 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlowEval: A Consensus-Based Dialogue Evaluation Framework Using Segment Act Flows
Feb 14, 2022



Despite recent progress in open-domain dialogue evaluation, how to develop automatic metrics remains an open problem. We explore the potential of dialogue evaluation featuring dialog act information, which was hardly explicitly modeled in previous methods. However, defined at the utterance level in general, dialog act is of coarse granularity, as an utterance can contain multiple segments possessing different functions. Hence, we propose segment act, an extension of dialog act from utterance level to segment level, and crowdsource a large-scale dataset for it. To utilize segment act flows, sequences of segment acts, for evaluation, we develop the first consensus-based dialogue evaluation framework, FlowEval. This framework provides a reference-free approach for dialog evaluation by finding pseudo-references. Extensive experiments against strong baselines on three benchmark datasets demonstrate the effectiveness and other desirable characteristics of our FlowEval, pointing out a potential path for better dialogue evaluation.
Nearly Optimal Policy Optimization with Stable at Any Time Guarantee
Dec 22, 2021
Policy optimization methods are one of the most widely used classes of Reinforcement Learning (RL) algorithms. However, theoretical understanding of these methods remains insufficient. Even in the episodic (time-inhomogeneous) tabular setting, the state-of-the-art theoretical result of policy-based method in \citet{shani2020optimistic} is only $\tilde{O}(\sqrt{S^2AH^4K})$ where $S$ is the number of states, $A$ is the number of actions, $H$ is the horizon, and $K$ is the number of episodes, and there is a $\sqrt{SH}$ gap compared with the information theoretic lower bound $\tilde{\Omega}(\sqrt{SAH^3K})$. To bridge such a gap, we propose a novel algorithm Reference-based Policy Optimization with Stable at Any Time guarantee (\algnameacro), which features the property "Stable at Any Time". We prove that our algorithm achieves $\tilde{O}(\sqrt{SAH^3K} + \sqrt{AH^4K})$ regret. When $S > H$, our algorithm is minimax optimal when ignoring logarithmic factors. To our best knowledge, RPO-SAT is the first computationally efficient, nearly minimax optimal policy-based algorithm for tabular RL.
Remixing Functionally Graded Structures: Data-Driven Topology Optimization with Multiclass Shape Blending
Dec 01, 2021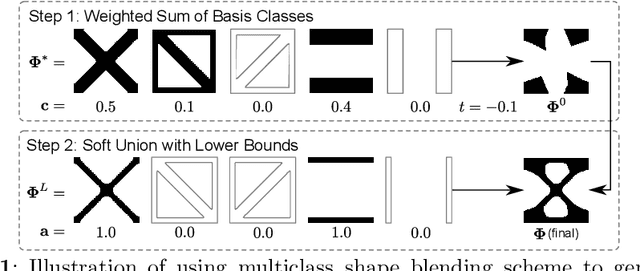
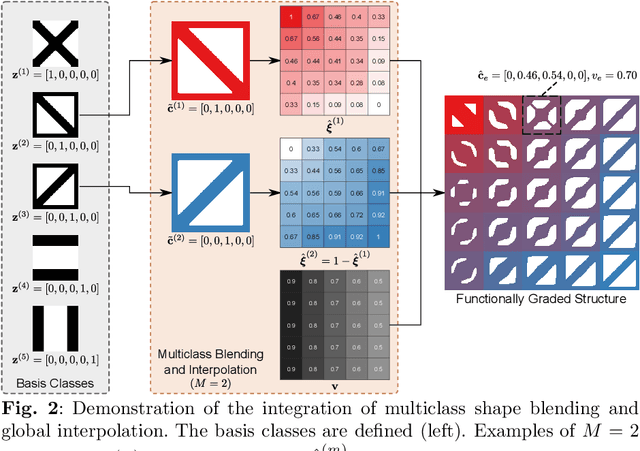
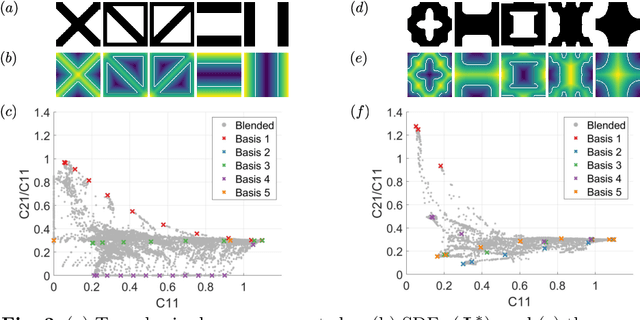
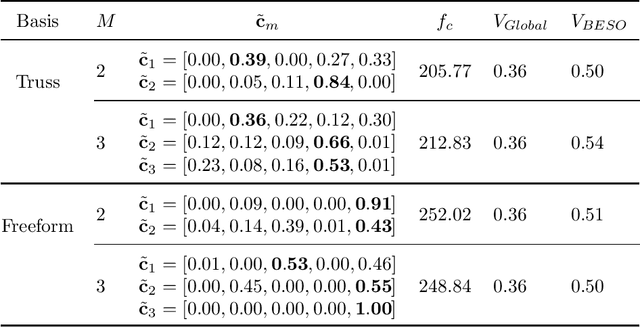
To create heterogeneous, multiscale structures with unprecedented functionalities, recent topology optimization approaches design either fully aperiodic systems or functionally graded structures, which compete in terms of design freedom and efficiency. We propose to inherit the advantages of both through a data-driven framework for multiclass functionally graded structures that mixes several families, i.e., classes, of microstructure topologies to create spatially-varying designs with guaranteed feasibility. The key is a new multiclass shape blending scheme that generates smoothly graded microstructures without requiring compatible classes or connectivity and feasibility constraints. Moreover, it transforms the microscale problem into an efficient, low-dimensional one without confining the design to predefined