 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Learn Kernels with Variational Random Features
Jun 11, 2020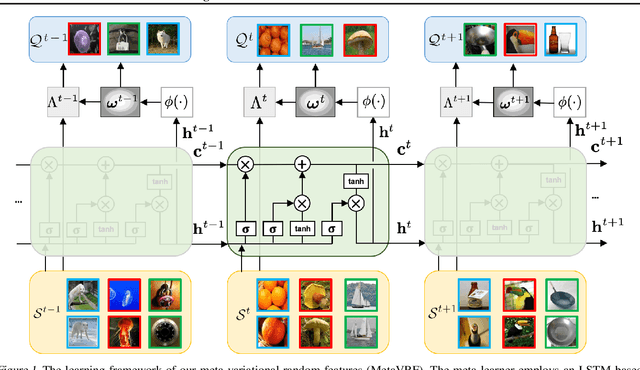
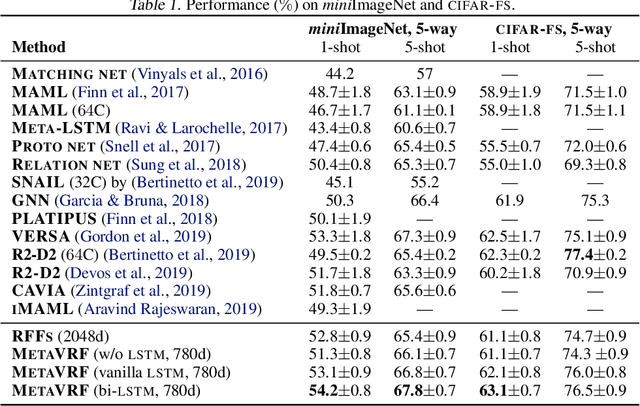
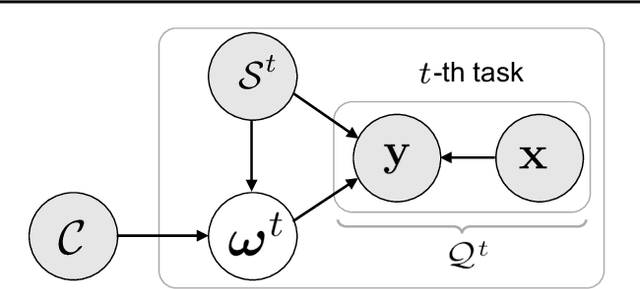
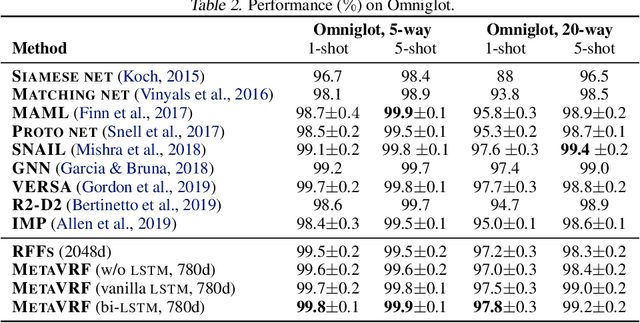
In this work, we introduce kernels with random Fourier features in the meta-learning framework to leverage their strong few-shot learning ability. We propose meta variational random features (MetaVRF) to learn adaptive kernels for the base-learner, which is developed in a latent variable model by treating the random feature basis as the latent variable. We formulate the optimization of MetaVRF as a variational inference problem by deriving an evidence lower bound under the meta-learning framework. To incorporate shared knowledge from related tasks, we propose a context inference of the posterior, which is established by an LSTM architecture. The LSTM-based inference network can effectively integrate the context information of previous tasks with task-specific information, generating informative and adaptive features. The learned MetaVRF can produce kernels of high representational power with a relatively low spectral sampling rate and also enables fast adaptation to new tasks. Experimental results on a variety of few-shot regression and classification tasks demonstrate that MetaVRF delivers much better, or at least competitive, performance compared to existing meta-learning alternatives.
