 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparse Tokens Suffice: Jailbreaking Audio Language Models via Token-Aware Gradient Optimization
May 06, 2026Jailbreak attacks on audio language models (ALMs) optimize audio perturbations to elicit unsafe generations, and they typically update the entire waveform densely throughout optimization. In this work, we investigate the necessity of such dense optimization by analyzing the structure of token-aligned gradients in ALMs. We find that gradient energy is highly non-uniform across audio tokens, indicating that only a small subset of token-aligned audio regions dominates the optimization signal. Motivated by this observation, we propose Token-Aware Gradient Optimization (TAGO), which enables sparse jailbreak optimization by retaining only waveform gradients aligned with audio tokens that have high gradient energy, while masking the remaining gradients at each iteration. Across three ALMs, TAGO outperforms baselines, and substantial sparsification preserves strong attack success rates (e.g. on Qwen3-Omni, $\mathrm{ASR}_{l}$ remains at 86% with a token retention ratio of 0.25, compared to 87% with full token retention). These results demonstrate that dense waveform updates are largely redundant, and we advocate that future audio jailbreak and safety alignment research should further leverage this heterogeneous token-level gradient structure.
Devling into Adversarial Transferability on Image Classification: Review, Benchmark, and Evaluation
Feb 26, 2026Adversarial transferability refers to the capacity of adversarial examples generated on the surrogate model to deceive alternate, unexposed victim models. This property eliminates the need for direct access to the victim model during an attack, thereby raising considerable security concerns in practical applications and attracting substantial research attention recently. In this work, we discern a lack of a standardized framework and criteria for evaluating transfer-based attacks, leading to potentially biased assessments of existing approaches. To rectify this gap, we have conducted an exhaustive review of hundreds of related works, organizing various transfer-based attacks into six distinct categories. Subsequently, we propose a comprehensive framework designed to serve as a benchmark for evaluating these attacks. In addition, we delineate common strategies that enhance adversarial transferability and highlight prevalent issues that could lead to unfair comparisons. Finally, we provide a brief review of transfer-based attacks beyond image classification.
Security Risk of Misalignment between Text and Image in Multi-modal Model
Oct 30, 2025Despite the notable advancements and versatility of multi-modal diffusion models, such as text-to-image models, their susceptibility to adversarial inputs remains underexplored. Contrary to expectations, our investigations reveal that the alignment between textual and Image modalities in existing diffusion models is inadequate. This misalignment presents significant risks, especially in the generation of inappropriate or Not-Safe-For-Work (NSFW) content. To this end, we propose a novel attack called Prompt-Restricted Multi-modal Attack (PReMA) to manipulate the generated content by modifying the input image in conjunction with any specified prompt, without altering the prompt itself. PReMA is the first attack that manipulates model outputs by solely creating adversarial images, distinguishing itself from prior methods that primarily generate adversarial prompts to produce NSFW content. Consequently, PReMA poses a novel threat to the integrity of multi-modal diffusion models, particularly in image-editing applications that operate with fixed prompts. Comprehensive evaluations conducted on image inpainting and style transfer tasks across various models confirm the potent efficacy of PReMA.
ViT-EnsembleAttack: Augmenting Ensemble Models for Stronger Adversarial Transferability in Vision Transformers
Aug 17, 2025Ensemble-based attacks have been proven to be effective in enhancing adversarial transferability by aggregating the outputs of models with various architectures. However, existing research primarily focuses on refining ensemble weights or optimizing the ensemble path, overlooking the exploration of ensemble models to enhance the transferability of adversarial attacks. To address this gap, we propose applying adversarial augmentation to the surrogate models, aiming to boost overall generalization of ensemble models and reduce the risk of adversarial overfitting. Meanwhile, observing that ensemble Vision Transformers (ViTs) gain less attention, we propose ViT-EnsembleAttack based on the idea of model adversarial augmentation, the first ensemble-based attack method tailored for ViTs to the best of our knowledge. Our approach generates augmented models for each surrogate ViT using three strategies: Multi-head dropping, Attention score scaling, and MLP feature mixing, with the associated parameters optimized by Bayesian optimization. These adversarially augmented models are ensembled to generate adversarial examples. Furthermore, we introduce Automatic Reweighting and Step Size Enlargement modules to boost transferability. Extensive experiments demonstrate that ViT-EnsembleAttack significantly enhances the adversarial transferability of ensemble-based attacks on ViTs, outperforming existing methods by a substantial margin. Code is available at https://github.com/Trustworthy-AI-Group/TransferAttack.