shapes. Compliance and shape matching examples using common truss geometries and diversity-based freeform topologies demonstrate the versatility of our framework, while studies on the effect of the number and diversity of classes illustrate the effectiveness. The generality of the proposed methods supports future extensions beyond the linear applications presented.
Breaking the Moments Condition Barrier: No-Regret Algorithm for Bandits with Super Heavy-Tailed Payoffs
Oct 26, 2021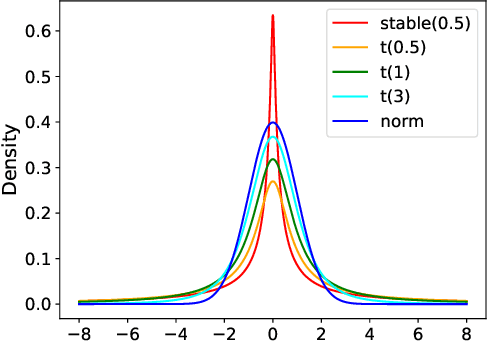
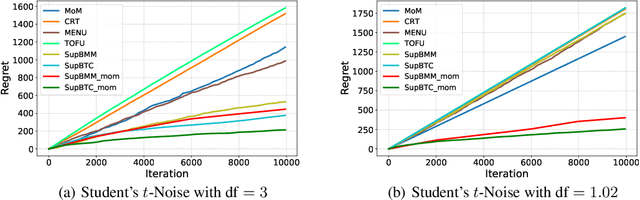
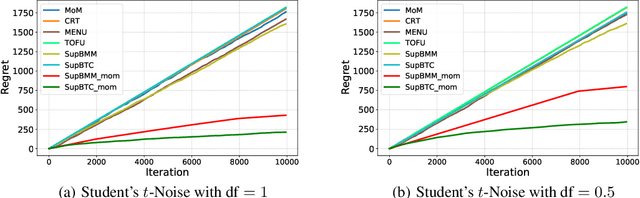
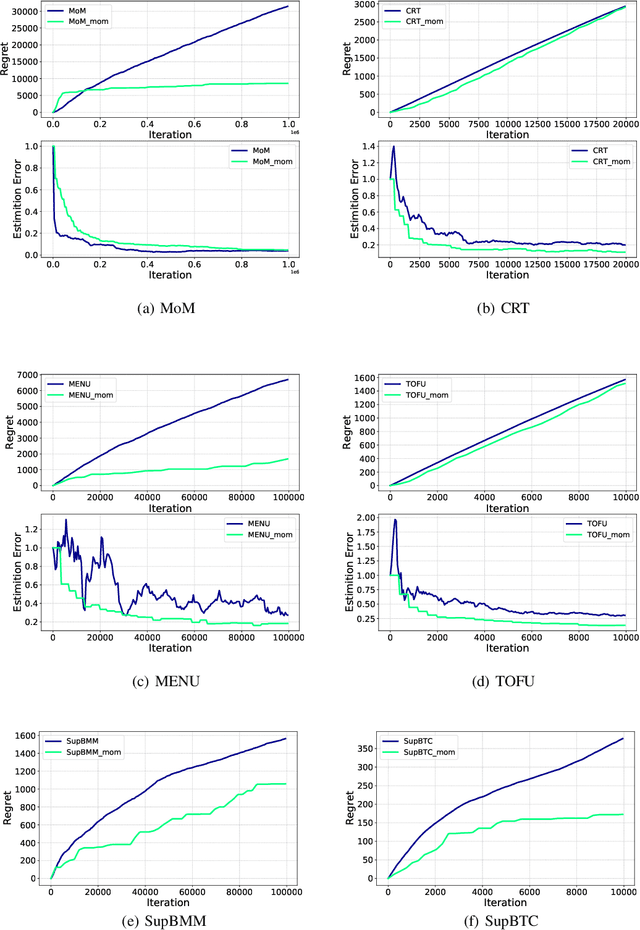
Despite a large amount of effort in dealing with heavy-tailed error in machine learning, little is known when moments of the error can become non-existential: the random noise $\eta$ satisfies Pr$\left[|\eta| > |y|\right] \le 1/|y|^{\alpha}$ for some $\alpha > 0$. We make the first attempt to actively handle such super heavy-tailed noise in bandit learning problems: We propose a novel robust statistical estimator, mean of medians, which estimates a random variable by computing the empirical mean of a sequence of empirical medians. We then present a generic reductionist algorithmic framework for solving bandit learning problems (including multi-armed and linear bandit problem): the mean of medians estimator can be applied to nearly any bandit learning algorithm as a black-box filtering for its reward signals and obtain similar regret bound as if the reward is sub-Gaussian. We show that the regret bound is near-optimal even with very heavy-tailed noise. We also empirically demonstrate the effectiveness of the proposed algorithm, which further corroborates our theoretical results.
