 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransformer-Based Source-Free Domain Adaptation
May 28, 2021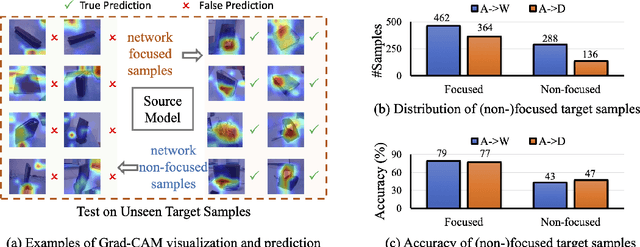
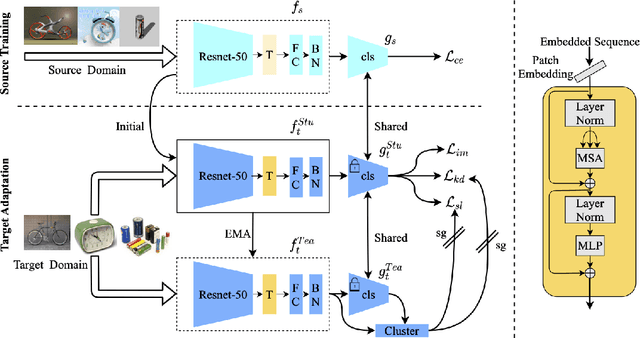
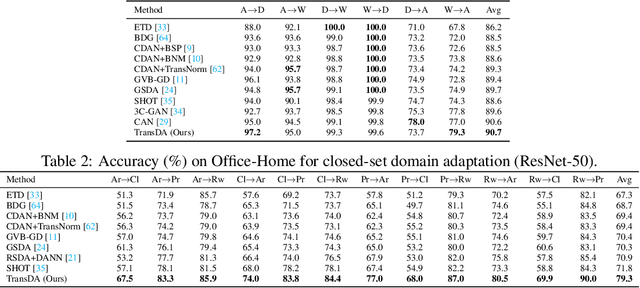
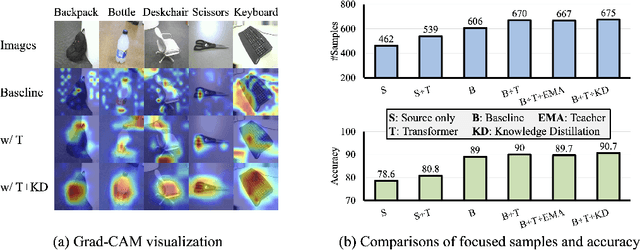
In this paper, we study the task of source-free domain adaptation (SFDA), where the source data are not available during target adaptation. Previous works on SFDA mainly focus on aligning the cross-domain distributions. However, they ignore the generalization ability of the pretrained source model, which largely influences the initial target outputs that are vital to the target adaptation stage. To address this, we make the interesting observation that the model accuracy is highly correlated with whether or not attention is focused on the objects in an image. To this end, we propose a generic and effective framework based on Transformer, named TransDA, for learning a generalized model for SFDA. Specifically, we apply the Transformer as the attention module and inject it into a convolutional network. By doing so, the model is encouraged to turn attention towards the object regions, which can effectively improve the model's generalization ability on the target domains. Moreover, a novel self-supervised knowledge distillation approach is proposed to adapt the Transformer with target pseudo-labels, thus further encouraging the network to focus on the object regions. Experiments on three domain adaptation tasks, including closed-set, partial-set, and open-set adaption, demonstrate that TransDA can greatly improve the adaptation accuracy and produce state-of-the-art results. The source code and trained models are available at https://github.com/ygjwd12345/TransDA.