GenBreak: Red Teaming Text-to-Image Generators Using Large Language Models
Jun 11, 2025Text-to-image (T2I) models such as Stable Diffusion have advanced rapidly and are now widely used in content creation. However, these models can be misused to generate harmful content, including nudity or violence, posing significant safety risks. While most platforms employ content moderation systems, underlying vulnerabilities can still be exploited by determined adversaries. Recent research on red-teaming and adversarial attacks against T2I models has notable limitations: some studies successfully generate highly toxic images but use adversarial prompts that are easily detected and blocked by safety filters, while others focus on bypassing safety mechanisms but fail to produce genuinely harmful outputs, neglecting the discovery of truly high-risk prompts. Consequently, there remains a lack of reliable tools for evaluating the safety of defended T2I models. To address this gap, we propose GenBreak, a framework that fine-tunes a red-team large language model (LLM) to systematically explore underlying vulnerabilities in T2I generators. Our approach combines supervised fine-tuning on curated datasets with reinforcement learning via interaction with a surrogate T2I model. By integrating multiple reward signals, we guide the LLM to craft adversarial prompts that enhance both evasion capability and image toxicity, while maintaining semantic coherence and diversity. These prompts demonstrate strong effectiveness in black-box attacks against commercial T2I generators, revealing practical and concerning safety weaknesses.
Attention! You Vision Language Model Could Be Maliciously Manipulated
May 26, 2025



Large Vision-Language Models (VLMs) have achieved remarkable success in understanding complex real-world scenarios and supporting data-driven decision-making processes. However, VLMs exhibit significant vulnerability against adversarial examples, either text or image, which can lead to various adversarial outcomes, e.g., jailbreaking, hijacking, and hallucination, etc. In this work, we empirically and theoretically demonstrate that VLMs are particularly susceptible to image-based adversarial examples, where imperceptible perturbations can precisely manipulate each output token. To this end, we propose a novel attack called Vision-language model Manipulation Attack (VMA), which integrates first-order and second-order momentum optimization techniques with a differentiable transformation mechanism to effectively optimize the adversarial perturbation. Notably, VMA can be a double-edged sword: it can be leveraged to implement various attacks, such as jailbreaking, hijacking, privacy breaches, Denial-of-Service, and the generation of sponge examples, etc, while simultaneously enabling the injection of watermarks for copyright protection. Extensive empirical evaluations substantiate the efficacy and generalizability of VMA across diverse scenarios and datasets.
Reinforced Diffuser for Red Teaming Large Vision-Language Models
Mar 08, 2025The rapid advancement of large Vision-Language Models (VLMs) has raised significant safety concerns, particularly regarding their vulnerability to jailbreak attacks. While existing research primarily focuses on VLMs' susceptibility to harmful instructions, this work identifies a critical yet overlooked vulnerability: current alignment mechanisms often fail to address the risks posed by toxic text continuation tasks. To investigate this issue, we propose a novel Red Team Diffuser (RTD) framework, which leverages reinforcement learning to generate red team images that effectively induce highly toxic continuations from target black-box VLMs. The RTD pipeline begins with a greedy search for high-quality image prompts that maximize the toxicity of VLM-generated sentence continuations, guided by a Large Language Model (LLM). These prompts are then used as input for the reinforcement fine-tuning of a diffusion model, which employs toxicity and alignment rewards to further amplify harmful outputs. Experimental results demonstrate the effectiveness of RTD, increasing the toxicity rate of LLaVA outputs by 10.69% on the original attack set and 8.91% on a hold-out set. Moreover, RTD exhibits strong cross-model transferability, raising the toxicity rate by 5.1% on Gemini and 26.83% on LLaMA. These findings reveal significant deficiencies in existing alignment strategies, particularly their inability to prevent harmful continuations. Our work underscores the urgent need for more robust and adaptive alignment mechanisms to ensure the safe deployment of VLMs in real-world applications.
Boosting the Local Invariance for Better Adversarial Transferability
Mar 08, 2025Transfer-based attacks pose a significant threat to real-world applications by directly targeting victim models with adversarial examples generated on surrogate models. While numerous approaches have been proposed to enhance adversarial transferability, existing works often overlook the intrinsic relationship between adversarial perturbations and input images. In this work, we find that adversarial perturbation often exhibits poor translation invariance for a given clean image and model, which is attributed to local invariance. Through empirical analysis, we demonstrate that there is a positive correlation between the local invariance of adversarial perturbations w.r.t. the input image and their transferability across different models. Based on this finding, we propose a general adversarial transferability boosting technique called Local Invariance Boosting approach (LI-Boost). Extensive experiments on the standard ImageNet dataset demonstrate that LI-Boost could significantly boost various types of transfer-based attacks (e.g., gradient-based, input transformation-based, model-related, advanced objective function, ensemble, etc.) on CNNs, ViTs, and defense mechanisms. Our approach presents a promising direction for future research in improving adversarial transferability across different models.
