 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDriveExplorer: Images-Only Decoupled 4D Reconstruction with Progressive Restoration for Driving View Extrapolation
Dec 30, 2025This paper presents an effective solution for view extrapolation in autonomous driving scenarios. Recent approaches focus on generating shifted novel view images from given viewpoints using diffusion models. However, these methods heavily rely on priors such as LiDAR point clouds, 3D bounding boxes, and lane annotations, which demand expensive sensors or labor-intensive labeling, limiting applicability in real-world deployment. In this work, with only images and optional camera poses, we first estimate a global static point cloud and per-frame dynamic point clouds, fusing them into a unified representation. We then employ a deformable 4D Gaussian framework to reconstruct the scene. The initially trained 4D Gaussian model renders degraded and pseudo-images to train a video diffusion model. Subsequently, progressively shifted Gaussian renderings are iteratively refined by the diffusion model,and the enhanced results are incorporated back as training data for 4DGS. This process continues until extrapolation reaches the target viewpoints. Compared with baselines, our method produces higher-quality images at novel extrapolated viewpoints.
Multimodal Large Models Are Effective Action Anticipators
Jan 01, 2025



The task of long-term action anticipation demands solutions that can effectively model temporal dynamics over extended periods while deeply understanding the inherent semantics of actions. Traditional approaches, which primarily rely on recurrent units or Transformer layers to capture long-term dependencies, often fall short in addressing these challenges. Large Language Models (LLMs), with their robust sequential modeling capabilities and extensive commonsense knowledge, present new opportunities for long-term action anticipation. In this work, we introduce the ActionLLM framework, a novel approach that treats video sequences as successive tokens, leveraging LLMs to anticipate future actions. Our baseline model simplifies the LLM architecture by setting future tokens, incorporating an action tuning module, and reducing the textual decoder layer to a linear layer, enabling straightforward action prediction without the need for complex instructions or redundant descriptions. To further harness the commonsense reasoning of LLMs, we predict action categories for observed frames and use sequential textual clues to guide semantic understanding. In addition, we introduce a Cross-Modality Interaction Block, designed to explore the specificity within each modality and capture interactions between vision and textual modalities, thereby enhancing multimodal tuning. Extensive experiments on benchmark datasets demonstrate the superiority of the proposed ActionLLM framework, encouraging a promising direction to explore LLMs in the context of action anticipation. Code is available at https://github.com/2tianyao1/ActionLLM.git.
LFMamba: Light Field Image Super-Resolution with State Space Model
Jun 18, 2024



Recent years have witnessed significant advancements in light field image super-resolution (LFSR) owing to the progress of modern neural networks. However, these methods often face challenges in capturing long-range dependencies (CNN-based) or encounter quadratic computational complexities (Transformer-based), which limit their performance. Recently, the State Space Model (SSM) with selective scanning mechanism (S6), exemplified by Mamba, has emerged as a superior alternative in various vision tasks compared to traditional CNN- and Transformer-based approaches, benefiting from its effective long-range sequence modeling capability and linear-time complexity. Therefore, integrating S6 into LFSR becomes compelling, especially considering the vast data volume of 4D light fields. However, the primary challenge lies in \emph{designing an appropriate scanning method for 4D light fields that effectively models light field features}. To tackle this, we employ SSMs on the informative 2D slices of 4D LFs to fully explore spatial contextual information, complementary angular information, and structure information. To achieve this, we carefully devise a basic SSM block characterized by an efficient SS2D mechanism that facilitates more effective and efficient feature learning on these 2D slices. Based on the above two designs, we further introduce an SSM-based network for LFSR termed LFMamba. Experimental results on LF benchmarks demonstrate the superior performance of LFMamba. Furthermore, extensive ablation studies are conducted to validate the efficacy and generalization ability of our proposed method. We expect that our LFMamba shed light on effective representation learning of LFs with state space models.
Multi-granularity Backprojection Transformer for Remote Sensing Image Super-Resolution
Oct 19, 2023Backprojection networks have achieved promising super-resolution performance for nature images but not well be explored in the remote sensing image super-resolution (RSISR) field due to the high computation costs. In this paper, we propose a Multi-granularity Backprojection Transformer termed MBT for RSISR. MBT incorporates the backprojection learning strategy into a Transformer framework. It consists of Scale-aware Backprojection-based Transformer Layers (SPTLs) for scale-aware low-resolution feature learning and Context-aware Backprojection-based Transformer Blocks (CPTBs) for hierarchical feature learning. A backprojection-based reconstruction module (PRM) is also introduced to enhance the hierarchical features for image reconstruction. MBT stands out by efficiently learning low-resolution features without excessive modules for high-resolution processing, resulting in lower computational resources. Experiment results on UCMerced and AID datasets demonstrate that MBT obtains state-of-the-art results compared to other leading methods.