Progressively Normalized Self-Attention Network for Video Polyp Segmentation
May 24, 2021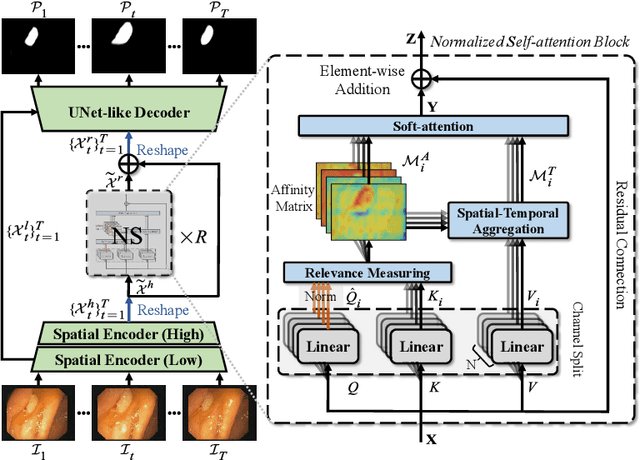
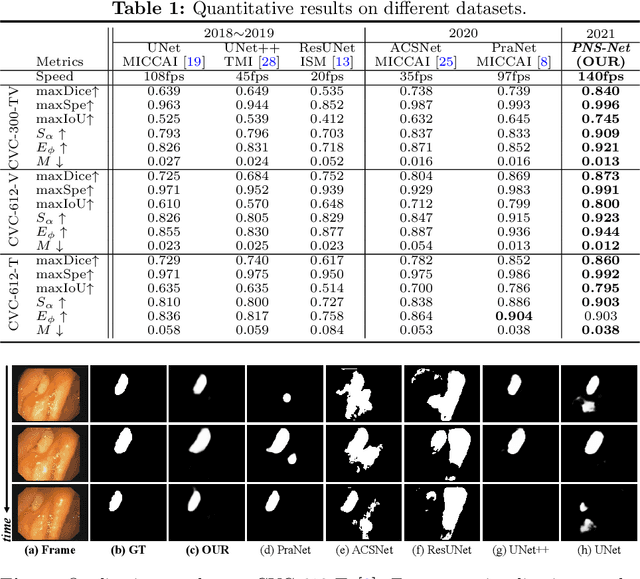
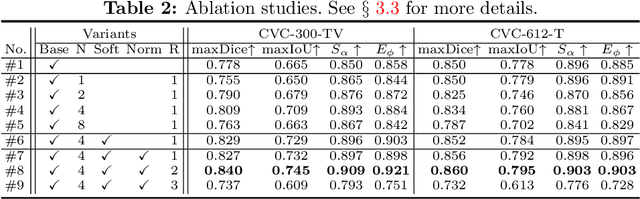
Existing video polyp segmentation (VPS) models typically employ convolutional neural networks (CNNs) to extract features. However, due to their limited receptive fields, CNNs can not fully exploit the global temporal and spatial information in successive video frames, resulting in false-positive segmentation results. In this paper, we propose the novel PNS-Net (Progressively Normalized Self-attention Network), which can efficiently learn representations from polyp videos with real-time speed (~140fps) on a single RTX 2080 GPU and no post-processing. Our PNS-Net is based solely on a basic normalized self-attention block, equipping with recurrence and CNNs entirely. Experiments on challenging VPS datasets demonstrate that the proposed PNS-Net achieves state-of-the-art performance. We also conduct extensive experiments to study the effectiveness of the channel split, soft-attention, and progressive learning strategy. We find that our PNS-Net works well under different settings, making it a promising solution to the VPS task.
Attentional Prototype Inference for Few-Shot Semantic Segmentation
May 14, 2021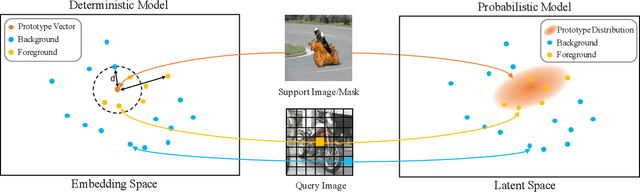
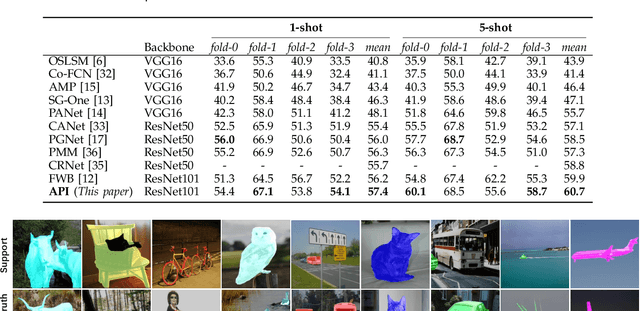
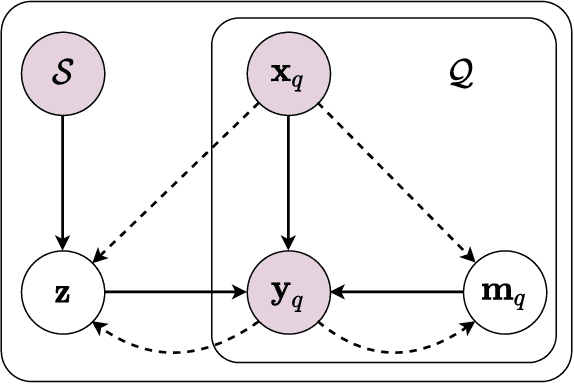
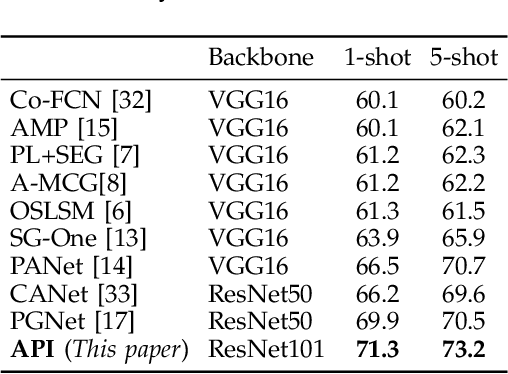
This paper aims to address few-shot semantic segmentation. While existing prototype-based methods have achieved considerable success, they suffer from uncertainty and ambiguity caused by limited labelled examples. In this work, we propose attentional prototype inference (API), a probabilistic latent variable framework for few-shot semantic segmentation. We define a global latent variable to represent the prototype of each object category, which we model as a probabilistic distribution. The probabilistic modeling of the prototype enhances the model's generalization ability by handling the inherent uncertainty caused by limited data and intra-class variations of objects. To further enhance the model, we introduce a local latent variable to represent the attention map of each query image, which enables the model to attend to foreground objects while suppressing background. The optimization