 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Models Reasoning Abilities Under Non-Ideal Conditions After RL-Fine-Tuning
Aug 06, 2025Reinforcement learning (RL) has become a key technique for enhancing the reasoning abilities of large language models (LLMs), with policy-gradient algorithms dominating the post-training stage because of their efficiency and effectiveness. However, most existing benchmarks evaluate large-language-model reasoning under idealized settings, overlooking performance in realistic, non-ideal scenarios. We identify three representative non-ideal scenarios with practical relevance: summary inference, fine-grained noise suppression, and contextual filtering. We introduce a new research direction guided by brain-science findings that human reasoning remains reliable under imperfect inputs. We formally define and evaluate these challenging scenarios. We fine-tune three LLMs and a state-of-the-art large vision-language model (LVLM) using RL with a representative policy-gradient algorithm and then test their performance on eight public datasets. Our results reveal that while RL fine-tuning improves baseline reasoning under idealized settings, performance declines significantly across all three non-ideal scenarios, exposing critical limitations in advanced reasoning capabilities. Although we propose a scenario-specific remediation method, our results suggest current methods leave these reasoning deficits largely unresolved. This work highlights that the reasoning abilities of large models are often overstated and underscores the importance of evaluating models under non-ideal scenarios. The code and data will be released at XXXX.
A Generic Method for Fine-grained Category Discovery in Natural Language Texts
Jun 18, 2024



Fine-grained category discovery using only coarse-grained supervision is a cost-effective yet challenging task. Previous training methods focus on aligning query samples with positive samples and distancing them from negatives. They often neglect intra-category and inter-category semantic similarities of fine-grained categories when navigating sample distributions in the embedding space. Furthermore, some evaluation techniques that rely on pre-collected test samples are inadequate for real-time applications. To address these shortcomings, we introduce a method that successfully detects fine-grained clusters of semantically similar texts guided by a novel objective function. The method uses semantic similarities in a logarithmic space to guide sample distributions in the Euclidean space and to form distinct clusters that represent fine-grained categories. We also propose a centroid inference mechanism to support real-time applications. The efficacy of the method is both theoretically justified and empirically confirmed on three benchmark tasks. The proposed objective function is integrated in multiple contrastive learning based neural models. Its results surpass existing state-of-the-art approaches in terms of Accuracy, Adjusted Rand Index and Normalized Mutual Information of the detected fine-grained categories. Code and data will be available at https://github.com/XX upon publication.
Graph-to-Text Generation with Dynamic Structure Pruning
Sep 15, 2022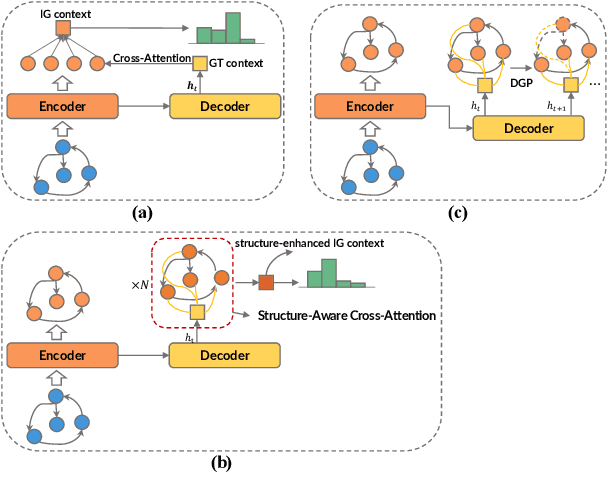
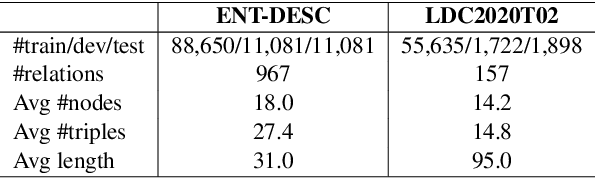
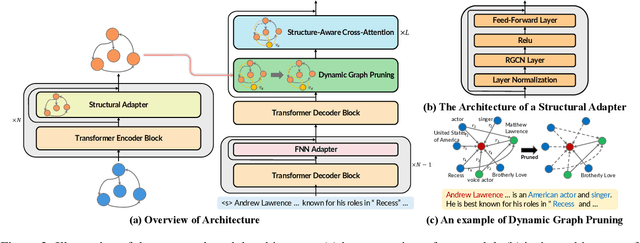
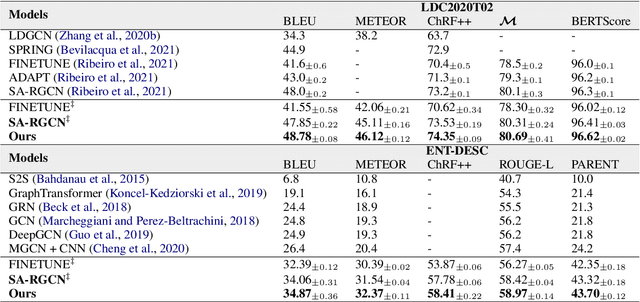
Most graph-to-text works are built on the encoder-decoder framework with cross-attention mechanism. Recent studies have shown that explicitly modeling the input graph structure can significantly improve the performance. However, the vanilla structural encoder cannot capture all specialized information in a single forward pass for all decoding steps, resulting in inaccurate semantic representations. Meanwhile, the input graph is flatted as an unordered sequence in the cross attention, ignoring the original graph structure. As a result, the obtained input graph context vector in the decoder may be flawed. To address these issues, we propose a Structure-Aware Cross-Attention (SACA) mechanism to re-encode the input graph representation conditioning on the newly generated context at each decoding step in a structure aware manner. We further adapt SACA and introduce its variant Dynamic Graph Pruning (DGP) mechanism to dynamically drop irrelevant nodes in the decoding process. We achieve new state-of-the-art results on two graph-to-text datasets, LDC2020T02 and ENT-DESC, with only minor increase on computational cost.