Attentive WaveBlock: Complementarity-enhanced Mutual Networks for Unsupervised Domain Adaptation in Person Re-identification
Jun 11, 2020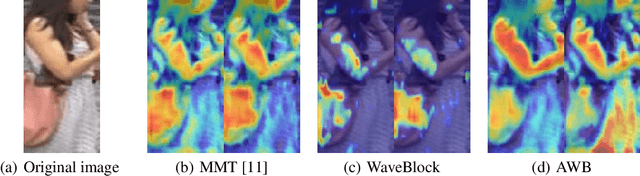
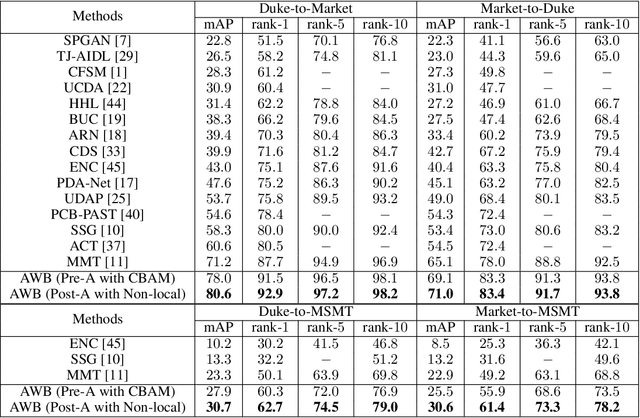
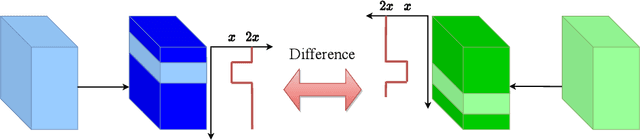

Unsupervised domain adaptation (UDA) for person re-identification is challenging because of the huge gap between the source and target domain. A typical self-training method is to use pseudo-labels generated by clustering algorithms to iteratively optimize the model on the target domain. However, a drawback to this is that noisy pseudo-labels generally cause troubles in learning. To address this problem, a mutual learning method by dual networks has been developed to produce reliable soft labels. However, as the two neural networks gradually converge, their complementarity is weakened and they likely become biased towards the same kind of noise. In this paper, we propose a novel light-weight module, the Attentive WaveBlock (AWB), which can be integrated into the dual networks of mutual learning to enhance the complementarity and further depress noise in the pseudo-labels. Specifically, we first introduce a parameter-free module, the WaveBlock, which creates a difference between two networks by waving blocks of feature maps differently. Then, an attention mechanism is leveraged to enlarge the difference created and discover more complementary features. Furthermore, two kinds of combination strategies, i.e. pre-attention and post-attention, are explored. Experiments demonstrate that the proposed method achieves state-of-the-art performance with significant improvements of 9.4%, 5.9%, 7.4%, and 7.7% in mAP on Duke-to-Market, Market-to-Duke, Duke-to-MSMT, and Market-to-MSMT UDA tasks, respectively.
M2Net: Multi-modal Multi-channel Network for Overall Survival Time Prediction of Brain Tumor Patients
Jun 01, 2020
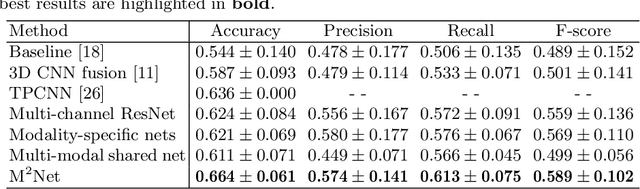
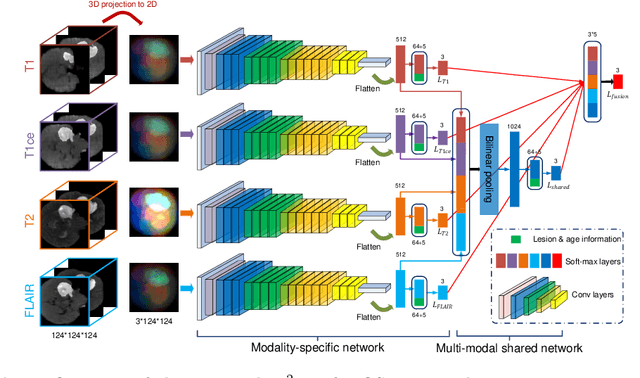
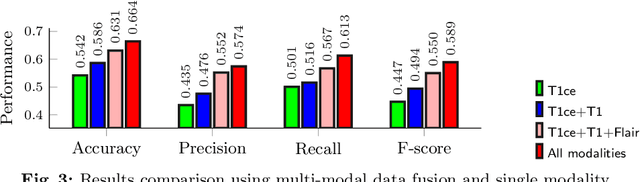
Early and accurate prediction of overall survival (OS) time can help to obtain better treatment planning for brain tumor patients. Although many OS time prediction methods have been developed and obtain promising results, there are still several issues. First, conventional prediction methods rely on radiomic features at the local lesion area of a magnetic resonance (MR) volume, which may not represent the full image or model complex tumor patterns. Second, different types of scanners (i.e., multi-modal data) are sensitive to different brain regions, which makes it challenging to effectively exploit the complementary information across multiple modalities and also preserve the modality-specific properties. Third, existing methods focus on prediction models, ignoring complex data-to-label relationships. To address the above issues, we propose an end-to-end OS time prediction model; namely, Multi-modal Multi-channel Network (M2Net). Specifically, we first project the 3D MR volume onto 2D images in different directions, which reduces computational costs, while preserving important information and enabling pre-trained models to be transferred from other tasks. Then, we use a modality-specific network to extract implicit and high-level features from different MR scans. A multi-modal shared network is built to fuse these features using a bilinear pooling model, exploiting their correlations to provide complementary information. Finally, we integrate the outputs from each modality-specific network and the multi-modal shared network to generate the final prediction result. Experimental results demonstrate the superiority of our M2Net model over other methods.