of the proposed model is formulated as a variational Bayesian inference problem, which is established by amortized inference networks.We conduct extensive experiments on three benchmarks, where our proposal obtains at least competitive and often better performance than state-of-the-art methods. We also provide comprehensive analyses and ablation studies to gain insight into the effectiveness of our method for few-shot semantic segmentation.
DONet: Dual-Octave Network for Fast MR Image Reconstruction
May 12, 2021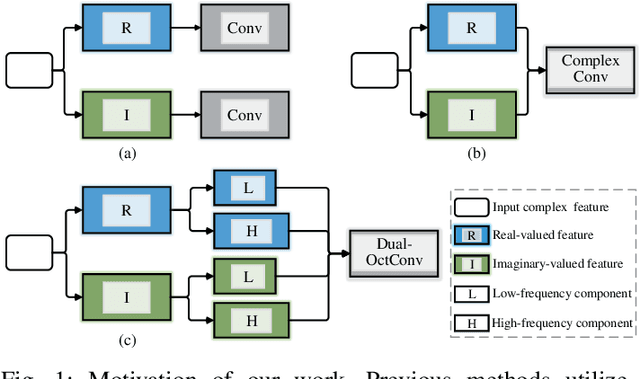
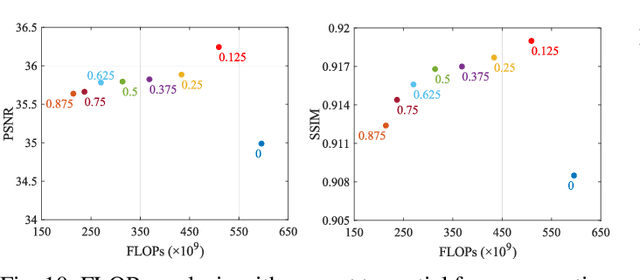

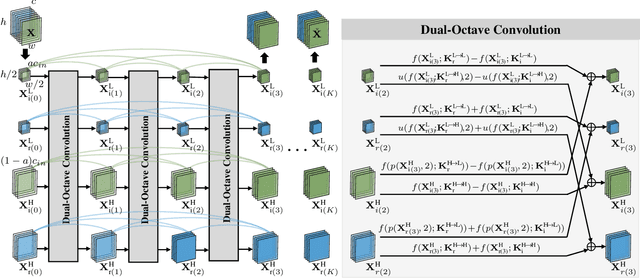
Magnetic resonance (MR) image acquisition is an inherently prolonged process, whose acceleration has long been the subject of research. This is commonly achieved by obtaining multiple undersampled images, simultaneously, through parallel imaging. In this paper, we propose the Dual-Octave Network (DONet), which is capable of learning multi-scale spatial-frequency features from both the real and imaginary components of MR data, for fast parallel MR image reconstruction. More specifically, our DONet consists of a series of Dual-Octave convolutions (Dual-OctConv), which are connected in a dense manner for better reuse of features. In each Dual-OctConv, the input feature maps and convolutional kernels are first split into two components (ie, real and imaginary), and then divided into four groups according to their spatial frequencies. Then, our Dual-OctConv conducts intra-group information updating and inter-group information exchange to aggregate the contextual information across different groups. Our framework provides three appealing benefits: (i) It encourages information interaction and fusion between the real and imaginary components at various spatial frequencies to achieve richer representational capacity. (ii) The dense connections between the real and imaginary groups in each Dual-OctConv make the propagation of features more efficient by feature reuse. (iii) DONet enlarges the receptive field by learning multiple spatial-frequency features of both the real and imaginary components. Extensive experiments on two popular datasets (ie, clinical knee and fastMRI), under different undersampling patterns and acceleration factors, demonstrate the superiority of our model in accelerated parallel MR image reconstruction.