Non-convex Distributionally Robust Optimization: Non-asymptotic Analysis
Oct 26, 2021
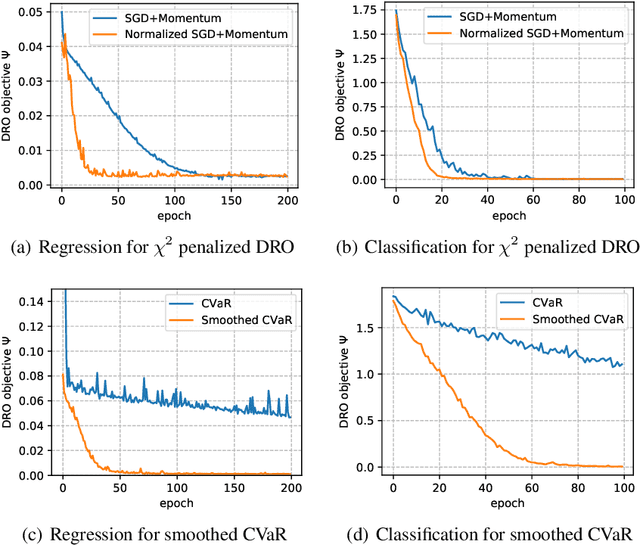


Distributionally robust optimization (DRO) is a widely-used approach to learn models that are robust against distribution shift. Compared with the standard optimization setting, the objective function in DRO is more difficult to optimize, and most of the existing theoretical results make strong assumptions on the loss function. In this work we bridge the gap by studying DRO algorithms for general smooth non-convex losses. By carefully exploiting the specific form of the DRO objective, we are able to provide non-asymptotic convergence guarantees even though the objective function is possibly non-convex, non-smooth and has unbounded gradient noise. In particular, we prove that a special algorithm called the mini-batch normalized gradient descent with momentum, can find an $\epsilon$ first-order stationary point within $O( \epsilon^{-4} )$ gradient complexity. We also discuss the conditional value-at-risk (CVaR) setting, where we propose a penalized DRO objective based on a smoothed version of the CVaR that allows us to obtain a similar convergence guarantee. We finally verify our theoretical results in a number of tasks and find that the proposed algorithm can consistently achieve prominent acceleration.
An Open Natural Language Processing Development Framework for EHR-based Clinical Research: A case demonstration using the National COVID Cohort Collaborative (N3C)
Oct 20, 2021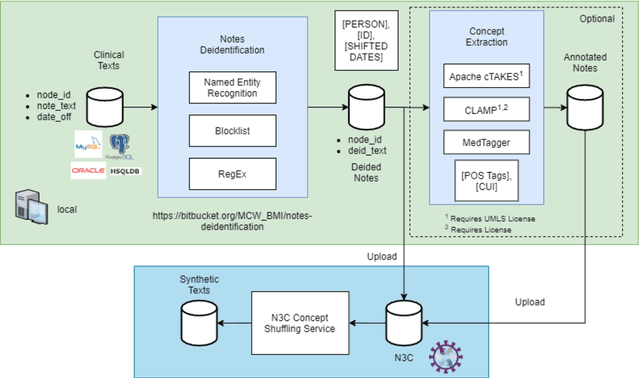

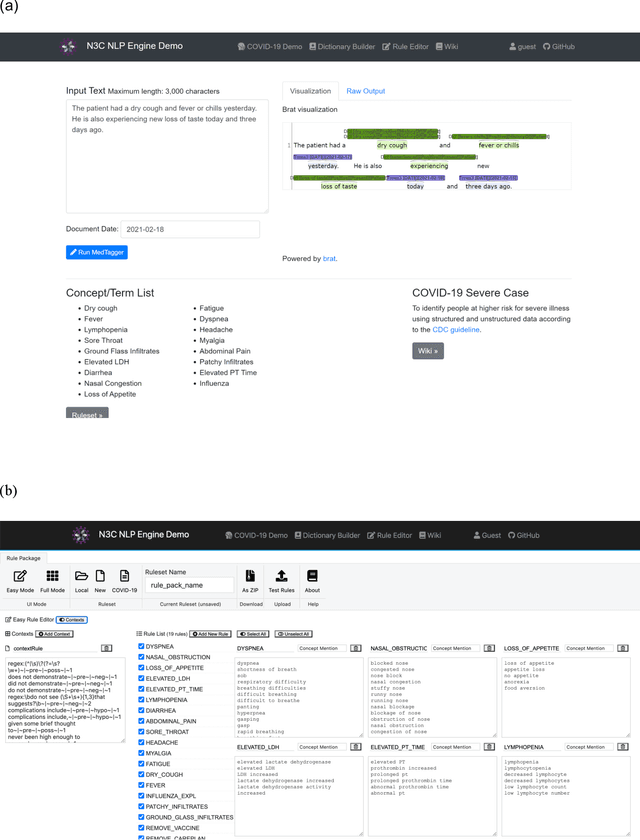
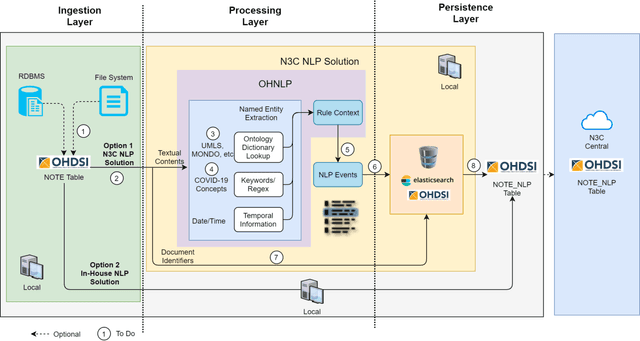
While we pay attention to the latest advances in clinical natural language processing (NLP), we can notice some resistance in the clinical and translational research community to adopt NLP models due to limited transparency, Interpretability and usability. Built upon our previous work, in this study, we proposed an open natural language processing development framework and evaluated it through the implementation of NLP algorithms for the National COVID Cohort Collaborative (N3C). Based on the interests in information extraction from COVID-19 related clinical notes, our work includes 1) an open data annotation process using COVID-19 signs