Inf-Net: Automatic COVID-19 Lung Infection Segmentation from CT Images
May 21, 2020Coronavirus Disease 2019 (COVID-19) spread globally in early 2020, causing the world to face an existential health crisis. Automated detection of lung infections from computed tomography (CT) images offers a great potential to augment the traditional healthcare strategy for tackling COVID-19. However, segmenting infected regions from CT slices faces several challenges, including high variation in infection characteristics, and low intensity contrast between infections and normal tissues. Further, collecting a large amount of data is impractical within a short time period, inhibiting the training of a deep model. To address these challenges, a novel COVID-19 Lung Infection Segmentation Deep Network (Inf-Net) is proposed to automatically identify infected regions from chest CT slices. In our Inf-Net, a parallel partial decoder is used to aggregate the high-level features and generate a global map. Then, the implicit reverse attention and explicit edge-attention are utilized to model the boundaries and enhance the representations. Moreover, to alleviate the shortage of labeled data, we present a semi-supervised segmentation framework based on a randomly selected propagation strategy, which only requires a few labeled images and leverages primarily unlabeled data. Our semi-supervised framework can improve the learning ability and achieve a higher performance. Extensive experiments on our COVID-SemiSeg and real CT volumes demonstrate that the proposed Inf-Net outperforms most cutting-edge segmentation models and advances the state-of-the-art performance.
Understanding and Correcting Low-quality Retinal Fundus Images for Clinical Analysis
May 12, 2020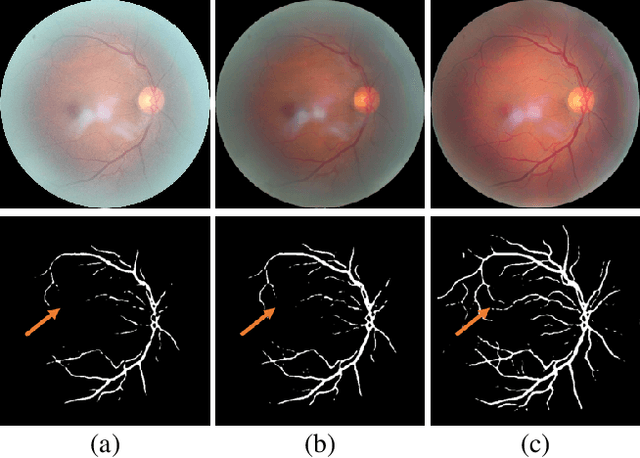
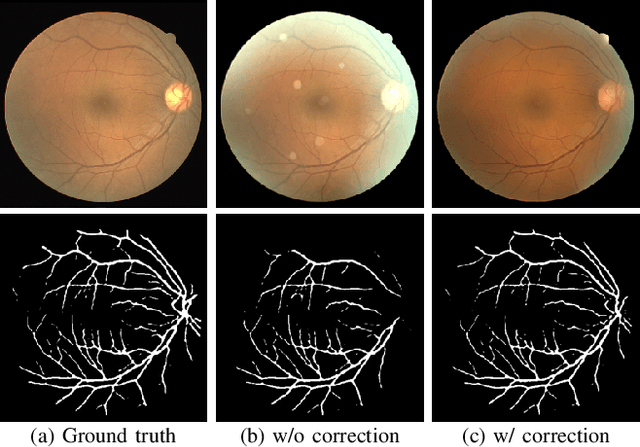
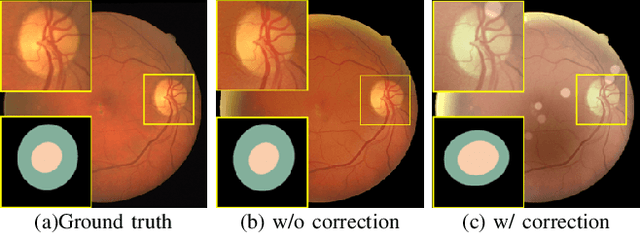
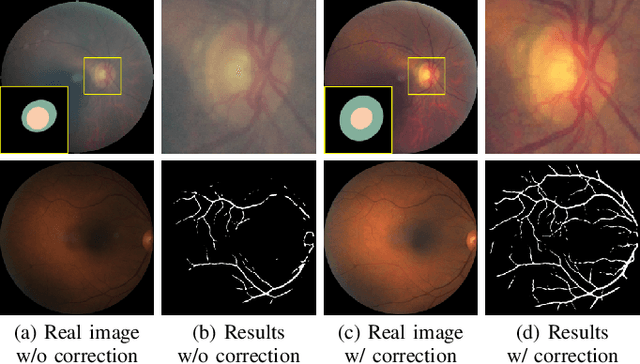
Retinal fundus images are widely used for clinical screening and diagnosis of eye diseases. However, fundus images captured by operators with various levels of experiences have a large variation in quality. Low-quality fundus images increase the uncertainty in clinical observation and lead to a risk of misdiagnosis. Due to the special optical beam of fundus imaging and retinal