 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSyntax-Enhanced Pre-trained Model
Dec 28, 2020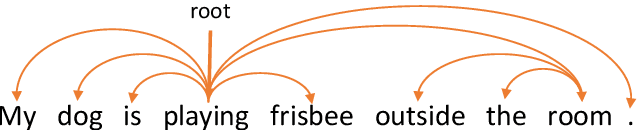
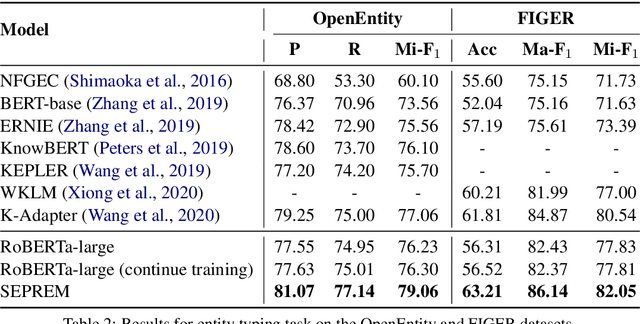
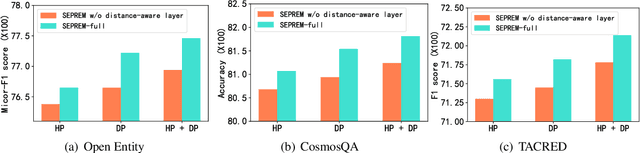
We study the problem of leveraging the syntactic structure of text to enhance pre-trained models such as BERT and RoBERTa. Existing methods utilize syntax of text either in the pre-training stage or in the fine-tuning stage, so that they suffer from discrepancy between the two stages. Such a problem would lead to the necessity of having human-annotated syntactic information, which limits the application of existing methods to broader scenarios. To address this, we present a model that utilizes the syntax of text in both pre-training and fine-tuning stages. Our model is based on Transformer with a syntax-aware attention layer that considers the dependency tree of the text. We further introduce a new pre-training task of predicting the syntactic distance among tokens in the dependency tree. We evaluate the model on three downstream tasks, including relation classification, entity typing, and question answering. Results show that our model achieves state-of-the-art performance on six public benchmark datasets. We have two major findings. First, we demonstrate that infusing automatically produced syntax of text improves pre-trained models. Second, global syntactic distances among tokens bring larger performance gains compared to local head relations between contiguous tokens.
Reinforced Multi-Teacher Selection for Knowledge Distillation
Dec 14, 2020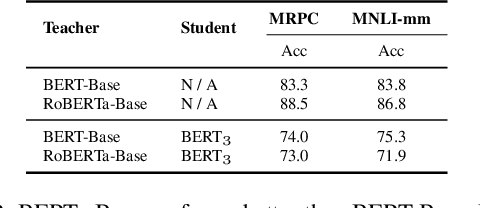
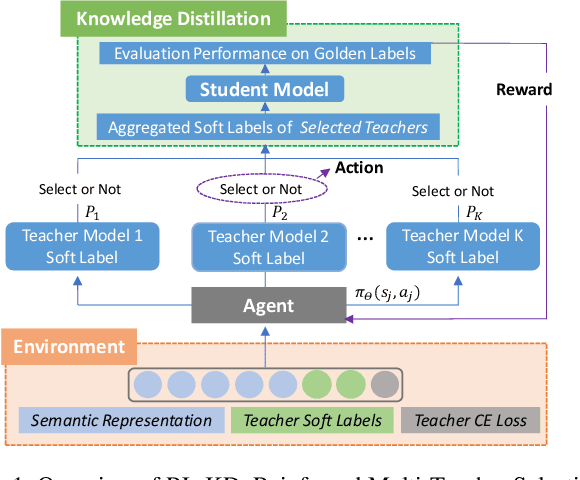

In natural language processing (NLP) tasks, slow inference speed and huge footprints in GPU usage remain the bottleneck of applying pre-trained deep models in production. As a popular method for model compression, knowledge distillation transfers knowledge from one or multiple large (teacher) models to a small (student) model. When multiple teacher models are available in distillation, the state-of-the-art methods assign a fixed weight to a teacher model in the whole distillation. Furthermore, most of the existing methods allocate an equal weight to every teacher model. In this paper, we observe that, due to the complexity of training examples and the differences in student model capability, learning differentially from teacher models can lead to better performance of student models distilled. We systematically develop a reinforced method to dynamically assign weights to teacher models for different training instances and optimize the performance of student model. Our extensive experimental results on several NLP tasks clearly verify the feasibility and effectiveness of our approach.