Learning Explicit User Interest Boundary for Recommendation
Nov 22, 2021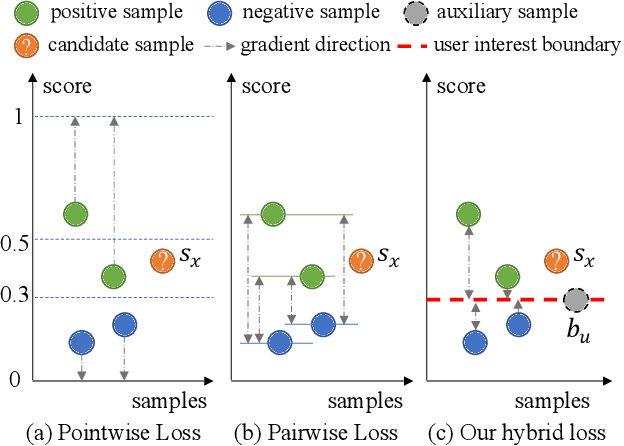

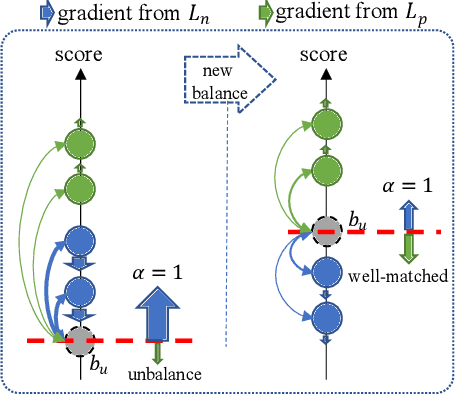

The core objective of modelling recommender systems from implicit feedback is to maximize the positive sample score $s_p$ and minimize the negative sample score $s_n$, which can usually be summarized into two paradigms: the pointwise and the pairwise. The pointwise approaches fit each sample with its label individually, which is flexible in weighting and sampling on instance-level but ignores the inherent ranking property. By qualitatively minimizing the relative score $s_n - s_p$, the pairwise approaches capture the ranking of samples naturally but suffer from training efficiency. Additionally, both approaches are hard to explicitly provide a personalized decision boundary to determine if users are interested in items unseen. To address those issues, we innovatively introduce an auxiliary score $b_u$ for each user to represent the User Interest Boundary(UIB) and individually penalize samples that cross the boundary with pairwise paradigms, i.e., the positive samples whose score is lower than $b_u$ and the negative samples whose score is higher than $b_u$. In this way, our approach successfully achieves a hybrid loss of the pointwise and the pairwise to combine the advantages of both. Analytically, we show that our approach can provide a personalized decision boundary and significantly improve the training efficiency without any special sampling strategy. Extensive results show that our approach achieves significant improvements on not only the classical pointwise or pairwise models but also state-of-the-art models with complex loss function and complicated feature encoding.