structure, the natural image enhancement methods cannot be utilized directly. In this paper, we first analyze the ophthalmoscope imaging system and model the reliable degradation of major inferior-quality factors, including uneven illumination, blur, and artifacts. Then, based on the degradation model, a clinical-oriented fundus enhancement network~(cofe-Net)~is proposed to suppress the global degradation factors, and simultaneously preserve anatomical retinal structures and pathological characteristics for clinical observation and analysis. Experiments on both synthetic and real fundus images demonstrate that our algorithm effectively corrects low-quality fundus images without losing retinal details. Moreover, we also show that the fundus correction method can benefit medical image analysis applications, e.g, retinal vessel segmentation and optic disc/cup detection.
Conditional Variational Image Deraining
May 08, 2020
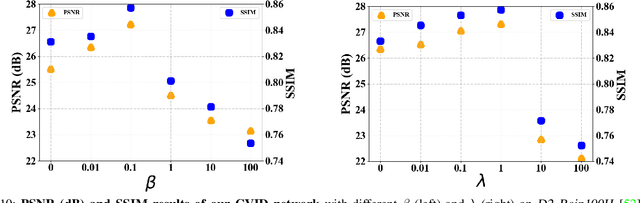
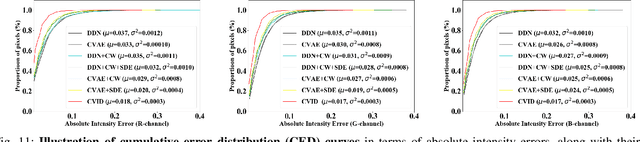
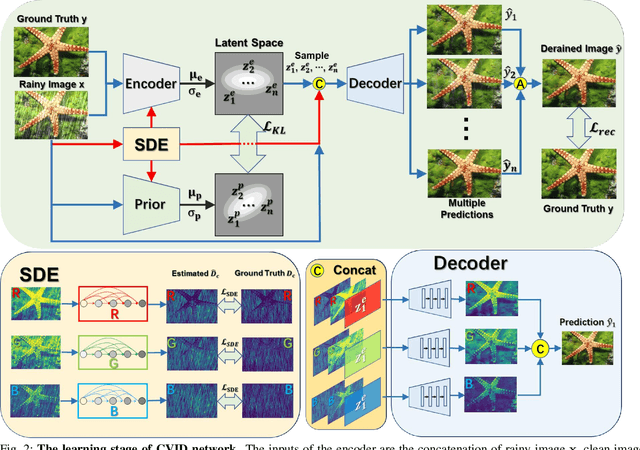
Image deraining is an important yet challenging image processing task. Though deterministic image deraining methods are developed with encouraging performance, they are infeasible to learn flexible representations for probabilistic inference and diverse predictions. Besides, rain intensity varies both in spatial locations and across color channels, making this task more difficult. In this paper, we propose a Conditional Variational Image Deraining (CVID) network for better deraining performance, leveraging the exclusive generative ability of Conditional Variational Auto-Encoder (CVAE) on providing diverse predictions for the rainy image. To perform spatially adaptive deraining, we propose a spatial density estimation (SDE) module to estimate a rain density map for each image. Since rain density varies across different color channels, we also propose a channel-wise (CW) deraining scheme. Experiments on synthesized and real-world datasets show that the proposed CVID network achieves much better performance than previous deterministic methods on image deraining. Extensive ablation studies validate the effectiveness of the proposed SDE module and CW scheme in our CVID network. The code is available at \url{https://github.com/Yingjun-Du/VID}.