GLGE: A New General Language Generation Evaluation Benchmark
Nov 24, 2020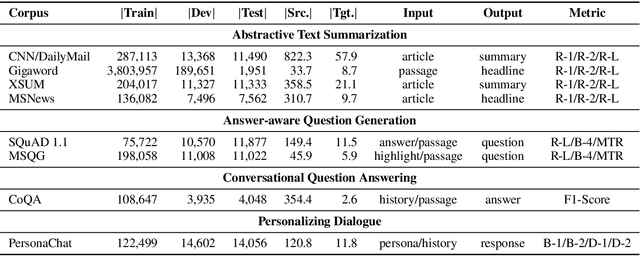
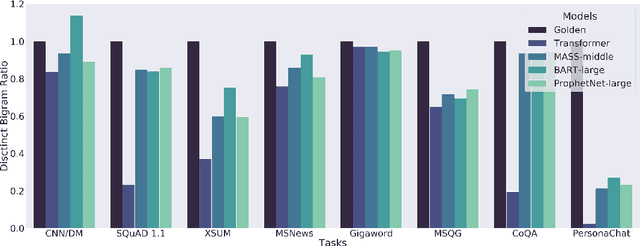

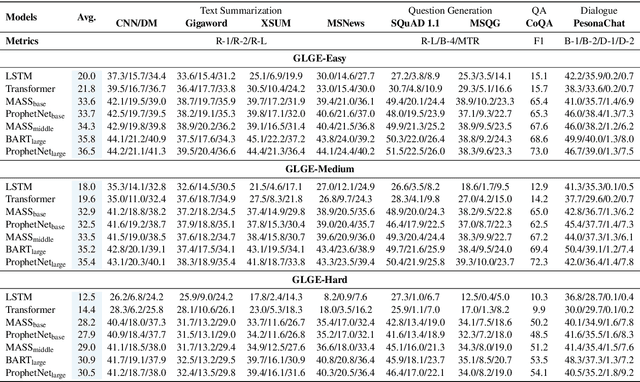
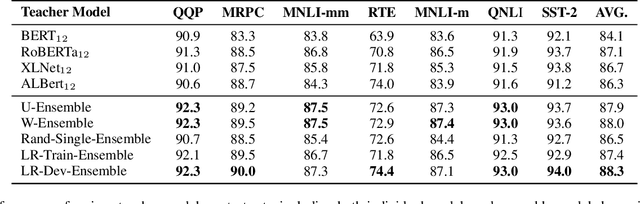
Multi-task benchmarks such as GLUE and SuperGLUE have driven great progress of pretraining and transfer learning in Natural Language Processing (NLP). These benchmarks mostly focus on a range of Natural Language Understanding (NLU) tasks, without considering the Natural Language Generation (NLG) models. In this paper, we present the General Language Generation Evaluation (GLGE), a new multi-task benchmark for evaluating the generalization capabilities of NLG models across eight language generation tasks. For each task, we continue to design three subtasks in terms of task difficulty (GLGE-Easy, GLGE-Medium, and GLGE-Hard). This introduces 24 subtasks to comprehensively compare model performance. To encourage research on pretraining and transfer learning on NLG models, we make GLGE publicly available and build a leaderboard with strong baselines including MASS, BART, and ProphetNet\footnote{The source code and dataset will be publicly available at https://github.com/microsoft/glge.