Learning Better Representation for Tables by Self-Supervised Tasks
Oct 15, 2020
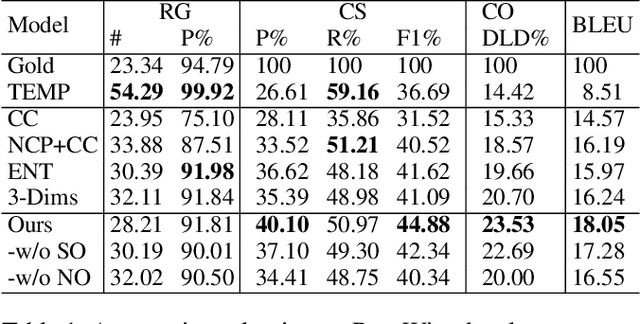
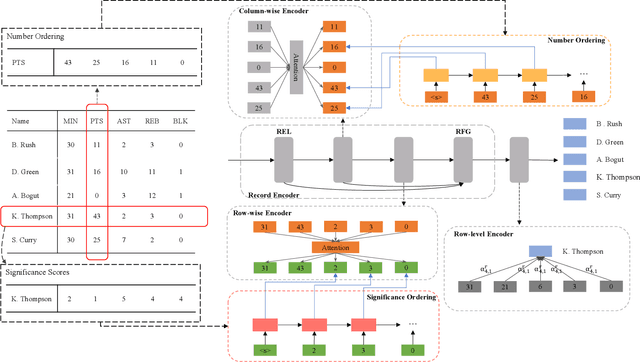
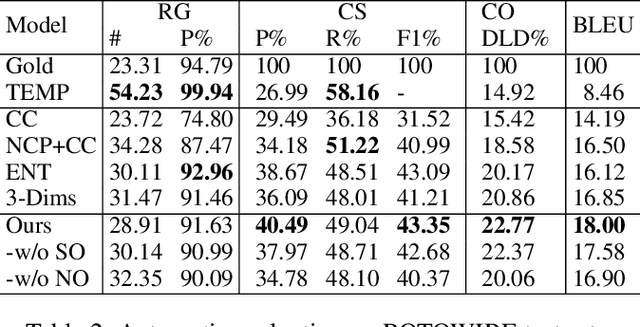
Table-to-text generation aims at automatically generating natural text to help people to conveniently obtain the important information in tables. Although neural models for table-to-text have achieved remarkable progress, some problems still overlooked. The first is that the values recorded in many tables are mostly numbers in practice. The existing approaches do not do special treatment for these, and still regard these as words in natural language text. Secondly, the target texts in training dataset may contain redundant information or facts do not exist in the input tables. These may give wrong supervision signals to some methods based on content selection and planning and auxiliary supervision. To solve these problems, we propose two self-supervised tasks, Number Ordering and Significance Ordering, to help to learn better table representation. The former works on the column dimension to help to incorporate the size property of numbers into table representation. The latter acts on row dimension and help to learn a significance-aware table representation. We test our methods on the widely used dataset ROTOWIRE which consists of NBA game statistic and related news. The experimental results demonstrate that the model trained together with these two self-supervised tasks can generate text that contains more salient and well-organized facts, even without modeling context selection and planning. And we achieve the state-of-the-art performance on automatic metrics.
FC2RN: A Fully Convolutional Corner Refinement Network for Accurate Multi-Oriented Scene Text Detection
Jul 10, 2020


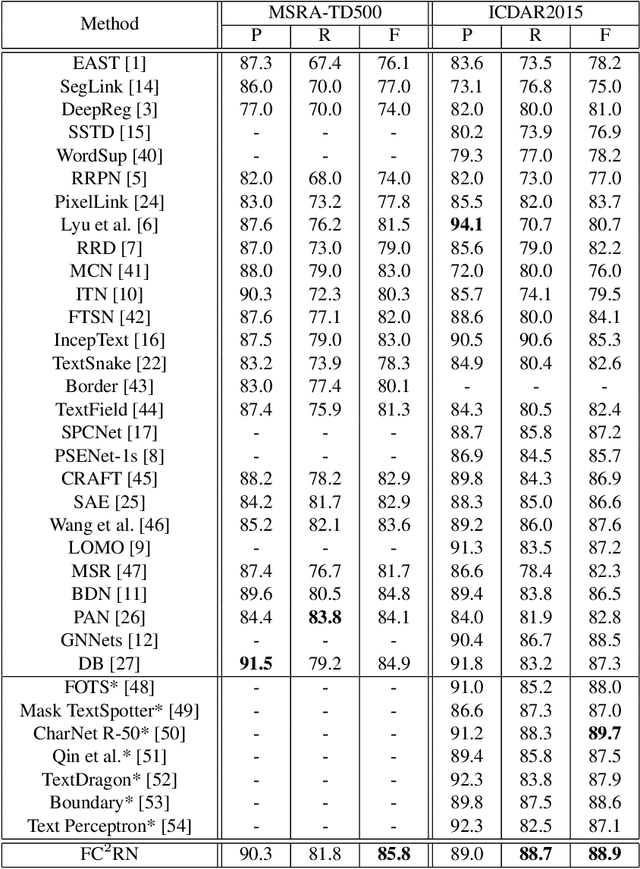
Recent scene text detection works mainly focus on curve text detection. However, in real applications, the curve texts are more scarce than the multi-oriented ones. Accurate detection of multi-oriented text with large variations of scales, orientations, and aspect ratios is of great significance. Among the multi-oriented detection methods, direct regression for the geometry of scene text shares a simple yet powerful pipeline and gets popular in academic and industrial communities, but it may produce imperfect detections, especially for long texts due to the limitation of the receptive field. In this work, we aim to improve this while keeping the pipeline simple. A fully convolutional corner refinement network (FC2RN) is proposed for accurate multi-oriented text detection, in which an initial corner prediction and a refined corner prediction are obtained at one pass. With a novel quadrilateral RoI convolution operation tailed for multi-oriented scene text, the initial quadrilateral prediction is encoded into the feature maps which can be further used to predict offset between the initial prediction and the ground-truth as well as output a refined confidence score. Experimental results on four public datasets including MSRA-TD500, ICDAR2017-RCTW, ICDAR2015, and COCO-Text demonstrate that FC2RN can outperform the state-of-the-art methods. The ablation study shows the effectiveness of corner refinement and scoring for accurate text localization.