DiffPatch: Generating Customizable Adversarial Patches using Diffusion Model
Dec 02, 2024
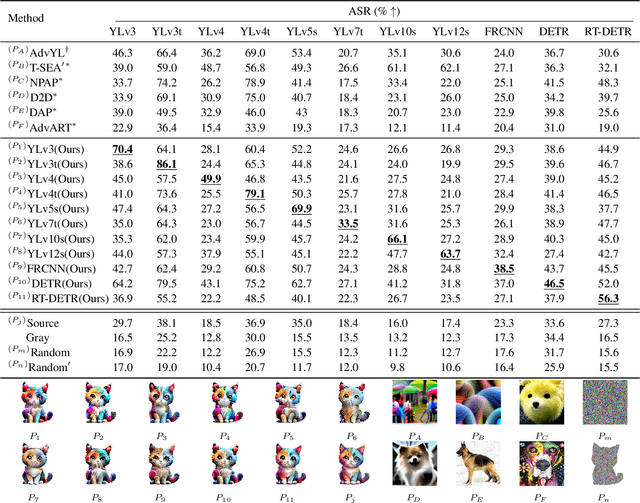
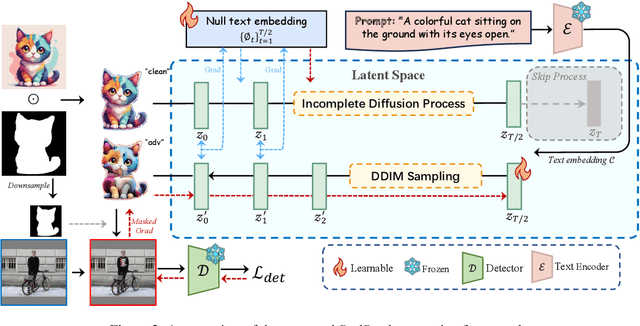
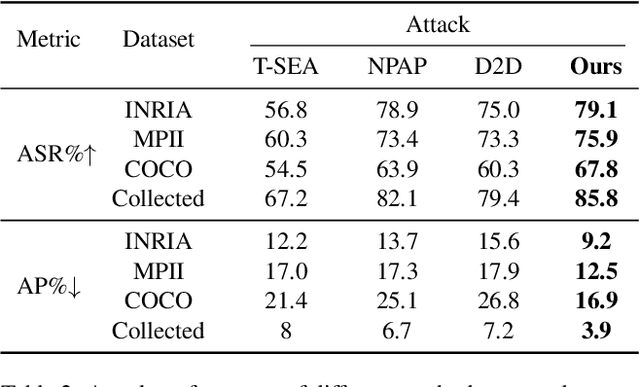
Physical adversarial patches printed on clothing can easily allow individuals to evade person detectors. However, most existing adversarial patch generation methods prioritize attack effectiveness over stealthiness, resulting in patches that are aesthetically unpleasing. Although existing methods using generative adversarial networks or diffusion models can produce more natural-looking patches, they often struggle to balance stealthiness with attack effectiveness and lack flexibility for user customization. To address these challenges, we propose a novel diffusion-based customizable patch generation framework termed DiffPatch, specifically tailored for creating naturalistic and customizable adversarial patches. Our approach enables users to utilize a reference image as the source, rather than starting from random noise, and incorporates masks to craft naturalistic patches of various shapes, not limited to squares. To prevent the original semantics from being lost during the diffusion process, we employ Null-text inversion to map random noise samples to a single input image and generate patches through Incomplete Diffusion Optimization (IDO). Notably, while maintaining a natural appearance, our method achieves a comparable attack performance to state-of-the-art non-naturalistic patches when using similarly sized attacks. Using DiffPatch, we have created a physical adversarial T-shirt dataset, AdvPatch-1K, specifically targeting YOLOv5s. This dataset includes over a thousand images across diverse scenarios, validating the effectiveness of our attack in real-world environments. Moreover, it provides a valuable resource for future research.
Bag of Tricks to Boost Adversarial Transferability
Jan 16, 2024Deep neural networks are widely known to be vulnerable to adversarial examples. However, vanilla adversarial examples generated under the white-box setting often exhibit low transferability across different models. Since adversarial transferability poses more severe threats to practical applications, various approaches have been proposed for better transferability, including gradient-based, input transformation-based, and model-related attacks, \etc. In this work, we find that several tiny changes in the existing adversarial attacks can significantly affect the attack performance, \eg, the number of iterations and step size. Based on careful studies of existing adversarial attacks, we propose a bag of tricks to enhance adversarial transferability, including momentum initialization, scheduled step size, dual example, spectral-based input transformation, and several ensemble strategies. Extensive experiments on the ImageNet dataset validate the high effectiveness of our proposed tricks and show that combining them can further boost adversarial transferability. Our work provides practical insights and techniques to enhance adversarial transferability, and offers guidance to improve the attack performance on the real-world application through simple adjustments.