Improved Residual Networks for Image and Video Recognition
Apr 10, 2020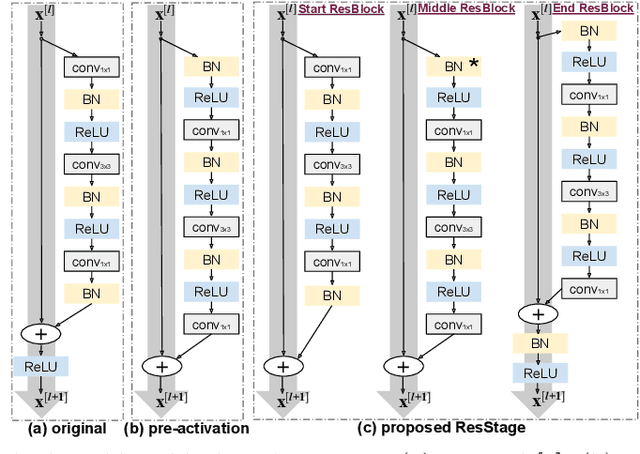
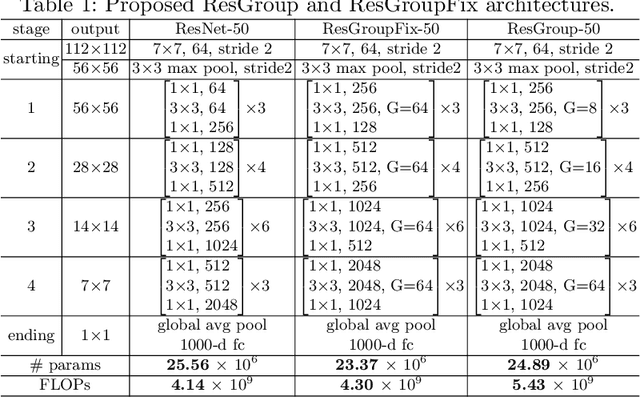
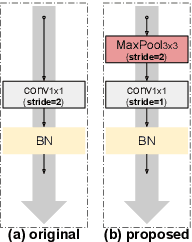
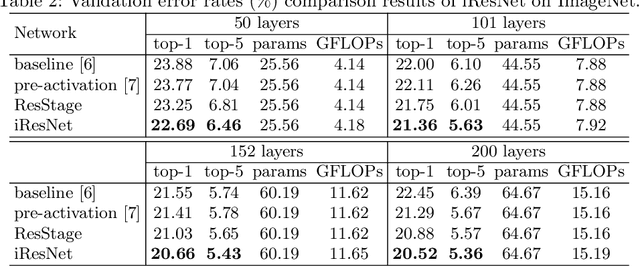
Residual networks (ResNets) represent a powerful type of convolutional neural network (CNN) architecture, widely adopted and used in various tasks. In this work we propose an improved version of ResNets. Our proposed improvements address all three main components of a ResNet: the flow of information through the network layers, the residual building block, and the projection shortcut. We are able to show consistent improvements in accuracy and learning convergence over the baseline. For instance, on ImageNet dataset, using the ResNet with 50 layers, for top-1 accuracy we can report a 1.19% improvement over the baseline in one setting and around 2% boost in another. Importantly, these improvements are obtained without increasing the model complexity. Our proposed approach allows us to train extremely deep networks, while the baseline shows severe optimization issues. We report results on three tasks over six datasets: image classification (ImageNet, CIFAR-10 and CIFAR-100), object detection (COCO) and video action recognition (Kinetics-400 and Something-Something-v2). In the deep learning era, we establish a new milestone for the depth of a CNN. We successfully train a 404-layer deep CNN on the ImageNet dataset and a 3002-layer network on CIFAR-10 and CIFAR-100, while the baseline is not able to converge at such extreme depths. Code is available at: https://github.com/iduta/iresnet
