 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-label Classification with Panoptic Context Aggregation Networks
Dec 29, 2025Context modeling is crucial for visual recognition, enabling highly discriminative image representations by integrating both intrinsic and extrinsic relationships between objects and labels in images. A limitation in current approaches is their focus on basic geometric relationships or localized features, often neglecting cross-scale contextual interactions between objects. This paper introduces the Deep Panoptic Context Aggregation Network (PanCAN), a novel approach that hierarchically integrates multi-order geometric contexts through cross-scale feature aggregation in a high-dimensional Hilbert space. Specifically, PanCAN learns multi-order neighborhood relationships at each scale by combining random walks with an attention mechanism. Modules from different scales are cascaded, where salient anchors at a finer scale are selected and their neighborhood features are dynamically fused via attention. This enables effective cross-scale modeling that significantly enhances complex scene understanding by combining multi-order and cross-scale context-aware features. Extensive multi-label classification experiments on NUS-WIDE, PASCAL VOC2007, and MS-COCO benchmarks demonstrate that PanCAN consistently achieves competitive results, outperforming state-of-the-art techniques in both quantitative and qualitative evaluations, thereby substantially improving multi-label classification performance.
Sat2RealCity: Geometry-Aware and Appearance-Controllable 3D Urban Generation from Satellite Imagery
Nov 14, 2025Recent advances in generative modeling have substantially enhanced 3D urban generation, enabling applications in digital twins, virtual cities, and large-scale simulations. However, existing methods face two key challenges: (1) the need for large-scale 3D city assets for supervised training, which are difficult and costly to obtain, and (2) reliance on semantic or height maps, which are used exclusively for generating buildings in virtual worlds and lack connection to real-world appearance, limiting the realism and generalizability of generated cities. To address these limitations, we propose Sat2RealCity, a geometry-aware and appearance-controllable framework for 3D urban generation from real-world satellite imagery. Unlike previous city-level generation methods, Sat2RealCity builds generation upon individual building entities, enabling the use of rich priors and pretrained knowledge from 3D object generation while substantially reducing dependence on large-scale 3D city assets. Specifically, (1) we introduce the OSM-based spatial priors strategy to achieve interpretable geometric generation from spatial topology to building instances; (2) we design an appearance-guided controllable modeling mechanism for fine-grained appearance realism and style control; and (3) we construct an MLLM-powered semantic-guided generation pipeline, bridging semantic interpretation and geometric reconstruction. Extensive quantitative and qualitative experiments demonstrate that Sat2RealCity significantly surpasses existing baselines in structural consistency and appearance realism, establishing a strong foundation for real-world aligned 3D urban content creation. The code will be released soon.
Multi-label Classification using Deep Multi-order Context-aware Kernel Networks
Dec 27, 2024



Multi-label classification is a challenging task in pattern recognition. Many deep learning methods have been proposed and largely enhanced classification performance. However, most of the existing sophisticated methods ignore context in the models' learning process. Since context may provide additional cues to the learned models, it may significantly boost classification performances. In this work, we make full use of context information (namely geometrical structure of images) in order to learn better context-aware similarities (a.k.a. kernels) between images. We reformulate context-aware kernel design as a feed-forward network that outputs explicit kernel mapping features. Our obtained context-aware kernel network further leverages multiple orders of patch neighbors within different distances, resulting into a more discriminating Deep Multi-order Context-aware Kernel Network (DMCKN) for multi-label classification. We evaluate the proposed method on the challenging Corel5K and NUS-WIDE benchmarks, and empirical results show that our method obtains competitive performances against the related state-of-the-art, and both quantitative and qualitative performances corroborate its effectiveness and superiority for multi-label image classification.
Hierarchical Human Parsing with Typed Part-Relation Reasoning
Mar 11, 2020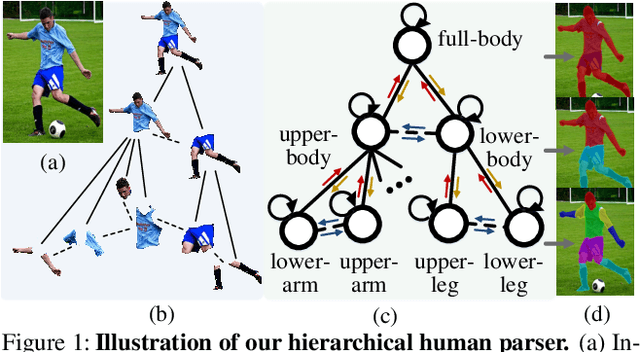
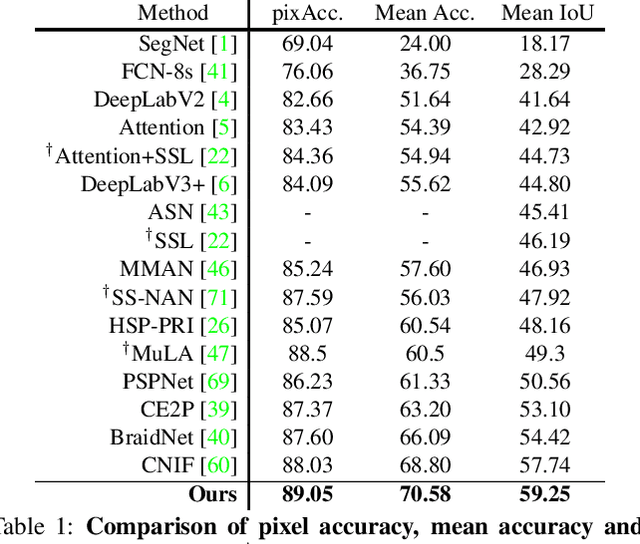
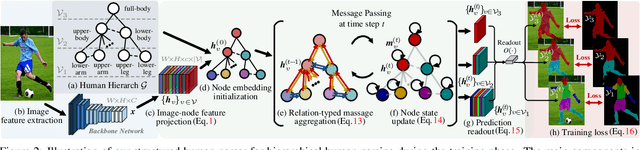
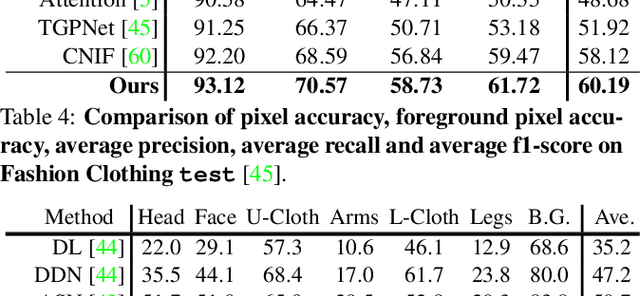
Human parsing is for pixel-wise human semantic understanding. As human bodies are underlying hierarchically structured, how to model human structures is the central theme in this task. Focusing on this, we seek to simultaneously exploit the representational capacity of deep graph networks and the hierarchical human structures. In particular, we provide following two contributions. First, three kinds of part relations, i.e., decomposition, composition, and dependency, are, for the first time, completely and precisely described by three distinct relation networks. This is in stark contrast to previous parsers, which only focus on a portion of the relations and adopt a type-agnostic relation modeling strategy. More expressive relation information can be captured by explicitly imposing the parameters in the relation networks to satisfy the specific characteristics of different relations. Second, previous parsers largely ignore the need for an approximation algorithm over the loopy human hierarchy, while we instead address an iterative reasoning process, by assimilating generic message-passing networks with their edge-typed, convolutional counterparts. With these efforts, our parser lays the foundation for more sophisticated and flexible human relation patterns of reasoning. Comprehensive experiments on five datasets demonstrate that our parser sets a new state-of-the-art on each.