Detail-Preserving Transformer for Light Field Image Super-Resolution
Jan 02, 2022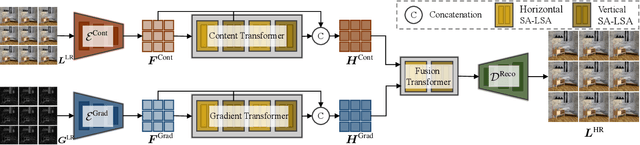
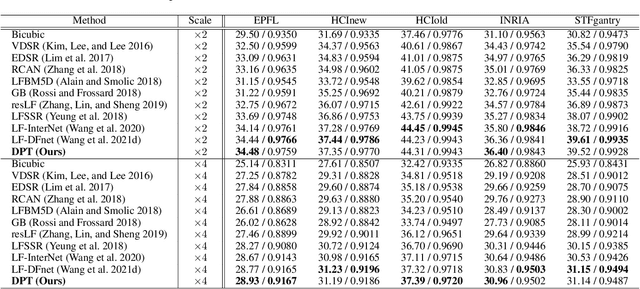
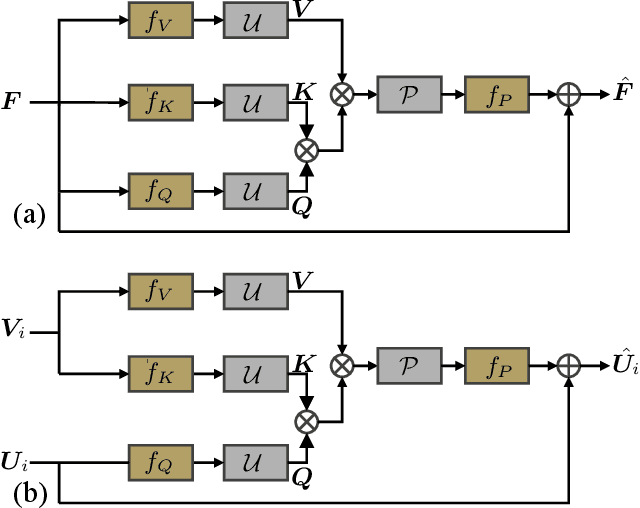
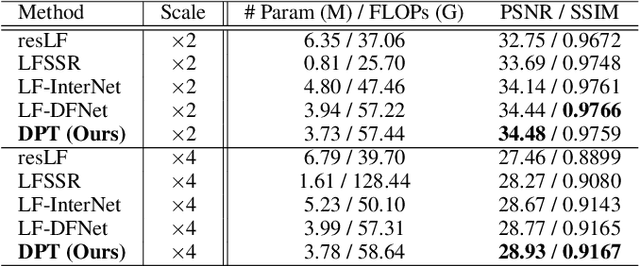
Recently, numerous algorithms have been developed to tackle the problem of light field super-resolution (LFSR), i.e., super-resolving low-resolution light fields to gain high-resolution views. Despite delivering encouraging results, these approaches are all convolution-based, and are naturally weak in global relation modeling of sub-aperture images necessarily to characterize the inherent structure of light fields. In this paper, we put forth a novel formulation built upon Transformers, by treating LFSR as a sequence-to-sequence reconstruction task. In particular, our model regards sub-aperture images of each vertical or horizontal angular view as a sequence, and establishes long-range geometric dependencies within each sequence via a spatial-angular locally-enhanced self-attention layer, which maintains the locality of each sub-aperture image as well. Additionally, to better recover image details, we propose a detail-preserving Transformer (termed as DPT), by leveraging gradient maps of light field to guide the sequence learning. DPT consists of two branches, with each associated with a Transformer for learning from an original or gradient image sequence. The two branches are finally fused to obtain comprehensive feature representations for reconstruction. Evaluations are conducted on a number of light field datasets, including real-world scenes and synthetic data. The proposed method achieves superior performance comparing with other state-of-the-art schemes. Our code is publicly available at: https://github.com/BITszwang/DPT.
Motion-Attentive Transition for Zero-Shot Video Object Segmentation
Mar 15, 2020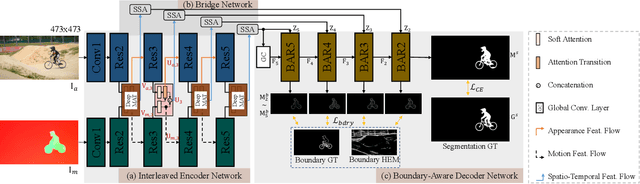
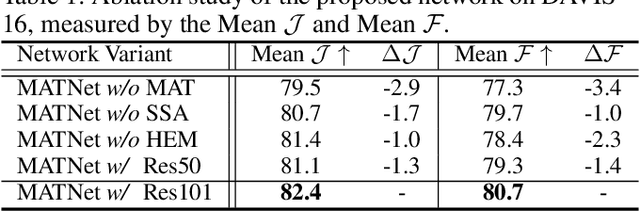
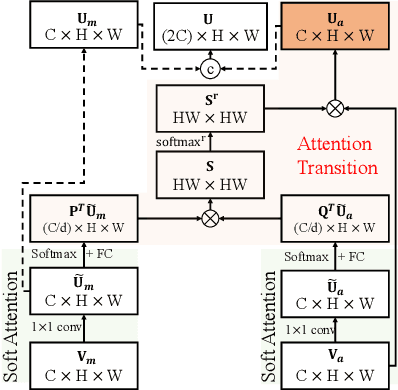
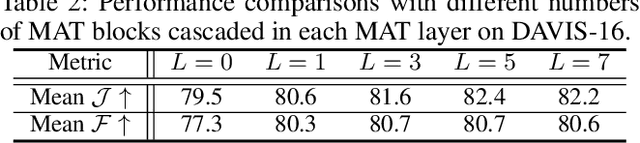
In this paper, we present a novel Motion-Attentive Transition Network (MATNet) for zero-shot video object segmentation, which provides a new way of leveraging motion information to reinforce spatio-temporal object representation. An asymmetric attention block, called Motion-Attentive Transition (MAT), is designed within a two-stream encoder, which transforms appearance features into motion-attentive representations at each convolutional stage. In this way, the encoder becomes deeply interleaved, allowing for closely hierarchical interactions between object motion and appearance. This is superior to the typical two-stream architecture, which treats motion and appearance separately in each stream and often suffers from overfitting to appearance information. Additionally, a bridge network is proposed to obtain a compact, discriminative and scale-sensitive representation for multi-level encoder features, which is further fed into a decoder to achieve segmentation results. Extensive experiments on three challenging public benchmarks (i.e. DAVIS-16, FBMS and Youtube-Objects) show that our model achieves compelling performance against the state-of-the-arts.