect the language-specific word correlation well. Given these findings, we propose a new approach called Cross-lingual Language Projection (XLP) to replace language embedding. For a sentence, XLP projects the word embeddings into language-specific semantic space, and then the projected embeddings will be fed into the Transformer model to process with their language-specific meanings. In such a way, XLP achieves the purpose of appropriately encoding "language" in a multilingual Transformer model. Experimental results show that XLP can freely and significantly boost the model performance on extensive multilingual benchmark datasets. Codes and models will be released at https://github.com/lsj2408/XLP.