CalibreNet: Calibration Networks for Multilingual Sequence Labeling
Nov 11, 2020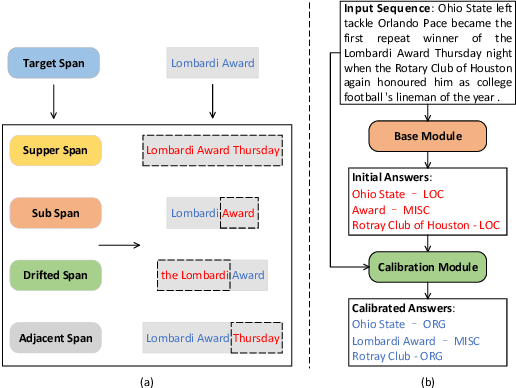

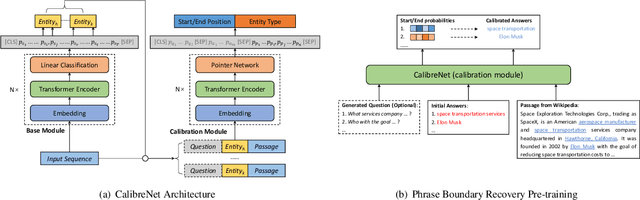
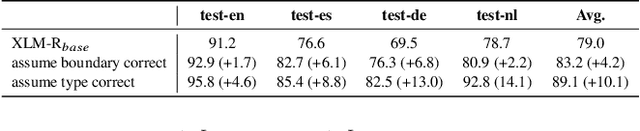
Lack of training data in low-resource languages presents huge challenges to sequence labeling tasks such as named entity recognition (NER) and machine reading comprehension (MRC). One major obstacle is the errors on the boundary of predicted answers. To tackle this problem, we propose CalibreNet, which predicts answers in two steps. In the first step, any existing sequence labeling method can be adopted as a base model to generate an initial answer. In the second step, CalibreNet refines the boundary of the initial answer. To tackle the challenge of lack of training data in low-resource languages, we dedicatedly develop a novel unsupervised phrase boundary recovery pre-training task to enhance the multilingual boundary detection capability of CalibreNet. Experiments on two cross-lingual benchmark datasets show that the proposed approach achieves SOTA results on zero-shot cross-lingual NER and MRC tasks.
Cross-lingual Machine Reading Comprehension with Language Branch Knowledge Distillation
Oct 27, 2020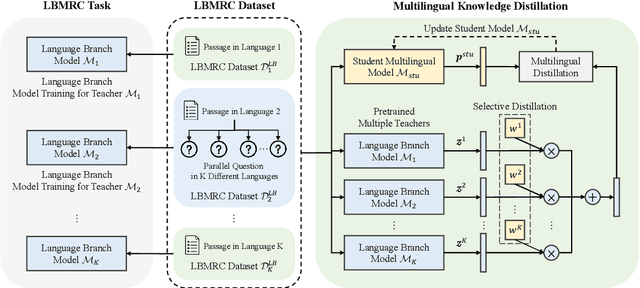
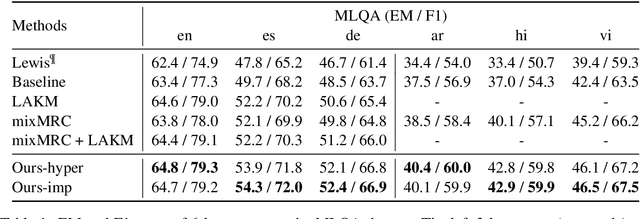
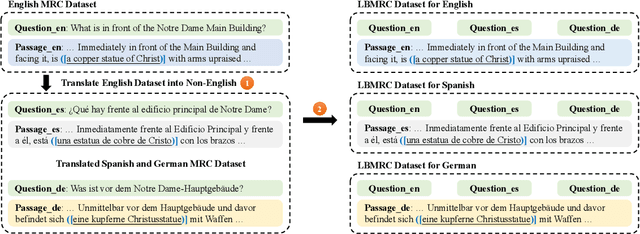
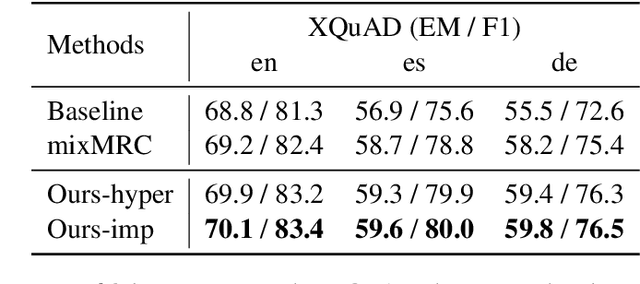
Cross-lingual Machine Reading Comprehension (CLMRC) remains a challenging problem due to the lack of large-scale annotated datasets in low-source languages, such as Arabic, Hindi, and Vietnamese. Many previous approaches use translation data by translating from a rich-source language, such as English, to low-source languages as auxiliary supervision. However, how to effectively leverage translation data and reduce the impact of noise introduced by translation remains onerous. In this paper, we tackle this challenge and enhance the cross-lingual transferring performance by a novel augmentation approach named Language Branch Machine Reading Comprehension (LBMRC). A language branch is a group of passages in one single language paired with questions in all target languages. We train multiple machine reading comprehension (MRC) models proficient in individual language based on LBMRC. Then, we devise a multilingual distillation approach to amalgamate knowledge from multiple language branch models to a single model for all target languages. Combining the LBMRC and multilingual distillation can be more robust to the data noises, therefore, improving the model's cross-lingual ability. Meanwhile, the produced single multilingual model is applicable to all target languages, which saves the cost of training, inference, and maintenance for multiple models. Extensive experiments on two CLMRC benchmarks clearly show the effectiveness of our proposed method.