and symptoms as the use case, 2) a community-driven ruleset composing platform, and 3) a synthetic text data generation workflow to generate texts for information extraction tasks without involving human subjects. The generated corpora derived out of the texts from multiple intuitions and gold standard annotation are tested on a single institution's rule set has the performances in F1 score of 0.876, 0.706 and 0.694, respectively. The study as a consortium effort of the N3C NLP subgroup demonstrates the feasibility of creating a federated NLP algorithm development and benchmarking platform to enhance multi-institution clinical NLP study.
Boosting the Certified Robustness of L-infinity Distance Nets
Oct 13, 2021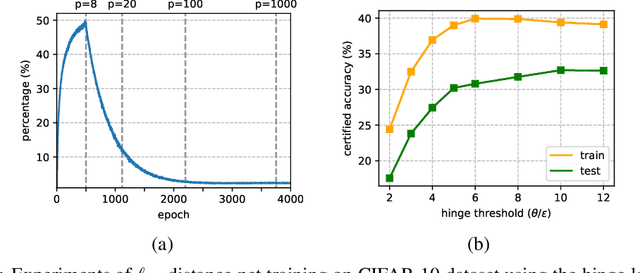
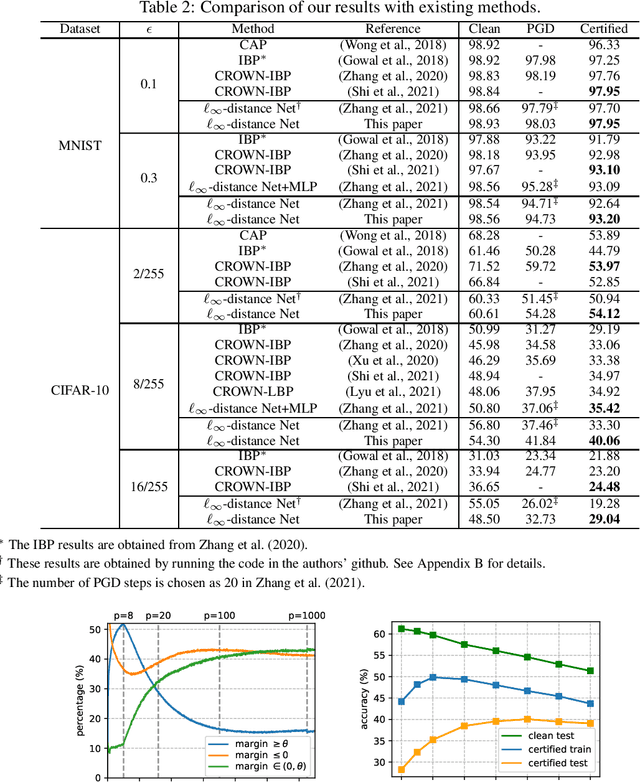
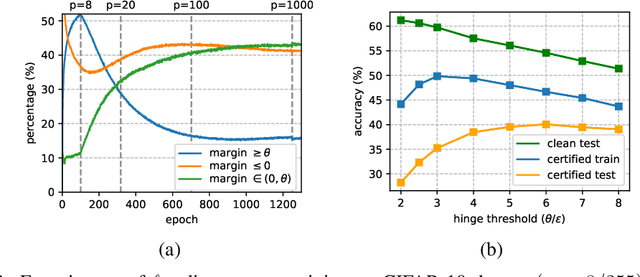

Recently, Zhang et al. (2021) developed a new neural network architecture based on $\ell_\infty$-distance functions, which naturally possesses certified robustness by its construction. Despite the excellent theoretical properties, the model so far can only achieve comparable performance to conventional networks. In this paper, we significantly boost the certified robustness of $\ell_\infty$-distance nets through a careful analysis of its training process. In particular, we show the $\ell_p$-relaxation, a crucial way to overcome the non-smoothness of the model, leads to an unexpected large Lipschitz constant at the early training stage. This makes the optimization insufficient using hinge loss and produces sub-optimal solutions. Given these findings, we propose a simple approach to address the issues above by using a novel objective function that combines a scaled cross-entropy loss with clipped hinge loss. Our experiments show that using the proposed training strategy, the certified accuracy of $\ell_\infty$-distance net can be dramatically improved from 33.30% to 40.06% on CIFAR-10 ($\epsilon=8/255$), meanwhile significantly outperforming other approaches in this area. Such a result clearly demonstrates the effectiveness and potential of $\ell_\infty$-distance net for certified robustness.
Semi-Supervised Semantic Segmentation via Adaptive Equalization Learning
Oct 11, 2021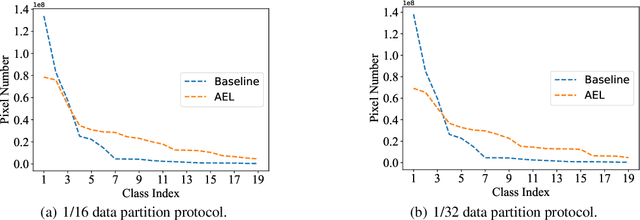