A Bit More Bayesian: Domain-Invariant Learning with Uncertainty
May 09, 2021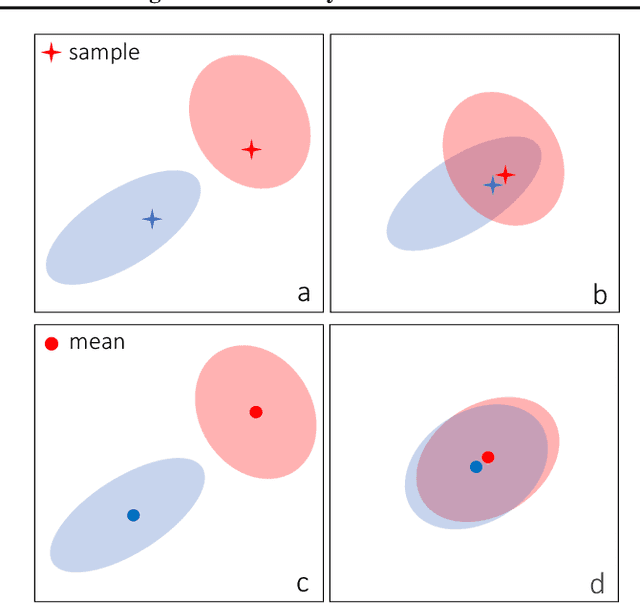
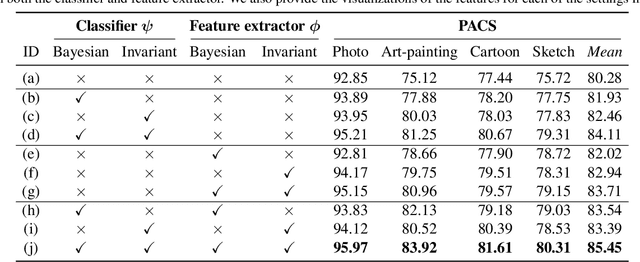
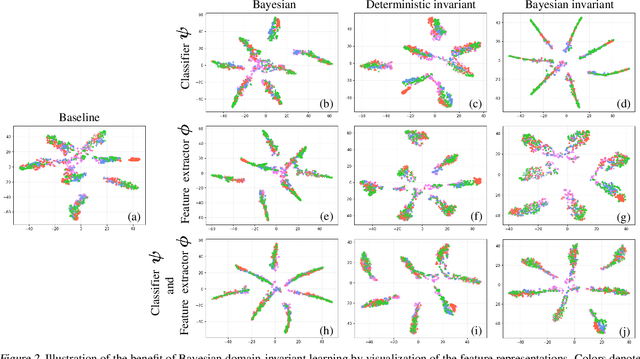
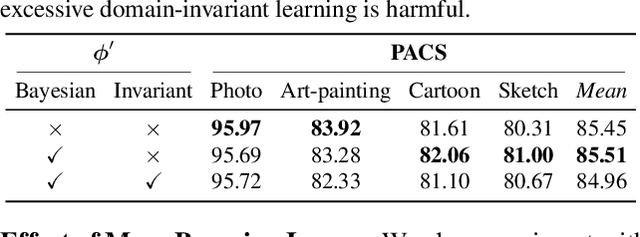
Domain generalization is challenging due to the domain shift and the uncertainty caused by the inaccessibility of target domain data. In this paper, we address both challenges with a probabilistic framework based on variational Bayesian inference, by incorporating uncertainty into neural network weights. We couple domain invariance in a probabilistic formula with the variational Bayesian inference. This enables us to explore domain-invariant learning in a principled way. Specifically, we derive domain-invariant representations and classifiers, which are jointly established in a two-layer Bayesian neural network. We empirically demonstrate the effectiveness of our proposal on four widely used cross-domain visual recognition benchmarks. Ablation studies validate the synergistic benefits of our Bayesian treatment when jointly learning domain-invariant representations and classifiers for domain generalization. Further, our method consistently delivers state-of-the-art mean accuracy on all benchmarks.