Learning Better Representation for Tables by Self-Supervised Tasks
Oct 15, 2020
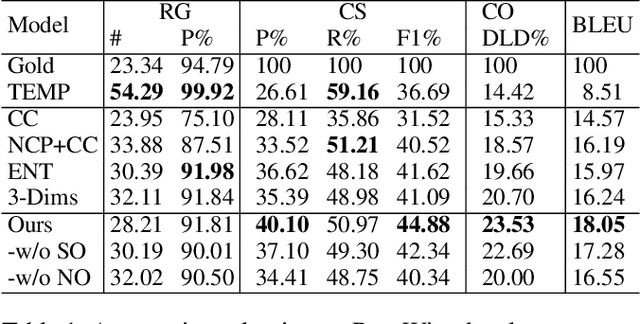
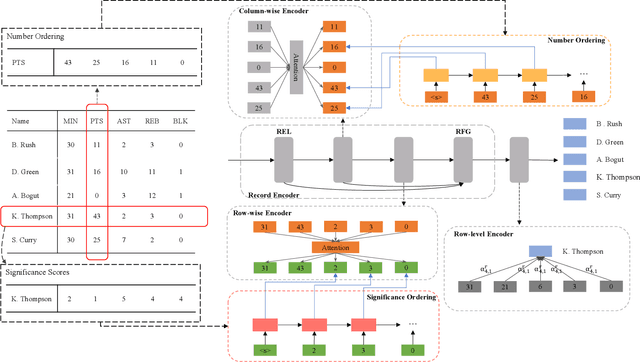
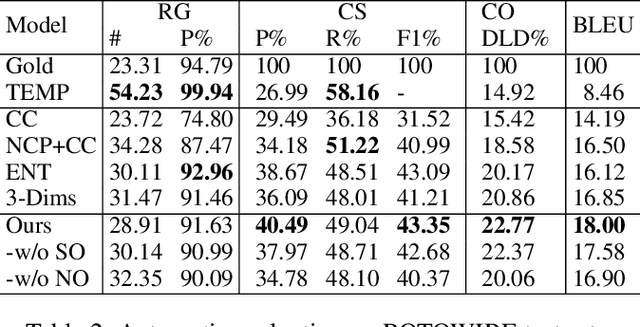
Table-to-text generation aims at automatically generating natural text to help people to conveniently obtain the important information in tables. Although neural models for table-to-text have achieved remarkable progress, some problems still overlooked. The first is that the values recorded in many tables are mostly numbers in practice. The existing approaches do not do special treatment for these, and still regard these as words in natural language text. Secondly, the target texts in training dataset may contain redundant information or facts do not exist in the input tables. These may give wrong supervision signals to some methods based on content selection and planning and auxiliary supervision. To solve these problems, we propose two self-supervised tasks, Number Ordering and Significance Ordering, to help to learn better table representation. The former works on the column dimension to help to incorporate the size property of numbers into table representation. The latter acts on row dimension and help to learn a significance-aware table representation. We test our methods on the widely used dataset ROTOWIRE which consists of NBA game statistic and related news. The experimental results demonstrate that the model trained together with these two self-supervised tasks can generate text that contains more salient and well-organized facts, even without modeling context selection and planning. And we achieve the state-of-the-art performance on automatic metrics.