3D IoU-Net: IoU Guided 3D Object Detector for Point Clouds
Apr 10, 2020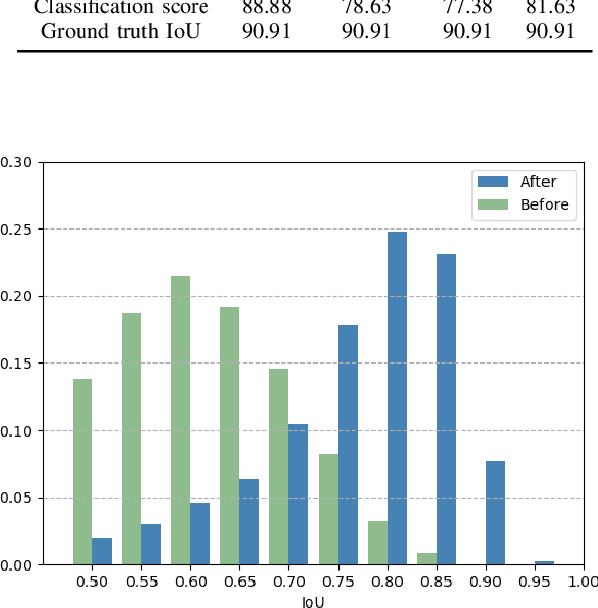
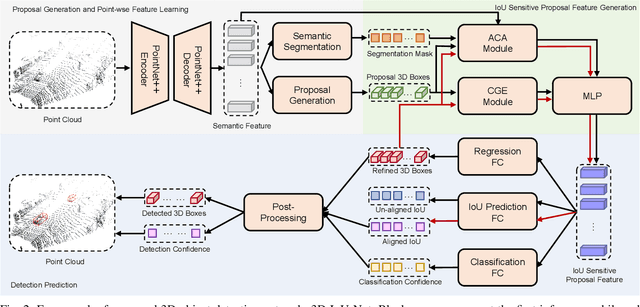
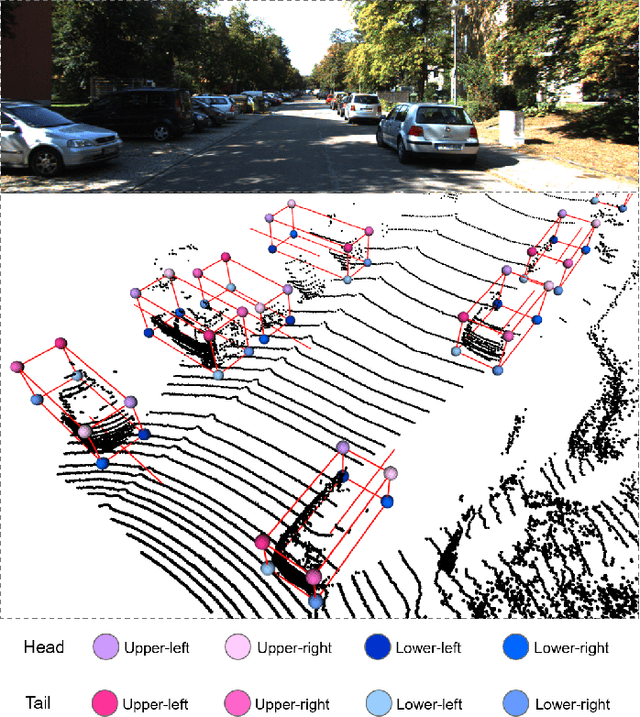
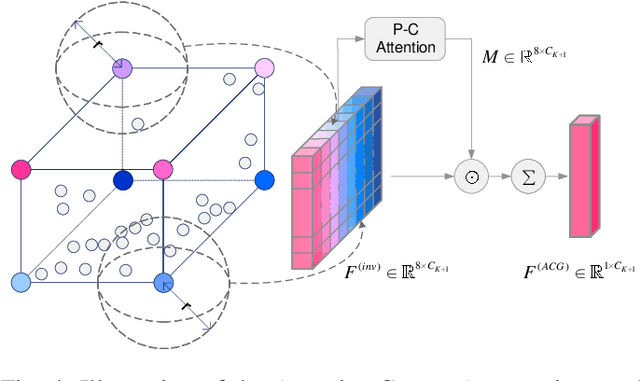
Most existing point cloud based 3D object detectors focus on the tasks of classification and box regression. However, another bottleneck in this area is achieving an accurate detection confidence for the Non-Maximum Suppression (NMS) post-processing. In this paper, we add a 3D IoU prediction branch to the regular classification and regression branches. The predicted IoU is used as the detection confidence for NMS. In order to obtain a more accurate IoU prediction, we propose a 3D IoU-Net with IoU sensitive feature learning and an IoU alignment operation. To obtain a perspective-invariant prediction head, we propose an Attentive Corner Aggregation (ACA) module by aggregating a local point cloud feature from each perspective of eight corners and adaptively weighting the contribution of each perspective with different attentions. We propose a Corner Geometry Encoding (CGE) module for geometry information embedding. To the best of our knowledge, this is the first time geometric embedding information has been introduced in proposal feature learning. These two feature parts are then adaptively fused by a multi-layer perceptron (MLP) network as our IoU sensitive feature. The IoU alignment operation is introduced to resolve the mismatching between the bounding box regression head and IoU prediction, thereby further enhancing the accuracy of IoU prediction. The experimental results on the KITTI car detection benchmark show that 3D IoU-Net with IoU perception achieves state-of-the-art performance.