MetaKernel: Learning Variational Random Features with Limited Labels
May 08, 2021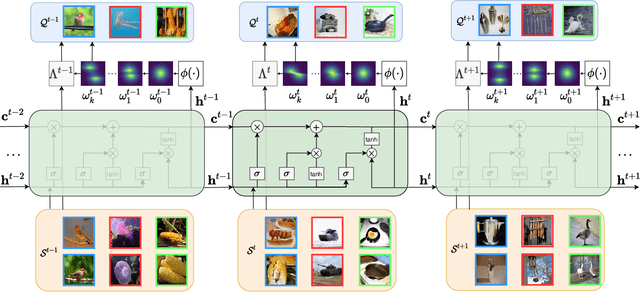
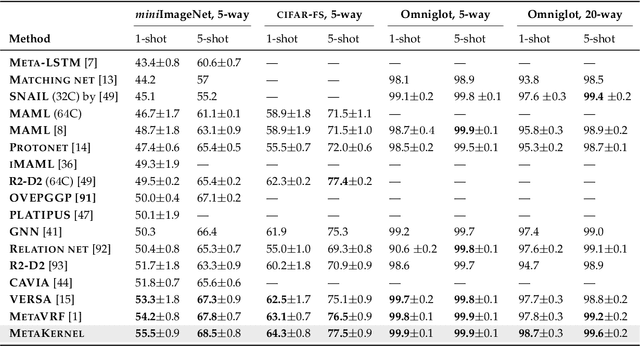
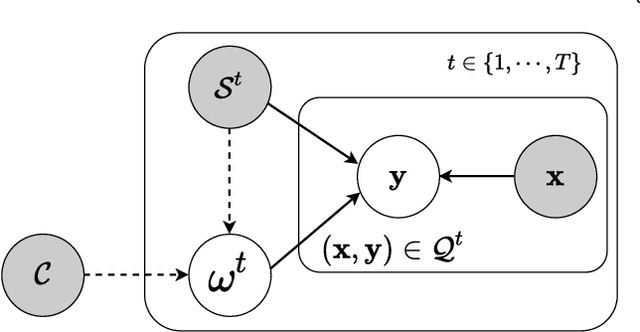
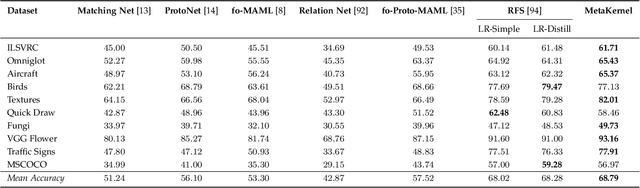
Few-shot learning deals with the fundamental and challenging problem of learning from a few annotated samples, while being able to generalize well on new tasks. The crux of few-shot learning is to extract prior knowledge from related tasks to enable fast adaptation to a new task with a limited amount of data. In this paper, we propose meta-learning kernels with random Fourier features for few-shot learning, we call MetaKernel. Specifically, we propose learning variational random features in a data-driven manner to obtain task-specific kernels by leveraging the shared knowledge provided by related tasks in a meta-learning setting. We treat the random feature basis as the latent variable, which is estimated by variational inference. The shared knowledge from related tasks is incorporated into a context inference of the posterior, which we achieve via a long-short term memory module. To establish more expressive kernels, we deploy conditional normalizing flows based on coupling layers to achieve a richer posterior distribution over random Fourier bases. The resultant kernels are more informative and discriminative, which further improves the few-shot learning. To evaluate our method, we conduct extensive experiments on both few-shot image classification and regression tasks. A thorough ablation study demonstrates that the effectiveness of each introduced component in our method. The benchmark results on fourteen datasets demonstrate MetaKernel consistently delivers at least comparable and often better performance than state-of-the-art alternatives.