A Graph Representation of Semi-structured Data for Web Question Answering
Oct 14, 2020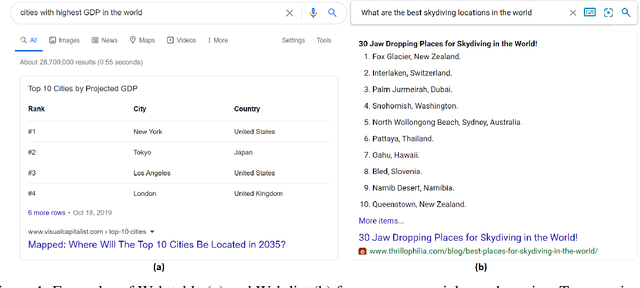

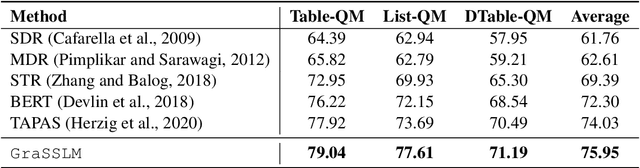
The abundant semi-structured data on the Web, such as HTML-based tables and lists, provide commercial search engines a rich information source for question answering (QA). Different from plain text passages in Web documents, Web tables and lists have inherent structures, which carry semantic correlations among various elements in tables and lists. Many existing studies treat tables and lists as flat documents with pieces of text and do not make good use of semantic information hidden in structures. In this paper, we propose a novel graph representation of Web tables and lists based on a systematic categorization of the components in semi-structured data as well as their relations. We also develop pre-training and reasoning techniques on the graph model for the QA task. Extensive experiments on several real datasets collected from a commercial engine verify the effectiveness of our approach. Our method improves F1 score by 3.90 points over the state-of-the-art baselines.
MaP: A Matrix-based Prediction Approach to Improve Span Extraction in Machine Reading Comprehension
Sep 29, 2020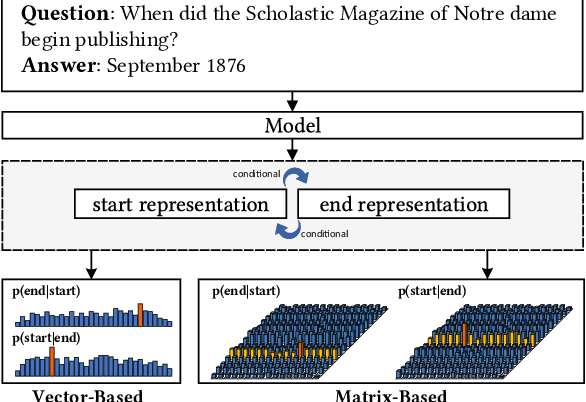
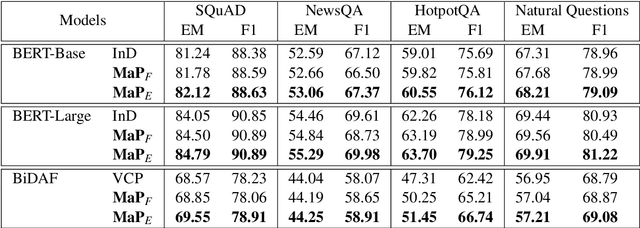
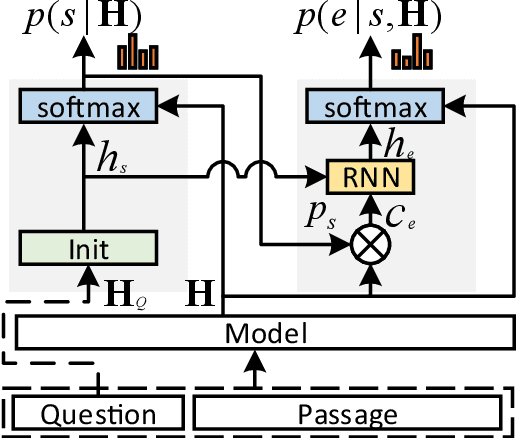
Span extraction is an essential problem in machine reading comprehension. Most of the existing algorithms predict the start and end positions of an answer span in the given corresponding context by generating two probability vectors. In this paper, we propose a novel approach that extends the probability vector to a probability matrix. Such a matrix can cover more start-end position pairs. Precisely, to each possible start index, the method always generates an end probability vector. Besides, we propose a sampling-based training strategy to address the computational cost and memory issue in the matrix training phase. We evaluate our method on SQuAD 1.1 and three other question answering benchmarks. Leveraging the most competitive models BERT and BiDAF as the backbone, our proposed approach can get consistent improvements in all datasets, demonstrating the effectiveness of the proposed method.