FAIRS -- Soft Focus Generator and Attention for Robust Object Segmentation from Extreme Points
Apr 04, 2020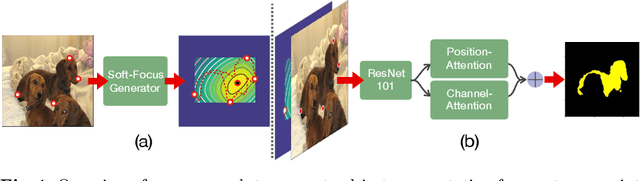
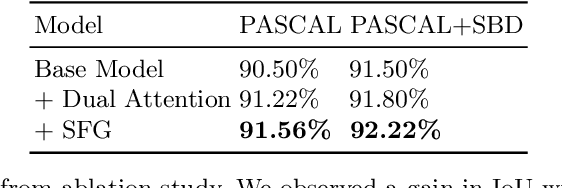
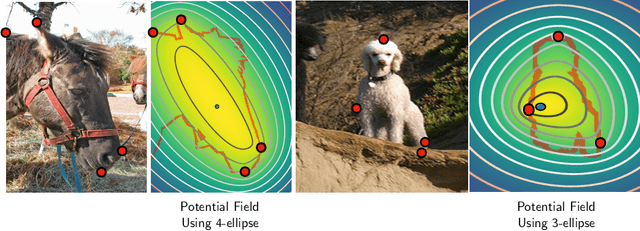
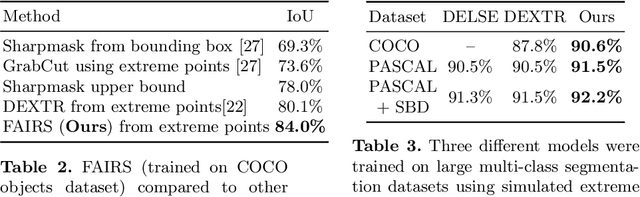
Semantic segmentation from user inputs has been actively studied to facilitate interactive segmentation for data annotation and other applications. Recent studies have shown that extreme points can be effectively used to encode user inputs. A heat map generated from the extreme points can be appended to the RGB image and input to the model for training. In this study, we present FAIRS -- a new approach to generate object segmentation from user inputs in the form of extreme points and corrective clicks. We propose a novel approach for effectively encoding the user input from extreme points and corrective clicks, in a novel and scalable manner that allows the network to work with a variable number of clicks, including corrective clicks for output refinement. We also integrate a dual attention module with our approach to increase the efficacy of the model in preferentially attending to the objects. We demonstrate that these additions help achieve significant improvements over state-of-the-art in dense object segmentation from user inputs, on multiple large-scale datasets. Through experiments, we demonstrate our method's ability to generate high-quality training data as well as its scalability in incorporating extreme points, guiding clicks, and corrective clicks in a principled manner.