Salient Objects in Clutter
May 07, 2021

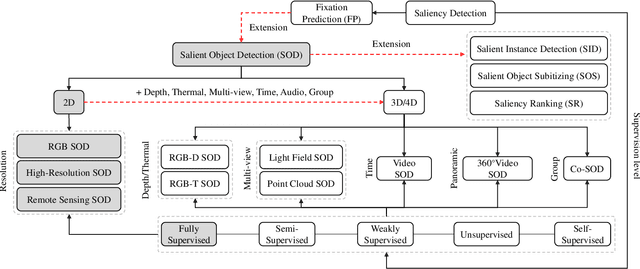
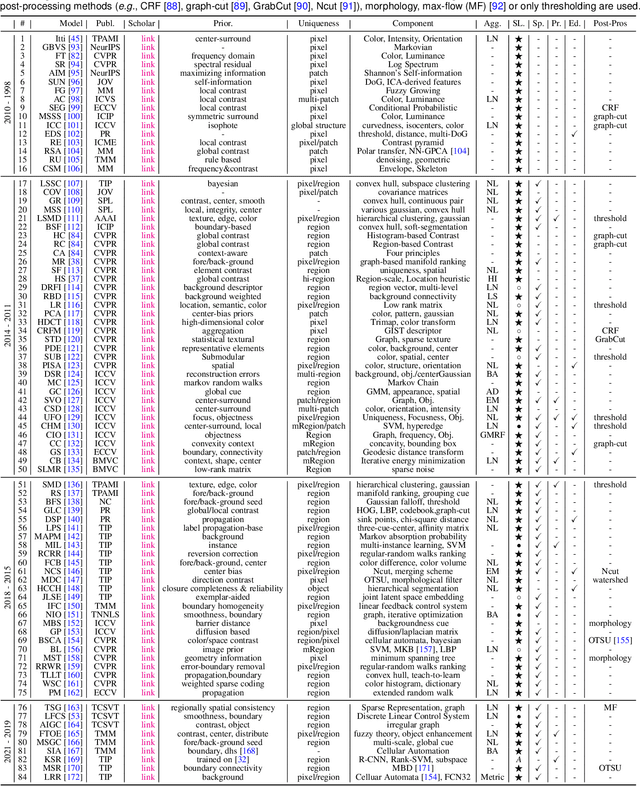
This paper identifies and addresses a serious design bias of existing salient object detection (SOD) datasets, which unrealistically assume that each image should contain at least one clear and uncluttered salient object. This design bias has led to a saturation in performance for state-of-the-art SOD models when evaluated on existing datasets. However, these models are still far from satisfactory when applied to real-world scenes. Based on our analyses, we propose a new high-quality dataset and update the previous saliency benchmark. Specifically, our dataset, called Salient Objects in Clutter (SOC), includes images with both salient and non-salient objects from several common object categories. In addition to object category annotations, each salient image is accompanied by attributes that reflect common challenges in real-world scenes, which can help provide deeper insight into the SOD problem. Further, with a given saliency encoder, e.g., the backbone network, existing saliency models are designed to achieve mapping from the training image set to the training ground-truth set. We, therefore, argue that improving the dataset can yield higher performance gains than focusing only on the decoder design. With this in mind, we investigate several dataset-enhancement strategies, including label smoothing to implicitly emphasize salient boundaries, random image augmentation to adapt saliency models to various scenarios, and self-supervised learning as a regularization strategy to learn from small datasets. Our extensive results demonstrate the effectiveness of these tricks. We also provide a comprehensive benchmark for SOD, which can be found in our repository: http://dpfan.net/SOCBenchmark.