No Answer is Better Than Wrong Answer: A Reflection Model for Document Level Machine Reading Comprehension
Sep 29, 2020
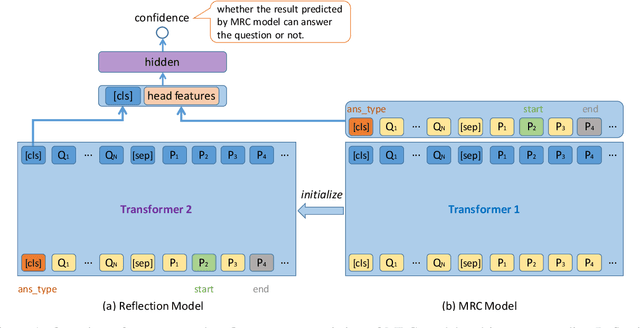

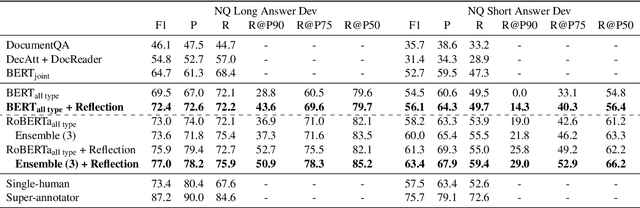
The Natural Questions (NQ) benchmark set brings new challenges to Machine Reading Comprehension: the answers are not only at different levels of granularity (long and short), but also of richer types (including no-answer, yes/no, single-span and multi-span). In this paper, we target at this challenge and handle all answer types systematically. In particular, we propose a novel approach called Reflection Net which leverages a two-step training procedure to identify the no-answer and wrong-answer cases. Extensive experiments are conducted to verify the effectiveness of our approach. At the time of paper writing (May.~20,~2020), our approach achieved the top 1 on both long and short answer leaderboard, with F1 scores of 77.2 and 64.1, respectively.
Tag and Correct: Question aware Open Information Extraction with Two-stage Decoding
Sep 16, 2020
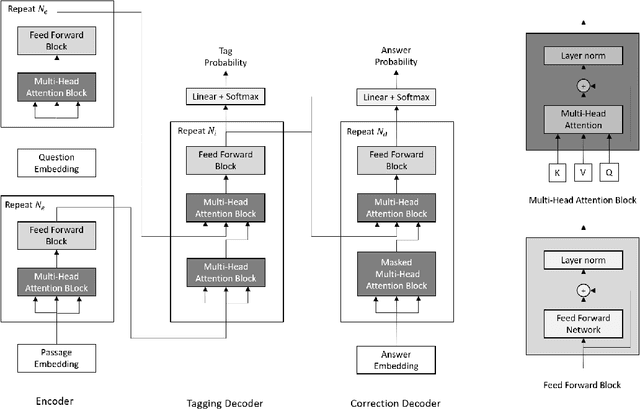


Question Aware Open Information Extraction (Question aware Open IE) takes question and passage as inputs, outputting an answer tuple which contains a subject, a predicate, and one or more arguments. Each field of answer is a natural language word sequence and is extracted from the passage. The semi-structured answer has two advantages which are more readable and falsifiable compared to span answer. There are two approaches to solve this problem. One is an extractive method which extracts candidate answers from the passage with the Open IE model, and ranks them by matching with questions. It fully uses the passage information at the extraction step, but the extraction is independent to the question. The other one is the generative method which uses a sequence to sequence model to generate answers directly. It combines the question and passage as input at the same time, but it generates the answer from scratch, which does not use the facts that most of the answer words come from in the passage. To guide the generation by passage, we present a two-stage decoding model which contains a tagging decoder and a correction decoder. At the first stage, the tagging decoder will tag keywords from the passage. At the second stage, the correction decoder will generate answers based on tagged keywords. Our model could be trained end-to-end although it has two stages. Compared to previous generative models, we generate better answers by generating coarse to fine. We evaluate our model on WebAssertions (Yan et al., 2018) which is a Question aware Open IE dataset. Our model achieves a BLEU score of 59.32, which is better than previous generative methods.