Pathological Retinal Region Segmentation From OCT Images Using Geometric Relation Based Augmentation
Apr 03, 2020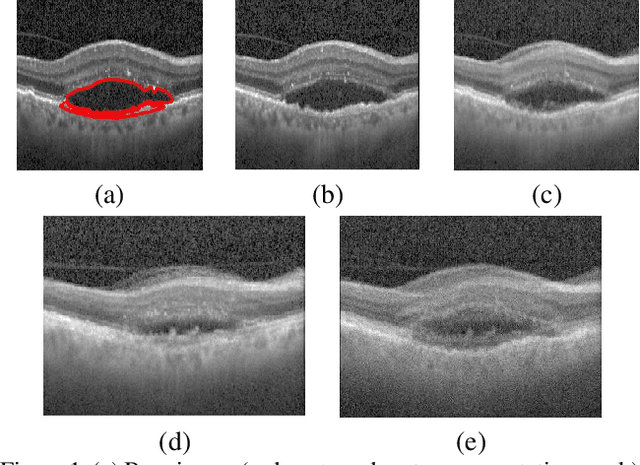
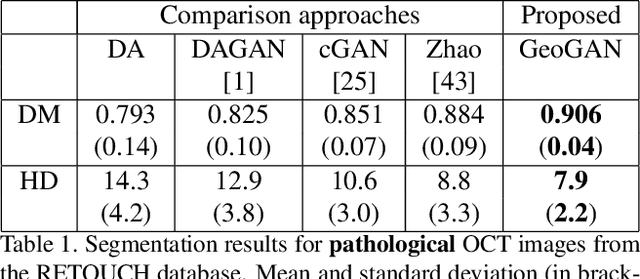
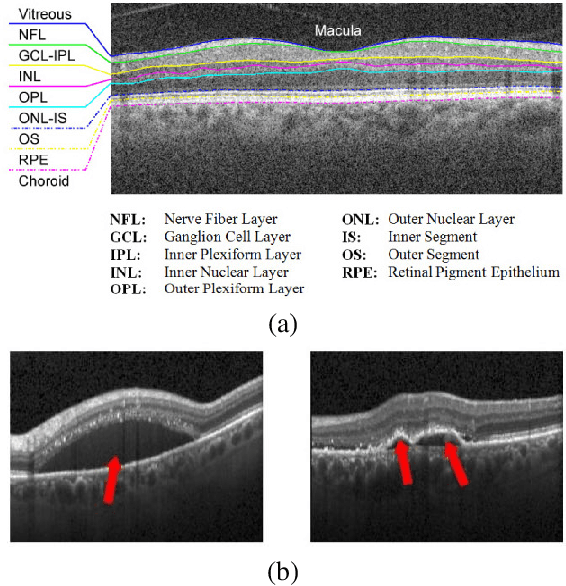
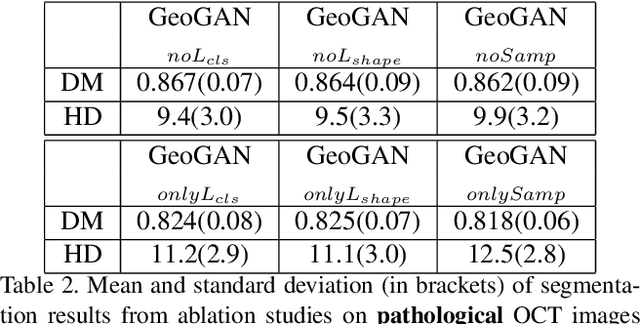
Medical image segmentation is an important task for computer aided diagnosis. Pixelwise manual annotations of large datasets require high expertise and is time consuming. Conventional data augmentations have limited benefit by not fully representing the underlying distribution of the training set, thus affecting model robustness when tested on images captured from different sources. Prior work leverages synthetic images for data augmentation ignoring the interleaved geometric relationship between different anatomical labels. We propose improvements over previous GAN-based medical image synthesis methods by jointly encoding the intrinsic relationship of geometry and shape. Latent space variable sampling results in diverse generated images from a base image and improves robustness. Given those augmented images generated by our method, we train the segmentation network to enhance the segmentation performance of retinal optical coherence tomography (OCT) images. The proposed method outperforms state-of-the-art segmentation methods on the public RETOUCH dataset having images captured from different acquisition procedures. Ablation studies and visual analysis also demonstrate benefits of integrating geometry and diversity.