ISTR: End-to-End Instance Segmentation with Transformers
May 06, 2021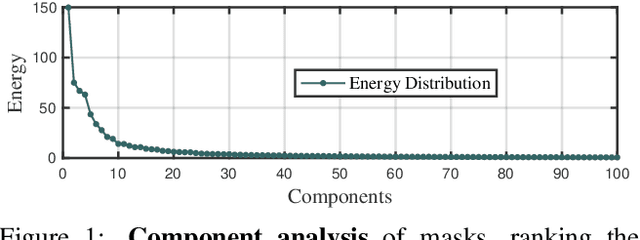
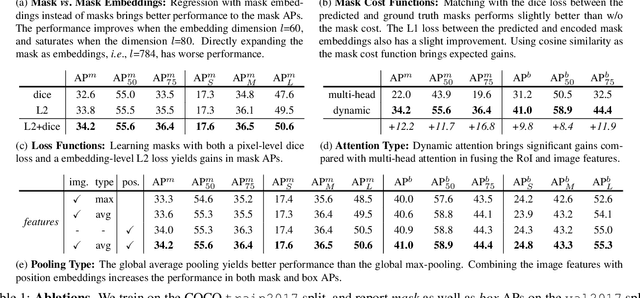
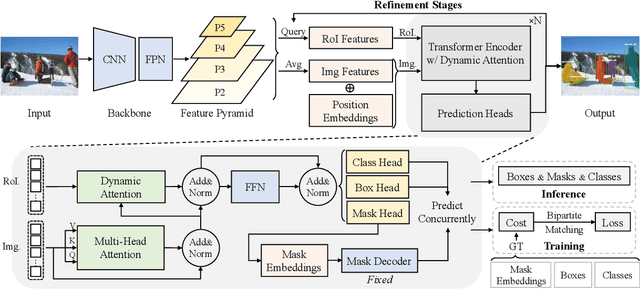
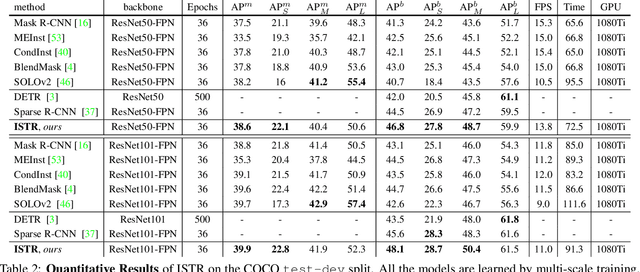
End-to-end paradigms significantly improve the accuracy of various deep-learning-based computer vision models. To this end, tasks like object detection have been upgraded by replacing non-end-to-end components, such as removing non-maximum suppression by training with a set loss based on bipartite matching. However, such an upgrade is not applicable to instance segmentation, due to its significantly higher output dimensions compared to object detection. In this paper, we propose an instance segmentation Transformer, termed ISTR, which is the first end-to-end framework of its kind. ISTR predicts low-dimensional mask embeddings, and matches them with ground truth mask embeddings for the set loss. Besides, ISTR concurrently conducts detection and segmentation with a recurrent refinement strategy, which provides a new way to achieve instance segmentation compared to the existing top-down and bottom-up frameworks. Benefiting from the proposed end-to-end mechanism, ISTR demonstrates state-of-the-art performance even with approximation-based suboptimal embeddings. Specifically, ISTR obtains a 46.8/38.6 box/mask AP using ResNet50-FPN, and a 48.1/39.9 box/mask AP using ResNet101-FPN, on the MS COCO dataset. Quantitative and qualitative results reveal the promising potential of ISTR as a solid baseline for instance-level recognition. Code has been made available at: https://github.com/hujiecpp/ISTR.
Learning Multi-Granular Hypergraphs for Video-Based Person Re-Identification
Apr 30, 2021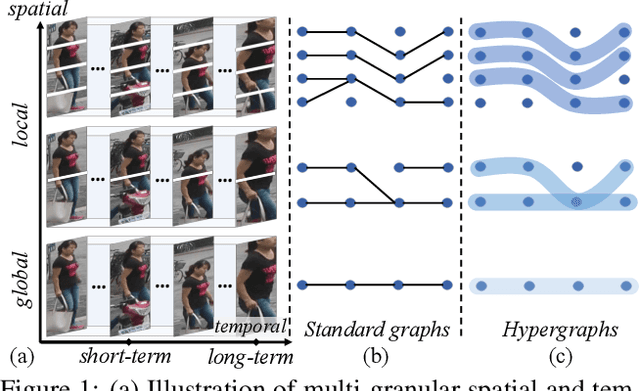
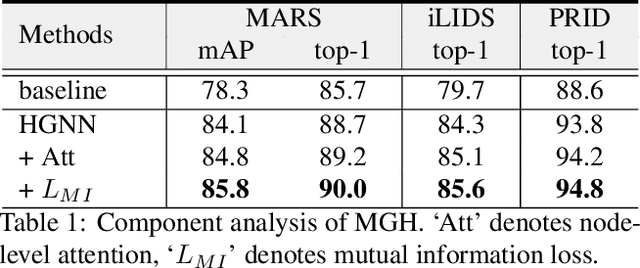
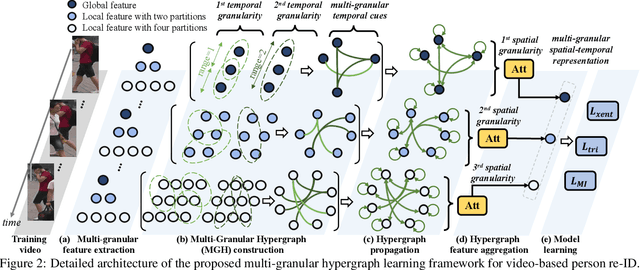
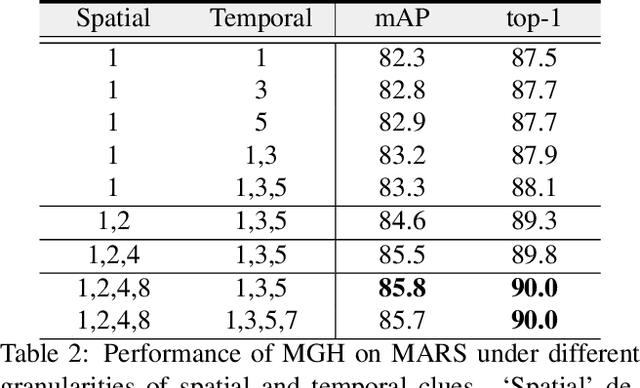
Video-based person re-identification (re-ID) is an important research topic in computer vision. The key to tackling the challenging task is to exploit both spatial and temporal clues in video sequences. In this work, we propose a novel graph-based framework, namely Multi-Granular Hypergraph (MGH), to pursue better representational capabilities by modeling spatiotemporal dependencies in terms of multiple granularities. Specifically, hypergraphs with different spatial granularities are constructed using various levels of part-based features across the video sequence. In