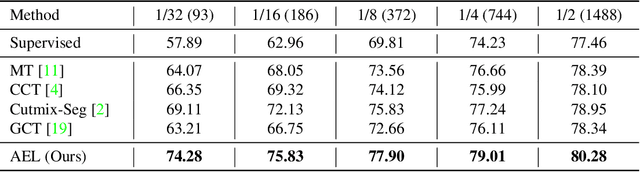
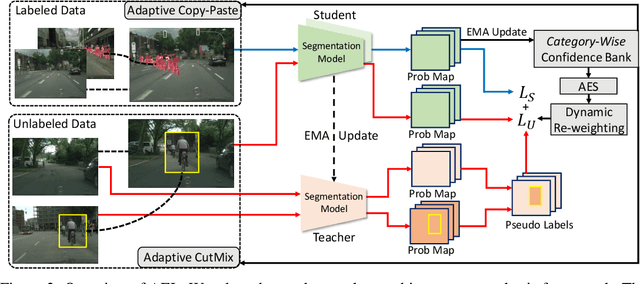
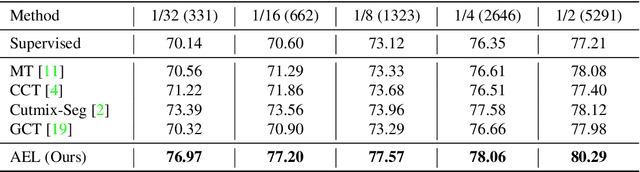
Due to the limited and even imbalanced data, semi-supervised semantic segmentation tends to have poor performance on some certain categories, e.g., tailed categories in Cityscapes dataset which exhibits a long-tailed label distribution. Existing approaches almost all neglect this problem, and treat categories equally. Some popular approaches such as consistency regularization or pseudo-labeling may even harm the learning of under-performing categories, that the predictions or pseudo labels of these categories could be too inaccurate to guide the learning on the unlabeled data. In this paper, we look into this problem, and propose a novel framework for semi-supervised semantic segmentation, named adaptive equalization learning (AEL). AEL adaptively balances the training of well and badly performed categories, with a confidence bank to dynamically track category-wise performance during training. The confidence bank is leveraged as an indicator to tilt training towards under-performing categories, instantiated in three strategies: 1) adaptive Copy-Paste and CutMix data augmentation approaches which give more chance for under-performing categories to be copied or cut; 2) an adaptive data sampling approach to encourage pixels from under-performing category to be sampled; 3) a simple yet effective re-weighting method to alleviate the training noise raised by pseudo-labeling. Experimentally, AEL outperforms the state-of-the-art methods by a large margin on the Cityscapes and Pascal VOC benchmarks under various data partition protocols. Code is available at https://github.com/hzhupku/SemiSeg-AEL
Near-Optimal Reward-Free Exploration for Linear Mixture MDPs with Plug-in Solver
Oct 08, 2021Although model-based reinforcement learning (RL) approaches are considered more sample efficient, existing algorithms are usually relying on sophisticated planning algorithm to couple tightly with the model-learning procedure. Hence the learned models may lack the ability of being re-used with more specialized planners. In this paper we address this issue and provide approaches to learn an RL model efficiently without the guidance of a reward signal. In particular, we take a