each hypergraph, different temporal granularities are captured by hyperedges that connect a set of graph nodes (i.e., part-based features) across different temporal ranges. Two critical issues (misalignment and occlusion) are explicitly addressed by the proposed hypergraph propagation and feature aggregation schemes. Finally, we further enhance the overall video representation by learning more diversified graph-level representations of multiple granularities based on mutual information minimization. Extensive experiments on three widely adopted benchmarks clearly demonstrate the effectiveness of the proposed framework. Notably, 90.0% top-1 accuracy on MARS is achieved using MGH, outperforming the state-of-the-arts. Code is available at https://github.com/daodaofr/hypergraph_reid.
Learning Multi-Attention Context Graph for Group-Based Re-Identification
Apr 29, 2021

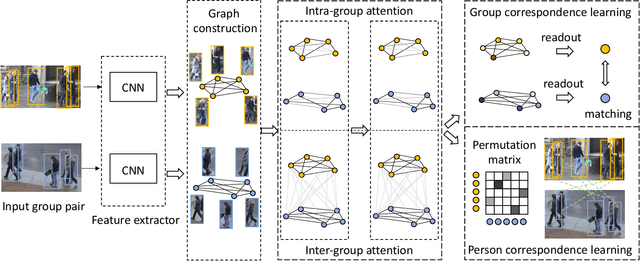

Learning to re-identify or retrieve a group of people across non-overlapped camera systems has important applications in video surveillance. However, most existing methods focus on (single) person re-identification (re-id), ignoring the fact that people often walk in groups in real scenarios. In this work, we take a step further and consider employing context information for identifying groups of people, i.e., group re-id. We propose a novel unified framework based on graph neural networks to simultaneously address the group-based re-id tasks, i.e., group re-id and group-aware person re-id. Specifically, we construct a context graph with group members as its nodes to exploit dependencies among different people. A multi-level attention mechanism is developed to formulate both intra-group and inter-group context, with an additional self-attention module for robust graph-level representations by attentively aggregating node-level features. The proposed model can be directly generalized to tackle group-aware person re-id using node-level representations. Meanwhile, to facilitate the deployment of deep learning models on these tasks, we build a new group re-id dataset that contains more than 3.8K images with 1.5K annotated groups, an order of magnitude larger than existing group re-id datasets. Extensive experiments on the novel dataset as well as three existing datasets clearly demonstrate the effectiveness of the proposed framework for both group-based re-id tasks. The code is available at https://github.com/daodaofr/group_reid.