plug-in solver approach, where we focus on learning a model in the exploration phase and demand that \emph{any planning algorithm} on the learned model can give a near-optimal policy. Specicially, we focus on the linear mixture MDP setting, where the probability transition matrix is a (unknown) convex combination of a set of existing models. We show that, by establishing a novel exploration algorithm, the plug-in approach learns a model by taking $\tilde{O}(d^2H^3/\epsilon^2)$ interactions with the environment and \emph{any} $\epsilon$-optimal planner on the model gives an $O(\epsilon)$-optimal policy on the original model. This sample complexity matches lower bounds for non-plug-in approaches and is \emph{statistically optimal}. We achieve this result by leveraging a careful maximum total-variance bound using Bernstein inequality and properties specified to linear mixture MDP.
Understanding Domain Randomization for Sim-to-real Transfer
Oct 07, 2021


Reinforcement learning encounters many challenges when applied directly in the real world. Sim-to-real transfer is widely used to transfer the knowledge learned from simulation to the real world. Domain randomization -- one of the most popular algorithms for sim-to-real transfer -- has been demonstrated to be effective in various tasks in robotics and autonomous driving. Despite its empirical successes, theoretical understanding on why this simple algorithm works is limited. In this paper, we propose a theoretical framework for sim-to-real transfers, in which the simulator is modeled as a set of MDPs with tunable parameters (corresponding to unknown physical parameters such as friction). We provide sharp bounds on the sim-to-real gap -- the difference between the value of policy returned by domain randomization and the value of an optimal policy for the real world. We prove that sim-to-real transfer can succeed under mild conditions without any real-world training samples. Our theory also highlights the importance of using memory (i.e., history-dependent policies) in domain randomization. Our proof is based on novel techniques that reduce the problem of bounding the sim-to-real gap to the problem of designing efficient learning algorithms for infinite-horizon MDPs, which we believe are of independent interest.